Apache kafka是一个分布式消息发布订阅系统,可以处理大量的数据,并且能够将消息从一个端点传递到另一个端点。Kafka适合离线和在线消息消费(日常使用当中还是实时在线消息),消息可以保留在磁盘上,并在集群内复制以防止数据丢失(如果读到500时断电了,来电后从501继续读,防止数据丢失,也不会继续读前500条)
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能、低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。为了同时搞定在线应用(消息)和离线应用(数据文件、日志)kafka就出现了
可靠性:kafka是分布式、分区、复制和容错的
可扩展性:kafka消息传递系统轻松缩放,无需停机
耐用性:kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的
高性能:kafka对于发布和订阅消息都具有高吞吐量,kafka每秒可以生产约25万消息(50MB),每秒处理55万消息(110MB)
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份,防止数据丢失
kafka的使用场景:
日志收集:一个公司可以用kafka收集各种服务的log,可以通过logstash(占用内存小)或flume(占用内存大)采集,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等
消息系统:解耦和生产者和消费者、缓存消息等
用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘
运营指标:kafka也经常用来记录运营监控数据,包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
流式处理:比如spark和streaming和storm
时间源
什么是消息队列?

什么是topic、brokers、producer、consumer?
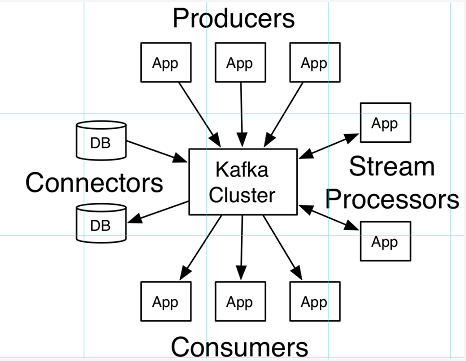
Kafka中的术语
broker:中间的kafka cluster,存储消息,是由多个server组成的集群
topic:kafka给消息提供的分类方式,broker用来存储不同topic的消息数据
producer:往broker中某个topic里面生产数据
consumer:从broker中某个topic获取数据
topic:属于特定类型的消息流称为topic,数据存储在topic中,topic可以理解为一个表
Partition(分区):topic可能有许多分区,因此它可以处理任意数量的数据,如果一个分区被干掉了,其他的分区还在,数据没有完全丢失
Partition offset(分区偏移):每个分区消息具有称为offset的唯一序列标识
Brokers(经纪人):每个kafka实例(server),一台kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以容纳多个topic
Producers(生产者):生产者是发送给一个或多个kafka主题的消息的发布者,生产者向kafka经纪人发送数据,每当生产者将消息发布给代理时,代理只需将消息附加到最后一个段文件,实际上该消息将被附加到分区,生产者还可以向他们选择的分区发送消息
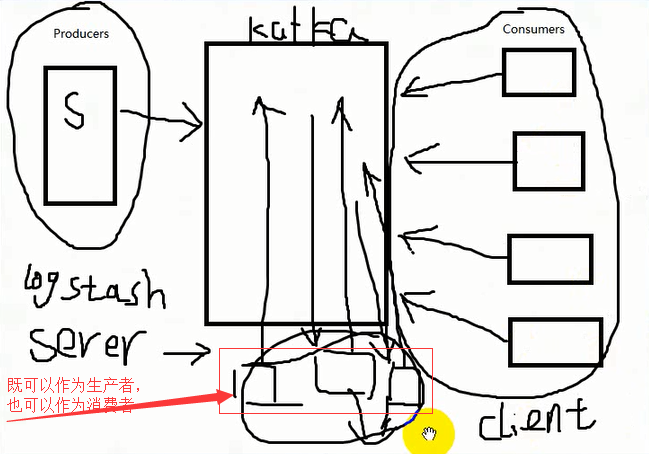
生产者向kafka推送数据,消费者来消费
Consumers(消费者):Consumers从经纪人处读取数据,消费者订阅一个或多个主题,并通过从代理中提取数据来使用已发布的消息
Consumer Group:一个Consumer Group包含多个consumer,这个是预先在配置文件中配置好的,各个consumer(consumer线程)可以组成一个组(Consumer Group),partition中的每个message只能被组(Consumer Group)中的一个consumer(consumer线程)消费,如果一个message可以被多个consumer(consumer线程)消费的话,那么这些consumer必须在不同的组
kafka性能问题:
除磁盘io之外,我们还需要考虑网络io,这直接关系到kafka的吞吐量问题,kafka并没有提供太多高超的技巧,对于producer端,可以将消息buffer起来,当消息的条数达到一定阈值时,批量发送给broker
对于consumer端也是一样,批量fetch多条消息,不过消息量的大小可以通过配置文件来指定,对于kafka broker端似乎有个sendfile系统调用可以潜在的提升网络io的性能,将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换,其实对于producer、consumer和broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略,压缩需要消耗少量的CPU资源,不过对于kafka而言,网络io更应该需要考虑,可以将任何在网络上传输的消息都经过压缩,kafka支持gzip/snappy等多种压缩方式
kafka集群配置:
下载kafka安装包kafka_2.11-2.3.0,解压完成后将kafka_2.11-2.3.0目录改名为kafka,然后进入config目录,找到server.properties,vi一下修改,可以看到broker.id=0,等于别的数字也可以,添加port=9092,如果有就不用添加,log.dirs为kafka的地址,本机是log.dirs=/usr/lib/kafka/kafka-logs(kafka数据的存放地址,多个地址的话用逗号分隔,多个目录分布在不同的磁盘上可以提高读写性能),kafka下面没有kafka-logs这个目录,会自动生成这个目录,找到Zookeeper选项,可以看到zookeeper.connect=localhost:2181,将此改成zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183,不同的zookeeper端口用逗号隔开,然后保存退出,在kafka目录下执行nohup bin/kafka-server-start.sh config/server.properties &,出现如下内容:

光标下面没有[root@besttest kafka]#,证明kafka没有起来,可能是内存不足,可以用ps -ef|grep kafka或者tail -f nohup.out看一下,如果kafka起来以后,可以执行下面的操作,[root@besttest kafka]#bin/kafka-topics.sh --zookeeper 192.168.1.10:2181 --list
测试kafka连接的命令:
kafka-console-producer.sh --broker-list localhost:9092 --topic test 生产者发送消息,消费者可以收到
kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning