前言
哈喽大家周二好,上次咱们说到了实体与值对象的简单知识,相信大家也是稍微有些了解,其实实体咱们平时用的很多了,基本可以和数据库表进行联系,只不过值对象可能不是很熟悉,值对象简单来说就是在DDD领域驱动设计中,为了更好的展示领域模型之间的关系,制定的一个对象,它没有状态和标识,目的就是为了表示一个值。今天呢本来不想说聚合了,因为网上的资料已经铺天盖地,想着开始说领域服务和领域事件了,但是为了本系列的完整性,今天就简单的说一下聚合和聚合根的理解,,如果你已经很明白了,请指出我说的不足之处,以便可以让大家知道,如果你还不是很明白,请看过后思考以下几个问题,领域事件下次再说吧,这样也就完成了今天的头脑风暴:
1、什么是聚合?
2、聚合的作用是什么?
3、我们平时接触到聚合了么?
这里有一个小Code,大家先看看这三者都是属于什么(实体,值对象,聚合/聚合根):
public class Order { public Guid Id; public string OrderNo; public Address Address; public List<OrderItem> Items; //... } public class OrderItem { public string Id; public float Price; public Goods Goods; public int Count; //... } public class Goods { public string Id; public string Name; //... } public class Address { public string Id; public string Country; public string Province; //... }
零、今天完成蓝色区块部分
一、聚合的概念 —— 领域的核心
1、聚合的概念
在DDD领域驱动设计第一次被提出的时候,聚合的概念就随之而来了,在之前的文章中,我们说到了领域和子领域的划分,也说了限界上下文的定义,这些都是和我们平时以数据模型为中心所不同的概念,可能理解起来不是很容易,但是至少我们有了这个影子,想象着一个大的领域项目,根据业务来拆分成了多个子领域与上下文,可能不同的上下文中甚至有相似的概念,举个栗子就是,订单上下文有商品,物流上下文有货物,库存上下文有存货等等等等,这时候你会发现,其实他们都是指的同一个东西,只不过在不同的上下文中被人为的赋予了不同的概念,有的是实体(库存),有的是值对象(订单),但是它们又不是一个概念,因为他们属于不同的子领域。

这个时候,既然我们从大的方面已经对限界上下文进行分离整合,与之而来的肯定是领域模型的分离(我们肯定不能把每一个表放在一起,也不会把他们都一个个并列排开),那既然有分离肯定就是有聚合,这个时候,聚合就出来了,其实DDD提出聚合的概念是为了保证领域内对象之间的一致性问题,因为我们从上边也看到了,在不同的地方会存在调用关系,当然主要还是子领域内部相互调用,
比如创建一个订单,必然会生成订单详情,订单详情肯定会有商品信息,我们在修改商品信息的时候,肯定就不能影响到这个订单详情中的商品信息。再比如:用户在下单的时候,会选择一个地址作为邮寄地址,如果该用户立刻下另一个订单,并对自己个人中心的地址进行修改,肯定就不能影响刚刚下单的邮寄地址信息。
这个时候,聚合就有很强的作用,通过值对象保证了对象之间的一致性。我们平时在开发的时候,虽然没有用到DDD,肯定也是经常用到聚合,就比如上边的问题,撇开DDD不谈,就平时来说,你肯定不会把商品 id 直接绑定到订单详情表中,为外键的,不然会死得很惨。这个时候其实我们就有一些聚合的概念了,因为什么呢,下单的时候,我们关注订单领域模型,修改商品的时候,我们关注商品领域模型,这些就是我们说到的聚合,当然一个上下文会有很多聚合,而且聚合要尽可能的细分,那如何正确的区分聚合,以及以什么为基准,请往下看。
2、我们如何对聚合进行划分
1、哪些实体或值对象在一起才能够有效的表达一个领域概念。
比如:订单模型中,必须有订单详情,物流信息等实体或者值对象,这样才能完整的表达一个订单的领域概念,就比如文章开头中提到的那个Code栗子中,OrderItem、Goods、Address等
2、确定好聚合以后,要确定聚合根
比如:订单模型中,订单表就是整个聚合的聚合根。
/// <summary> /// 聚合根 Order /// </summary> public class Order : AggregateRoot { public Guid Id; public string OrderNo; public Address Address;//值对象 public List<OrderItem> Items;//实体集合 //... }
3、对象之间是否必须保持一些固定的规则。
比如:Order(一 个订单)必须有对应的客户邮寄信息,否则就不能称为一个有效的Order;同理,Order对OrderLineItem有不变性约束,Order也必须至少有一个OrderLineItem(一条订单明细),否则就不能称为一个有效的Order;
另外,Order中的任何OrderLineItem的数量都不能为0,否则认为该OrderLineItem是无效 的,同时可以推理出Order也可能是无效的。因为如果允许一个OrderLineItem的数量为0的话,就意味着可能会出现所有 OrderLineItem的数量都为0,这就导致整个Order的总价为0,这是没有任何意义的,是不允许的,从而导致Order无效;所以,必须要求 Order中所有的OrderLineItem的数量都不能为0;那么现在可以确定的是Order必须包含一些OrderLineItem,那么应该是通 过引用的方式还是ID关联的方式来表达这种包含关系呢?这就需要引出另外一个问题,那就是先要分析出是OrderLineItem是否是一个独立的聚合 根。回答了这个问题,那么根据上面的规则就知道应该用对象引用还是用ID关联了。
那么OrderLineItem是否是一个独立的聚合根呢?因为聚合根意 味着是某个聚合的根,而聚合有代表着某个上下文边界,而一个上下文边界又代表着某个独立的业务场景,这个业务场景操作的唯一对象总是该上下文边界内的聚合 根。想到这里,我们就可以想想,有没有什么场景是会绕开订单直接对某个订单明细进行操作的。也就是在这种情况下,我们 是以OrderLineItem为主体,完全是在面向OrderLineItem在做业务操作。有这种业务场景吗?没有,我们对 OrderLineItem的所有的操作都是以Order为出发点,我们总是会面向整个Order在做业务操作,比如向Order中增加明细,修改 Order的某个明细对应的商品的购买数量,从Order中移除某个明细,等等类似操作,我们从来不会从OrderlineItem为出发点去执行一些业 务操作;另外,从生命周期的角度去理解,那么OrderLineItem离开Order没有任何存在的意义,也就是说OrderLineItem的生命周 期是从属于Order的。所以,我们可以很确信的回答,OrderLineItem是一个实体。
4、聚合不要设计太大,否则会有性能问题以及业务规则一致性的问题。
对于大聚合,即便可以成功地保持事务一致性,但它可能限制了系统性能和可伸缩性。 系统可能随著时间可能会有越来越多的需求与用户,开发与维护的成本我们不应该忽视。
怎样的聚合才算是"小"聚合呢??
好的做法是使用根实体(Root Entity)来表示聚合,其中只包含最小数量的属性或值类型属性。哪些属性是所需的呢??简单的答案是:那些必须与其他属性保持一致的属性。
比如,Product聚合内的name与description属性,是需要保持一致的,把它们放在两个不同的聚合显然是不恰当的。
5、聚合中的实体和值对象应该具有相同的生命周期,并应该属于一个业务场景。
比如一个最常见的问题:论坛发帖和回复如何将里聚合模型,大家想到这里,联想到上边的订单和订单详情,肯定会peng peng的这样定义;
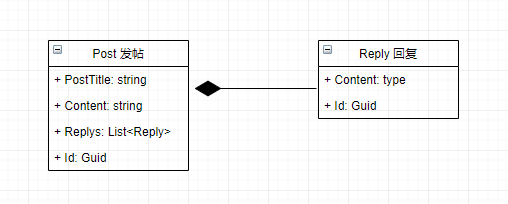
/// <summary> /// 聚合根 发帖 /// </summary> public class Post : AggregateRoot { public string PostTitle; public List<Reply> Reply;//回复 //... } /// <summary> /// 实体 回复 /// </summary> public class Reply : Entity { public string Content; //... }
这样初看是没有什么问题,很正常呀,发帖子是发回复的聚合根,回复必须有一个帖子,不然无效,看似合理的地方却有不合理。
比如,当我要对一个帖子发表回复时,我取出当前帖子信息,嗯,这个很对,但是,如果我对回复进行回复的时候,那就不好了,我每次还是都要取出整个带有很多回复的帖子,然后往里面增加回复,然后保存整个帖子,因为聚合的一致性要求我们必须这么做。无论是在场景还是在并发的情况下这是不行的。
如果帖子和回复在一个聚合内,聚合意味着“修改数据的一个最小单元”,聚合内的所有对象要看成是一个整体最小单元进行保存。这么要求是因为聚合的意义是维护聚合内的不变性,数据一致性;
仔细分析我们会发现帖子和回复之间没有数据一致性要求。所以不需要设计在同一个聚合内。
从场景的角度,我们有发表帖子,发表回复,这两个不同的场景,发表帖子创建的是帖子,而发表回复创建的是回复。但是订单就不一样,我们有创建订单,修改订单这两个场景。这两个场景都是围绕这订单这个聚合展开的。
所以我们应该把回复实体也单独作为一个聚合根来处理:
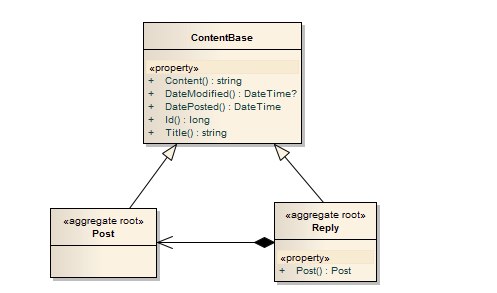
/// <summary> /// 内容 /// </summary> public class Content { public string Id; public DateTime DatePost; public string Contents; public string Title; //... } /// <summary> /// 聚合根 发帖 /// </summary> public class Post : AggregateRoot,ContentBase { public string Title; //... } /// <summary> /// 聚合根 回复 /// </summary> public class Reply : AggregateRoot,ContentBase { public Content Content; public Post Post;//帖子实体聚合根 //... }
当然这样的话,我们就不能通过帖子一次性全部把回复拿出来,我们就只能单写逻辑了,比如在应用层,但是这样不会对领域层造成失血,因为本来就不是领域的问题。
二、聚合是如何联系的
如何联系,在上文的代码中以及由体现了,这里用文字来说明下,具体的可以参考文中的代码
1、聚合根、实体、值对象的区别?
从标识的角度:
聚合根具有全局的唯一标识,而实体只有在聚合内部有唯一的本地标识,值对象没有唯一标识,不存在这个值对象或那个值对象的说法;
从是否只读的角度:
聚合根除了唯一标识外,其他所有状态信息都理论上可变;实体是可变的;值对象是只读的;
从生命周期的角度:
聚合根有独立的生命周期,实体的生命周期从属于其所属的聚合,实体完全由其所属的聚合根负责管理维护;值对象无生命周期可言,因为只是一个值;
2、聚合根、实体、值对象对象之间如何建立关联?
聚合根到聚合根:通过ID关联;
聚合根到其内部的实体,直接对象引用;
聚合根到值对象,直接对象引用;
实体对其他对象的引用规则:1)能引用其所属聚合内的聚合根、实体、值对象;2)能引用外部聚合根,但推荐以ID的方式关联,另外也可以关联某个外部聚合内的实体,但必须是ID关联,否则就出现同一个实体的引用被两个聚合根持有,这是不允许的,一个实体的引用只能被其所属的聚合根持有;
值对象对其他对象的引用规则:只需确保值对象是只读的即可,推荐值对象的所有属性都尽量是值对象;
3、如何识别聚合与聚合根?
明确含义:一个Bounded Context(界定的上下文)可能包含多个聚合,每个聚合都有一个根实体,叫做聚合根;
识别顺序:先找出哪些实体可能是聚合根,再逐个分析每个聚合根的边界,即该聚合根应该聚合哪些实体或值对象;最后再划分Bounded Context;
聚合边界确定法则:根据不变性约束规则(Invariant)。不变性规则有两类:1)聚合边界内必须具有哪些信息,如果没有这些信息就不能称为一个有效的聚合;2)聚合内的某些对象的状态必须满足某个业务规则;
1.一个聚合只有一个聚合根,聚合根是可以独立存在的,聚合中其他实体或值对象依赖与聚合根。
2.只有聚合根才能被外部访问到,聚合根维护聚合的内部一致性。
三、聚合的一些思考
1、优点
其实整篇文章都是在说的聚合的优点,这里简单再概况下:
聚合的出现,很大程度上,帮助了DDD领域驱动设计的全部普及,试想一下,如果没有聚合和聚合根的思维,单单来说DDD,总感觉不是很舒服,而且领域驱动设计所分的子领域和限界上下文都是从更高的一个层面上来区分的,有的项目甚至只有一个限界上下文,那么,聚合的思考和使用,就特别的高效,且有必要。
聚合设计的原则应该是聚合内各个有相互关联的对象之间要保持 不变性!我们平时设计聚合时,一般只考虑到了对象之间的关系,比如看其是否能独立存在,是否必须依赖与某个其他对象而存在。
2、担忧
我接触的DDD中的聚合根的分析设计思路大致是这样:1、业务本质逻辑分析;2、确认聚合对象间的组成关系;3、所有的读写必须沿着这些固有的路径进行。
这是一种静态聚合的设计思路。理论上讲,似乎没有什么问题。但实际上,因为每一个人的思路以及学习能力,甚至是专业领域知识的不同,会导致设计的不合理,特别是按照这个正确的路线设计,如果有偏差,就会达到不同的效果,有时候会事倍功半,反而把罪过强加到DDD领域驱动上,或者增加到聚合上,这也就是大家一直不想去更深层去研究实践这种思想的原因。
DDD本来就是处理复杂业务逻辑设计问题。我看到大家用DDD去分析一些小项目的时候,往往为谁是聚合根而无法达成共识。这说明每个人对业务认识的角度、深度和广度都不同,自然得出的聚合根也不同。试想,这样的情况下,领域模型怎么保持稳定。
不过这也许不是一个大问题,只要我们用心去经营,去学习,去沟通,一切都不是问题!
四、结语
今天简单的说了下聚合,明天就正式开始项目开发,到领域服务和领域事件了,不知道你能否回答文章开头的问题了呢?
/// <summary> /// 聚合根 Order /// 实体有标识ID,有生命周期和状态,通过ID进行区分 /// 聚合根是一个实体,聚合根的标识ID全局唯一,聚合根中的实体ID在聚合根内部唯一就行 /// 值对象主要就是值,与状态,标识无关,没有生命周期,用来描述实体状态。 /// </summary> /// 属性都是值对象 public class Order : AggregateRoot { public Guid Id; public string OrderNo;//值对象 public Address Address;//值对象 public List<OrderItem> Items;//实体集合 //... } /// <summary> /// 实体 OrderItem /// 属性都是值对象 /// </summary> public class OrderItem : Entity { public float Price; public Goods Goods; public int Count; //... } /// <summary> /// 值对象 Goods /// 属性都是值对象 /// </summary> public class Goods : ValueObject { public string Name; //... } /// <summary> /// 值对象 Address /// </summary> public class Address : ValueObject { public string Country; public string Province; //... } /// <summary> /// 值对象 /// </summary> public class ValueObject { } /// <summary> /// 领域实体 /// </summary> public class Entity { public string Id; } /// <summary> /// 聚合根的抽象实现类,定义聚合根的公共属性和行为 /// </summary> public abstract class AggregateRoot : Entity { }