默认情况下,hadoop官方发布的二进制包是不包含native库的,native库是用C++实现的,用于进行一些CPU密集型计算,如压缩。比如apache kylin在进行预计算时为了减少预计算的数据占用的磁盘空间,可以配置使用压缩格式。
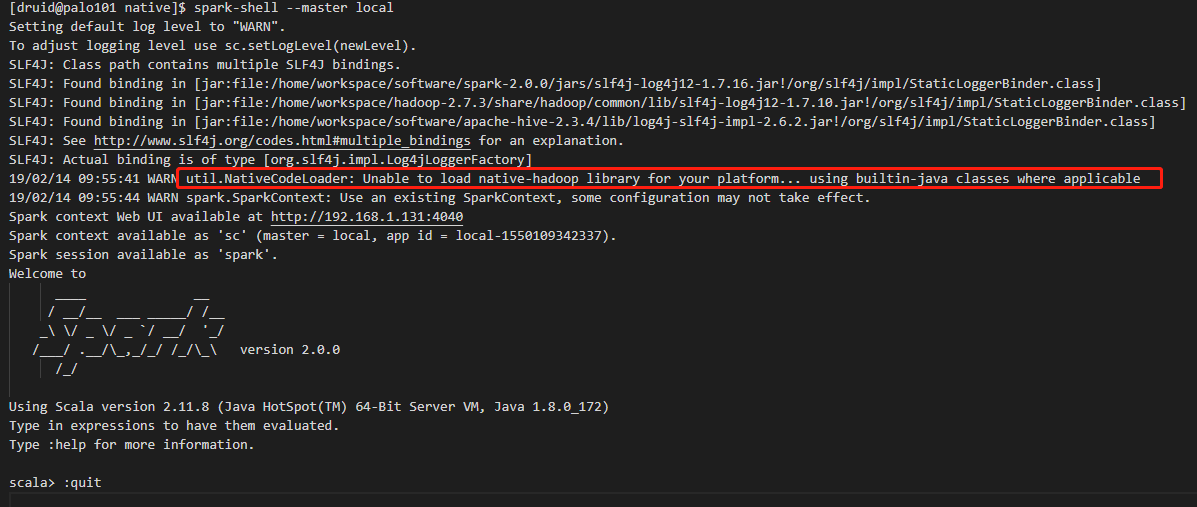
默认情况下,启动spark-shell,会有无法加载native库的警告:
19/02/14 09:55:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1. 编译hadoop源码
具体请参见本人的博文
或者在hadoop源码根目录下,执行ant compile-native 编译本地库(未亲测)
编译好中之后在{hadoop_source_root}/hadoop-dist/target/hadoop-{hadoop_version}/lib/native会存在编译好的native库文件,具体路径,请自己替换为匹配的版本。在本人的机器上显示如下,本人机器上用的是hadoop-2.7.3,所以路径为
{hadoop_source_root}/hadoop-dist/target/hadoop-2.7.3/lib/native
[druid@palo101 native]$ ls -lh total 4.6M -rw-rw-r-- 1 druid druid 1.2M Feb 6 21:53 libhadoop.a -rw-rw-r-- 1 druid druid 1.6M Feb 6 21:53 libhadooppipes.a lrwxrwxrwx 1 druid druid 18 Feb 6 21:53 libhadoop.so -> libhadoop.so.1.0.0 -rwxrwxr-x 1 druid druid 710K Feb 6 21:53 libhadoop.so.1.0.0 -rw-rw-r-- 1 druid druid 465K Feb 6 21:53 libhadooputils.a -rw-rw-r-- 1 druid druid 425K Feb 6 21:53 libhdfs.a lrwxrwxrwx 1 druid druid 16 Feb 6 21:53 libhdfs.so -> libhdfs.so.0.0.0 -rwxrwxr-x 1 druid druid 267K Feb 6 21:53 libhdfs.so.0.0.0
2. 部署编译好的hadoop native库
.删除hadoop部署环境下的native库(如果存在的话)
rm -rf $HADOOP_HOME/lib/native
复制编译好的native库到hadoop部署目录
scp -r {hadoop_source_root}/hadoop-dist/target/hadoop-2.7.3/lib/native {hadoop集群节点IP}:$HADOOP_HOME/lib
注意:复制到集群节点上.
3. 复制libjvm.so文件到$HADOOP_HOME/lib/native目录下
用ldd查看一下生成的native二进制文件的信息,发现libjvm.so找不到
[druid@palo101 native]$ sudo ldd $HADOOP_HOME/lib/native/libhadoop.so linux-vdso.so.1 => (0x00007ffe12bad000) libdl.so.2 => /lib64/libdl.so.2 (0x00007fee0127c000) libjvm.so => not found libc.so.6 => /lib64/libc.so.6 (0x00007fee00eba000) /lib64/ld-linux-x86-64.so.2 (0x00007fee016ba000)

所以我们在每台机器上执行下面脚本,把libjvm.so文件复制到hadoop native lib目录下
cp $JAVA_HOME/jre/lib/amd64/server/libjvm.so $HADOOP_HOME/lib/native
复制过去后,再执行一下下面的命令检查一下二进制native库
sudo ldd $HADOOP_HOME/lib/native/libhadoop.so
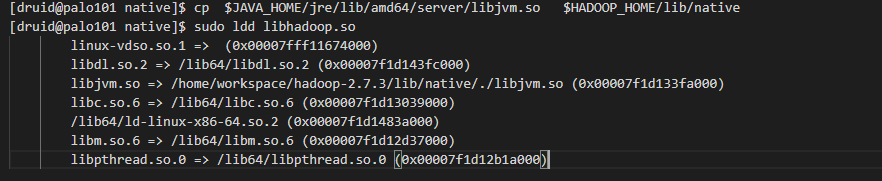
一切正常,说明部署已经没有问题了。下面就来做一下配置
4. 配置使用native库
4.1 hadoop启用native库
vim $HADOOP_HOME/etc/hadoop/core-site.xml
添加配置项
<property> <name>hadoop.native.lib</name> <value>true</value> <description>Should native hadoop libraries, if present, be used.</description> </property>
4.2 添加环境变量
vim /etc/profile
在末尾添加
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
也可以在shell窗口中执行这个命令,但是是临时生效,shell窗口关闭就失效了。
5. 在shell中验证是否成功

发现警告已经消失,成功使用了hadoop本地库.