Introduction
此篇论文获得了ICCV最佳学生论文奖,指导人是FAIR的He Kaiming大神:

众所周知,detector主要分为以下两大门派:
| - | one stage系 | two stage系 |
|---|---|---|
| 代表性算法 | YOLOv1、SSD、YOLOv2、YOLOv3 | R-CNN、SPPNet、Fast R-CNN、Faster R-CNN |
| 检测精度 | 低 | 高 |
| 检测速度 | 快 | 慢 |
这种鱼(speed)与熊掌(accuracy)不可兼得的局面一直成为Detection的瓶颈。
究其原因,就是因为one-stage受制于万恶的 “类别不平衡” 。
什么是“类别不平衡”呢?
详细来说,检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。
“类别不平衡”又如何会导致检测精度低呢?
因为bbox数量爆炸。
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。那为什么two-stage系就可以避免这个问题呢?
因为two-stage系有RPN罩着。
第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是 从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。
不过,其实two-stage系的detector也不能完全避免这个问题,只能说是在很大程度上减轻了“类别不平衡”对检测精度所造成的影响。
接着到了第二个stage时,分类器登场,在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖慢了。那为什么one-stage系无法避免该问题呢?
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
这个时候,He Kaiming带着他的《Focal Loss》出现了。
该篇文章指出,“类别不平衡”是one-stage detector在精度上逊于two-stage detector的病结所在。
那么,只要通过将原先训练 回归任务 惯用的 交叉熵误差 () 改为 FL (focal loss) 即可。
focal loss的标准公式非常简单:
也可以更复杂一点(论文中的实验即采用此公式):
本质改进点在于,在原本的 交叉熵误差 () 前面乘上了 这一权重。
我推算了一下乘上该权重所带来的影响:
| loss量级 | 量大的类别 (如background) | 量少的类别 |
|---|---|---|
| 被正确分类时的loss | 大幅 | 稍微 |
| 被错误分类时的loss | 适当 | 近乎保持不变 |
也就是说,一旦乘上了该权重,量大的类别所贡献的loss被大幅砍削,量少的类别所贡献的loss几乎没有多少降低。虽然整体的loss总量减少了,但是训练过程中量少的类别拥有了更大的话语权,更加被model所关心了。
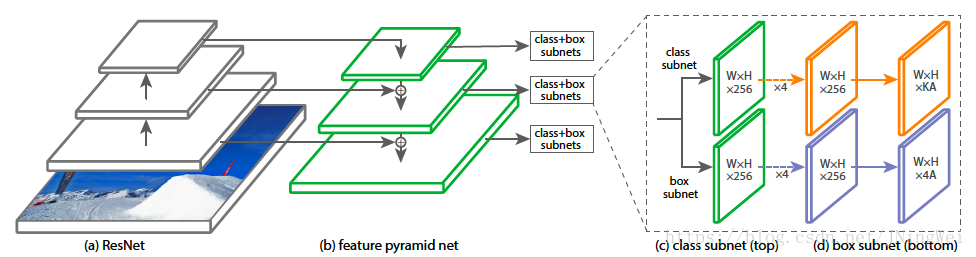
为此,FAIR还专门写了一个简单的one-stage detector来验证focal loss的强大。并将该网络结构起名RetinaNet:
文章也对于 的取值做了一番实验:
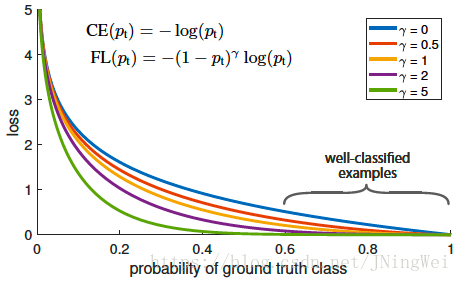
在实验中,发现 的取值组合效果最好。
Innovation
文章的两大贡献:
new cls loss:Focal Loss
new network:RetinaNet
RetinaNet = FPN + sub-network + FL
Note:
- RetinaNet简单而十分强大,以至于成为了当下最佳(accuracy/speed/complexity trade-off)的detector之一。
- RetinaNet的detector部分是两条平行pipe-line,且 设计相同 (除了尾部的output不一样) 但 参数不共享 (Faster R-CNN中第一层的参数是共享的) 。
- reg_pipe-line直接输出target,所以是采用了无分类的bbox regressior(Faster R-CNN是每个类各一个bbox regressor)。
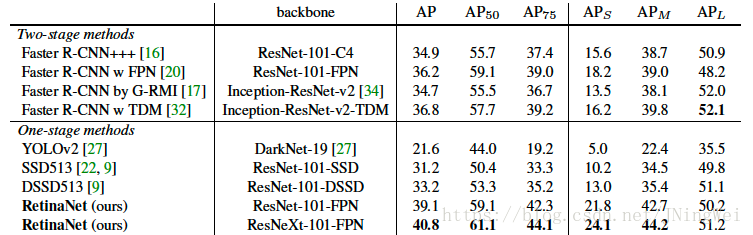
Result
新的detector标杆,state-of-the-art一词的新定义:
Thinking
focal loss的提出就像海面上的冰山。虽然看起来只是一个公式(冰山一角),但其实是来源于FAIR对于类别不平衡根本原因的深刻洞察和分析(海平面下的部分)。
指出问题的意义远大于解决问题。focal loss很简单,但却是它第一个洞察到了one-stage detector的accuracy不高的问题根源在于“类别不平衡”。
RetinaNet就是一个FPN-based的one-stage detector,靠着最后面的focal loss来解决由于过量background而引起的类别不平衡。
[1] Focal Loss for Dense Object Detection
[2] 度学习: 分类 目标函数 (交叉熵误差(CE) -> 焦点误差(FL))