一、泰坦尼克数据集
首先从csv读取数据
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers,models
'''
#==================================================================
# 一,构建数据管道
#==================================================================
'''
dftrain_raw = pd.read_csv("./data/titanic/train.csv")
dftest_raw = pd.read_csv("./data/titanic/test.csv")
dfraw = pd.concat([dftrain_raw,dftest_raw],axis=0)
def prepare_dfdata(dfraw):
dfdata = dfraw.copy()
dfdata.columns = [x.lower() for x in dfdata.columns]
dfdata = dfdata.rename(columns={'survived':'label'})
dfdata = dfdata.drop(['passengerid','name'],axis = 1)
for col,dtype in dict(dfdata.dtypes).items():
# 判断是否包含缺失值
if dfdata[col].hasnans:
# 添加标识是否缺失列
dfdata[col + '_nan'] = pd.isna(dfdata[col]).astype('int32')
# 填充,如果是数字,那么就添加这一列的平均值,否则空着
if dtype not in [np.object,np.str,np.unicode]:
dfdata[col].fillna(dfdata[col].mean(),inplace = True)
else:
dfdata[col].fillna('',inplace = True)
return(dfdata)
dfdata = prepare_dfdata(dfraw)
dftrain = dfdata.iloc[0:len(dftrain_raw),:]
dftest = dfdata.iloc[len(dftrain_raw):,:]
# 从 dataframe 导入数据
def df_to_dataset(df, shuffle=True, batch_size=4):
dfdata = df.copy()
if 'label' not in dfdata.columns:
ds = tf.data.Dataset.from_tensor_slices(dfdata.to_dict(orient = 'list'))
else:
labels = dfdata.pop('label')
ds = tf.data.Dataset.from_tensor_slices((dfdata.to_dict(orient = 'list'), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dfdata))
ds = ds.batch(batch_size)
return ds
ds_train = df_to_dataset(dftrain)
ds_test = df_to_dataset(dftest)

tensorflow只能处理数值类型的数据,如何将原始数据转换为神经网络的输入格式:使用特征列模块 tf.feature_column,在输入数据和模型之间搭建桥梁
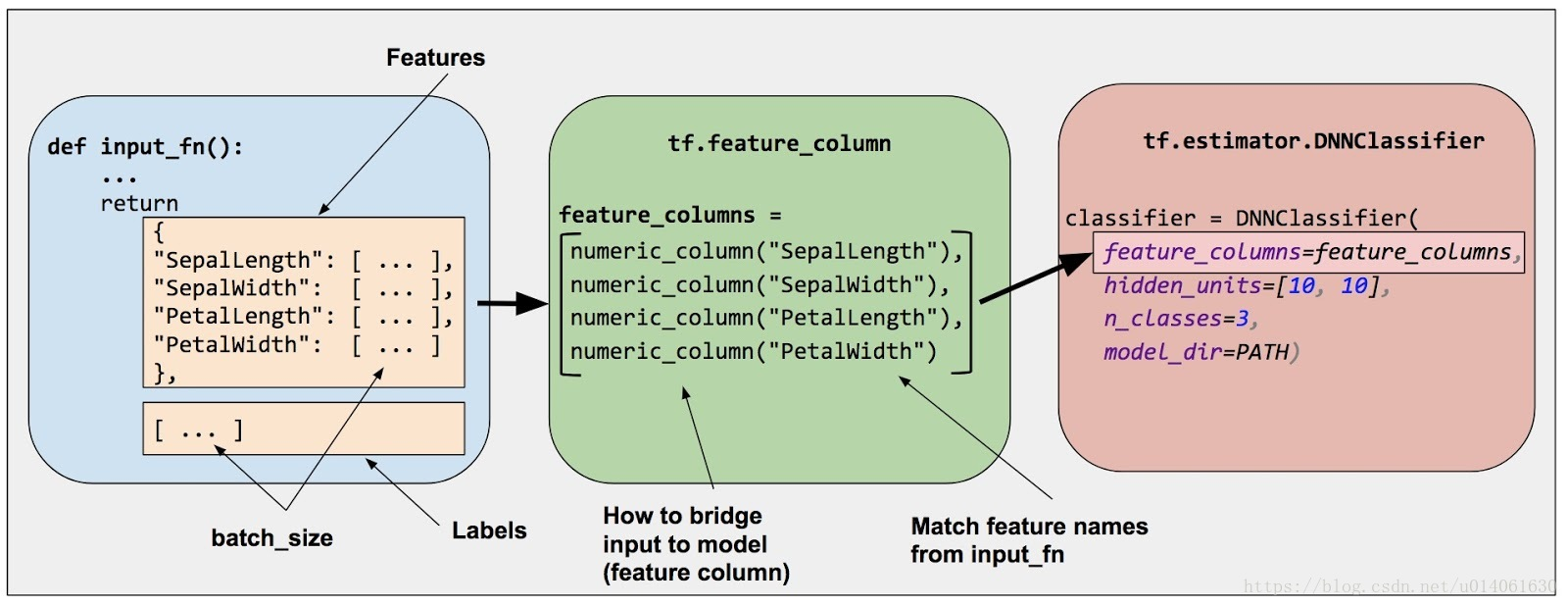
特征列完成以下等功能:
- 类别特征转换为ont-hot编码特征
- 连续特征转换为分桶特征
- 特征组合
二、定义特征列
2.1 数值特征使用 tf.feature_column.numeric_column得到数值列。
feature_columns = []
for col in ['age','fare','parch','sibsp'] + [
c for c in dfdata.columns if c.endswith('_nan')]:
feature_columns.append(tf.feature_column.numeric_column(col))
2.2 比如年龄数据,按区间进行划分,使用tf.feature_column.bucketized_column 得到分桶列。
不直接将一个数值直接传给模型,而是根据数值范围将其值分为不同的 categories。
此时,10个年龄间隔得到ont-hot列表长度为11,小于18岁的转换为[1,0,0,0,0,0,0,0,0,0,0]
age = tf.feature_column.numeric_column('age')
age_buckets = tf.feature_column.bucketized_column(age,
boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
feature_columns.append(age_buckets)
2.3 类别特征,使用tf.feature_column.categorical_column_with_vocabulary_list 转换为 one-hot编码
sex = tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_vocabulary_list(
key='sex',vocabulary_list=["male", "female"]))
feature_columns.append(sex)
2.4 当类别很多或者我们不知道有多少类的时候,我们不能一个一个的列出来,这时候就可以使用hash_bucket,第二个参数是我们想把这些数据分成多少类,
这个类别数和真实的类别数不一定是一样的,我们自己设置划分为多少类即可。
使用tf.feature_column.categorical_column_with_has_bucket 对 ticket列进行转换。
ticket = tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_hash_bucket('ticket',3))
feature_columns.append(ticket)
2.5 当类别很多的时候,借由lookup table的方式找寻对应的feature vector来表示。tf.feature_column.embedding_column
嵌入列可以看成keras.layers.Embedding层
cabin = tf.feature_column.embedding_column(
tf.feature_column.categorical_column_with_hash_bucket('cabin',32),2)
feature_columns.append(cabin)
2.6 多个特征组合为一个特征,组合列。tf.feature_column.crossed_column
pclass_cate = tf.feature_column.categorical_column_with_vocabulary_list(
key='pclass',vocabulary_list=[1,2,3])
crossed_feature = tf.feature_column.indicator_column(
tf.feature_column.crossed_column([age_buckets, pclass_cate],hash_bucket_size=15))
feature_columns.append(crossed_feature)
ps:此时 feature_columns 仅仅保存了一些特征列,需要在定义模型的时候把这些特征列作为输入层放到 tf.keras.layers.DenseFeatures
三、定义&训练模型
通过 layers.DenseFeatures(feature_columns) 完成了原始特征到模型输入特征的转换。
fit 阶段 之间输入 tf.data.Dataset 数据。
tf.keras.backend.clear_session()
model = tf.keras.Sequential([
layers.DenseFeatures(feature_columns), #将特征列放入到tf.keras.layers.DenseFeatures中!!!
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(ds_train,
validation_data=ds_test,
epochs=10)