转自:https://zhuanlan.zhihu.com/p/50217821
0 来源
标题:Gradient Harmonized Single-stage Detector
作者:Buyu Li, Yu Liu and Xiaogang Wang
机构:香港中文大学多媒体实验室
会议:AAAI2019
论文链接:
[1811.05181] Gradient Harmonized Single-stage Detector1 概述
one-stage的目标检测算法一直存在的问题是正负样本不均衡,简单和困难样本的不均衡。在one-stage算法中,负样本的数量要远远大于正样本,而且大多数负样本是简单样本(well-classified)。单个简单负样本的梯度虽然小,但是由于数量过大,会导致简单负样本主导模型的训练。在《focal loss》中通过大大降低简单样本的分类loss来平衡正负样本,但是设计的loss引入了两个需要通过实验来调整的超参数α和γ。
本篇论文从梯度的角度出发,提出gradient harmonizing mechanism(GHM)来解决样本不均衡的问题,GHM思想不仅可以应用于anchor的分类,同时也可以应用于坐标回归。
2 GHM
传统分类loss通常采用cross-entropy (CE),即
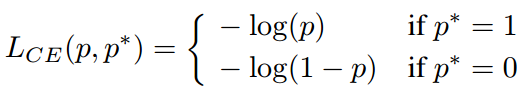
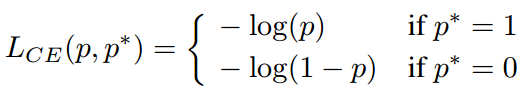
其中 为模型预测的分类概率,
为实际标签,
。用x表示模型的直接输出结果,则
。loss对于x求导即为
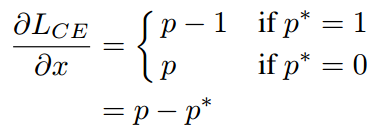
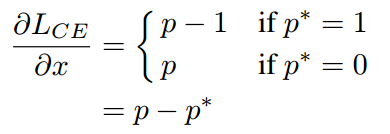
我们定义梯度的绝对值g(gradient norm)为
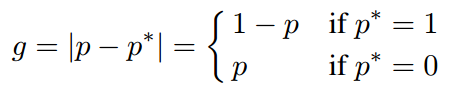
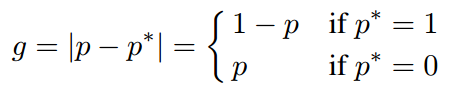
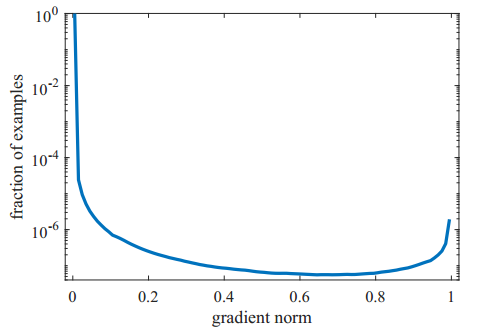
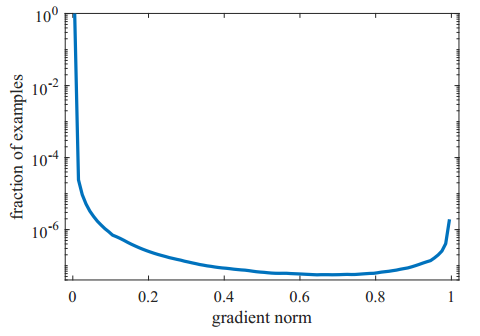
于是某个样本的g值大小就可以表现这个样本是简单样本还是困难样本。从一个收敛的检测模型中统计样本梯度的分布情况如下图一所示。从图中我们可以看出,与之前所想一样,简单样本的数量要远远大于困难样本。但同时也看出,一个已经收敛的模型中还是有相当数量的非常困难的样本,我们把这些非常困难的样本当作异常值(outliers),论文指出如果一个好的模型去学习这些异常样本会导致模型准确度降低。我的理解是,这些异常值就像数据的噪声一样,比如一个长得非常像狗的蛋糕,模型学习这些异常值反而会导致模型误入歧途。
为了解决这个问题,作者提出了GHM。首先定义梯度密度函数(Gradient density function)
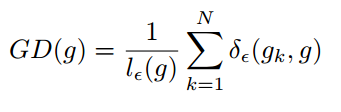
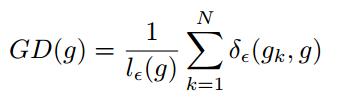
其中 表示第k个样本的梯度,而且
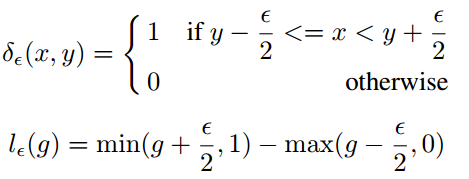
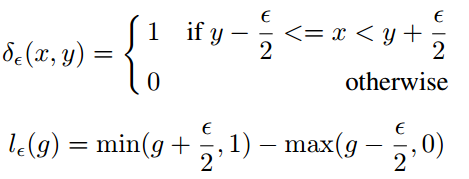
所以梯度密度函数GD(g)就表示梯度落在区域 的样本数量。再定义梯度密度协调参数(gradient density harmonizing parameter)
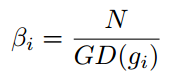
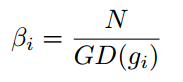
其中N表示总的样本数, 表示标准化。可以看出,梯度密度大的样本的权重会被降低,密度小的样本的权重会增加。于是把GHM的思想应用于分别应用于分类和回归上就形成了GHM-C和GHM-R。
3 GHM-C
把GHM应用于分类的loss上即为GHM-C,定义如下所示
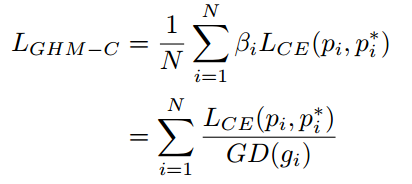
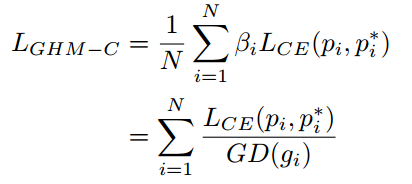
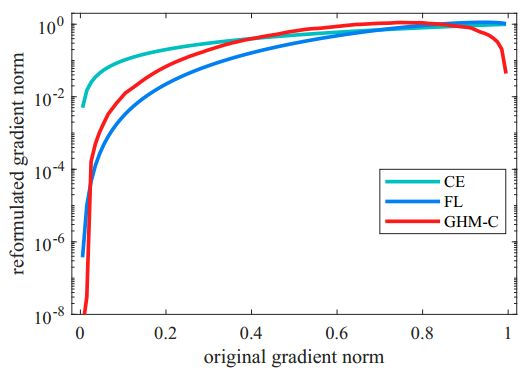
根据GHM-C的loss计算方式,候选样本中的简单负样本和非常困难的异常样本的权重都会被降低,即loss会被降低,对于模型训练的影响也会被大大减小。正常困难样本的权重得到提升,这样模型就会更加专注于那些更为有效的正常困难样本,以提升模型的性能。GHM-C loss对模型梯度的修正效果如下图二所示,横轴表示原始的梯度loss,纵轴表示修正后的。由于样本的极度不均衡,这篇论文中所有的图纵坐标都是取对数画的图。
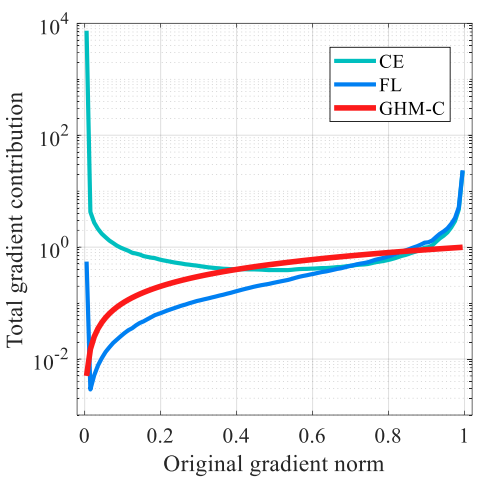
结合图一的梯度密度的分布,和图二单个样本的的梯度修正,我们可以得出整体样本对于模型训练梯度的贡献,如下图三所示。
但是考虑一下GHM的实际使用,本篇论文提出以下两个比较实用的方法。
(1)Unit Region Approximation(RU)
对GHM的时间复杂度进行分析,计算所有的样本的梯度密度分布的时间复杂度为 ,即使并行计算复杂度,每个计算单元复杂度也为N。而通过先排序再统计梯度的方式,最佳的排序算法实际复杂度为
,统计时间复杂度为
,但是这种方法并行收益不大。所以本篇论文通过简化求出近似的梯度密度分布来加快计算,实验表明,性能上只有极其微小损失。
这种方法的原理也比较简单,就是把X轴划分为M个区域,对于落在每个区域样本的权重采取相同的修正方式,类似于直方图。具体推导公式如下所示。X轴的梯度分为M个区域,每个区域长度即为 ,第j个区域范围即为
,用
表示落在第j个区域内的样本数量。定义ind(g)表示梯度为g的样本所落区域的序号,那么即可得出新的参数
和新的GHM-C loss函数。新的计算方法的时间复杂度为
。
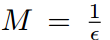
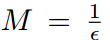
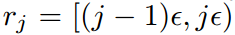
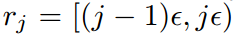
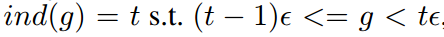
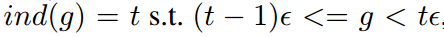
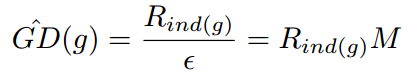
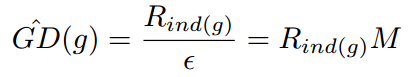
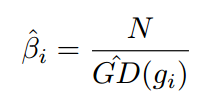
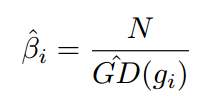
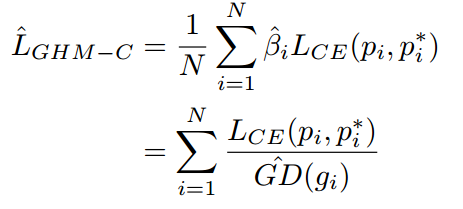
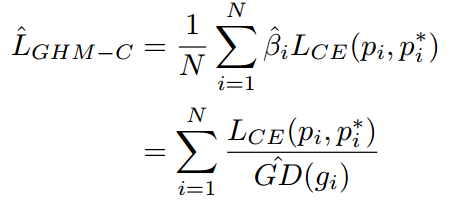
(2)Exponential moving average(EMA)
由于样本的梯度密度是训练时根据batch计算出来的,通常情况下batch较小,直接计算出来的梯度密度可能不稳定,所以采用滑动平均的方式处理梯度计算。我了解到的滑动平均常用于模型的loss优化器,比如SGD,RMSprop,Adam,论文中指出在BatchNormalization中也用到。公式如下所示。
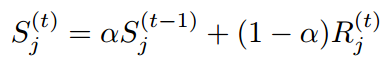
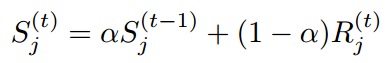
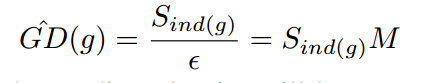
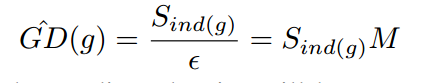
4 GHM-R
GHM的思想同样适用于anchor的坐标回归。坐标回归loss常用smooth_l1,如下所示
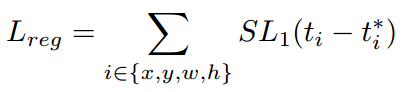
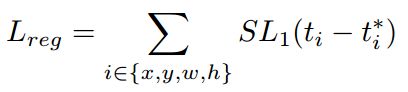
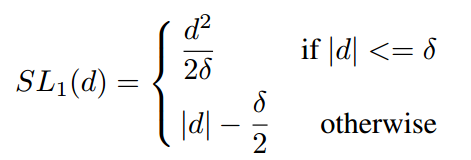
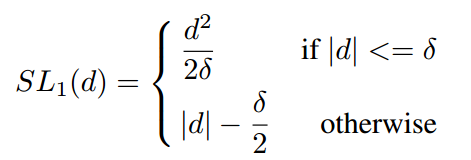
其中 表示模型预测坐标偏移量,
表示anchor实际坐标偏移量,
表示
的函数分界点,常取1/9。定义
,则
的梯度求导为
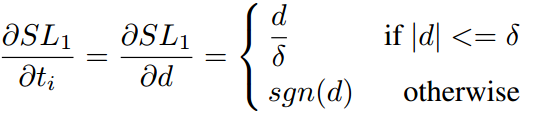
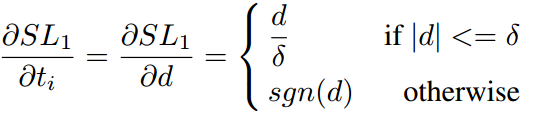
其中sgn表示符号函数。可以看出对于 的所有样本梯度绝对值都为1,这使我们无法通过梯度来区分样本,同时d理论上可以到无穷大,这也使我们不能使用上面提到的RU。所以论文对
进行变形,计算方法及梯度求导如下所示,
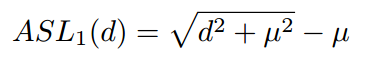
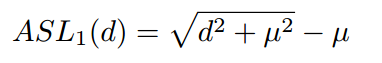
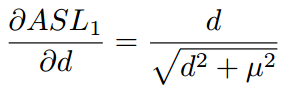
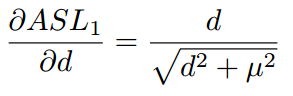
与
的性质很相似,当d较大时都近似为L1 loss,d较小是都近似为L2 loss,而且
的范围在[0,1),适合采用RU方法,在实际使用中,采用μ=0.02。
定义梯度的绝对值gr为
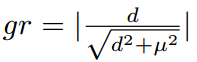
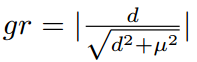
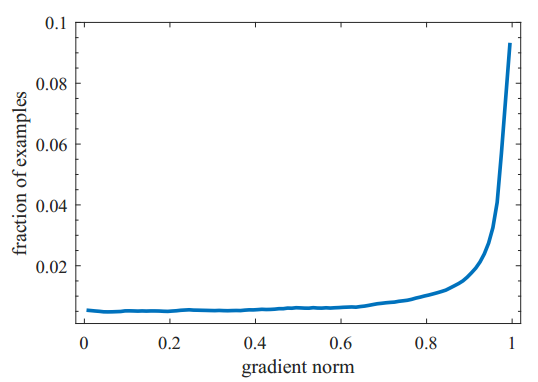
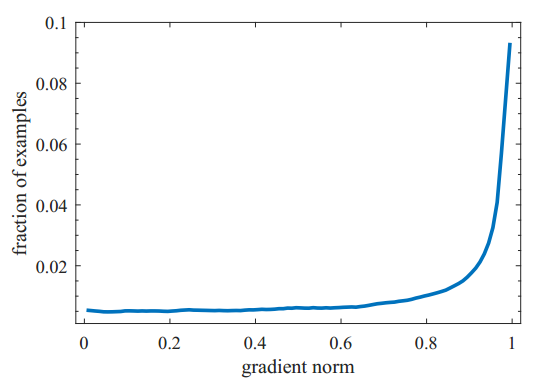
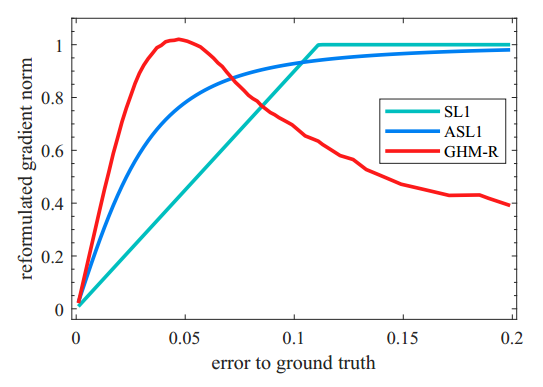
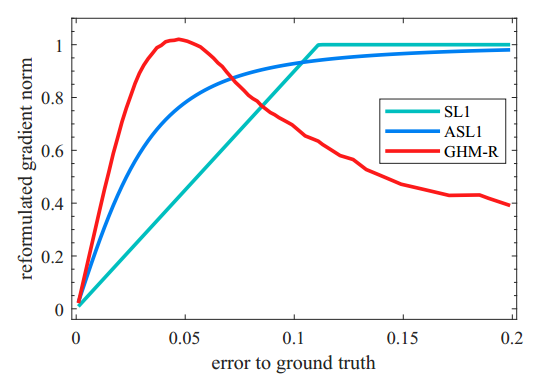
于是我们可以基于gr统计样本坐标回归偏移量的梯度分布情况如下图四所示。由于坐标回归都是正样本,所以简单样本的数量相对并不是很多。而且不同于简单负样本的分类对模型起反作用,简单正样本的回归梯度对模型十分重要。目标检测常用性能指标AP取0.5:0.95:0.05,简单样本的回归好坏会直接影响到模型的性能。但是同样也可以看出来,存在相当数量的异常样本的回归梯度值很大。
所以使用GHM的思想来修正loss函数,可以得到
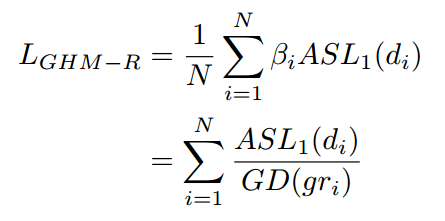
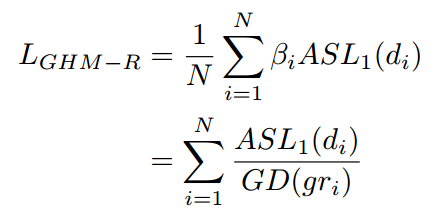
GHM-R loss对于回归梯度的修正如下图五所示。可以看出,GHM-R loss加大了简单样本和正常困难样本的权重,大大降低了异常样本的权重,使模型的训练更加合理。
5 实验结果
论文的对照实验以80k训练集加上35k验证集做为训练数据,5k验证集做为验证数据。最终的整体模型实验结果是在测试集上得出的。
实现细节
①基于RetinaNet的结构,模型为ResNet+FPN,anchor采用3种尺寸,3种比例,图像大小为800pixel。
②SGD with decay parameter of 0.0001 and a momentum parameter of 0.9
8 GPUs with 2 images on each GPU
train for 14 epochs with an initial learning rate of 0.01, which is decreased by a factor 0.1 at the 9th epoch and again at the 12th epoch
α = 0:75 for EMA and the results are insensitive to the exact value of α
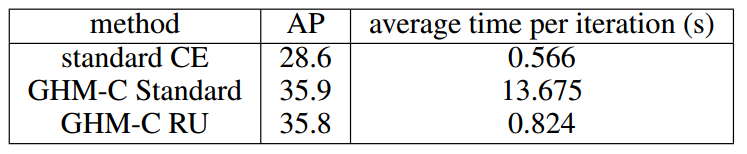
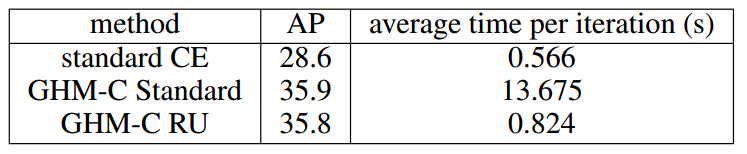
Numbers of Unit Region
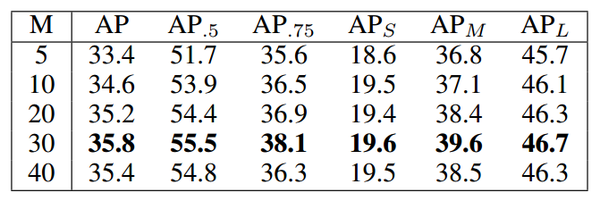
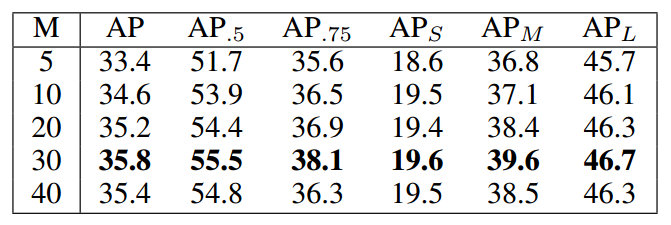
Speed
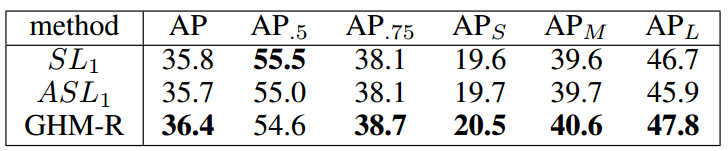
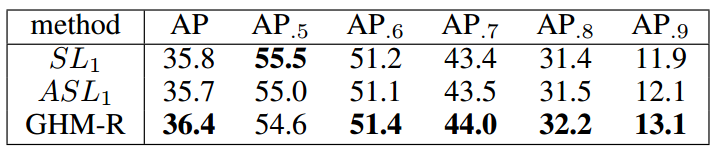
GHM-R vs Others
GHM-R vs Others



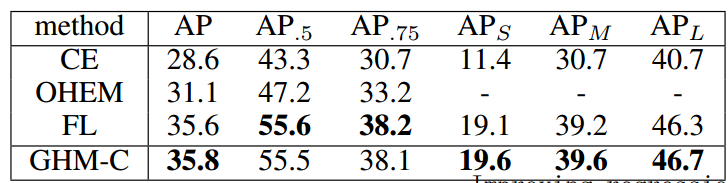
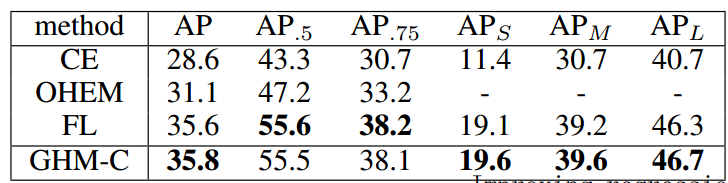
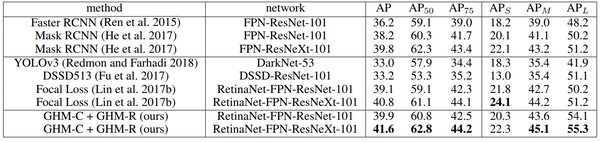
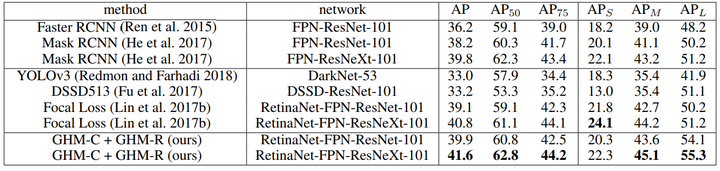
Main Result
个人总结
第一次写笔记,欢迎交流。论文公式较多,我自己都理解了一下,觉得还是比较好理解的,就懒得手打了,直接贴了很多原文。
这篇论文发表在AAAI2019,是我前两天逛arxiv偶然看到的。论文通过分析梯度分布,通过调节样本loss权重把极度不平衡样本分布平衡。我很少看这方面论文,觉得论文针对梯度的处理方式比较新颖,创新点很棒。关于正负样本不均衡、简单样本过多的论点基本大家都知道,不过论文中指出存在很多的outliers,我觉得很受用。很可惜的是论文给了code链接但是现在还是空的,渣渣不会自己写只想舔一下大神的代码。