前置说明:
本文旨在通过一个简单的执行计划来引申并总结一些SQL Server数据库中的SQL优化的关键点,日常总结,其中的概念介绍中有不足之处有待补充修改,希望大神勘误。
SQL语句如下:
SELECT <所需列> --列太多,不一一列出
FROM study1
INNER JOIN series1
ON (study1.study_uid_id = series1.study_uid_id) --连接条件1
INNER JOIN image1 image1
ON (series1.series_uid_id = image1.series_uid_id) --连接条件2
where ((study1.user_group &8) != 0) --过滤条件1
and (series1.modality) not in ('PR', 'KO', 'SR', 'AU') --过滤条件2
and study1.study_uid ='xxx' --过滤条件3
order by <排序列>; --列太多,不一一列出
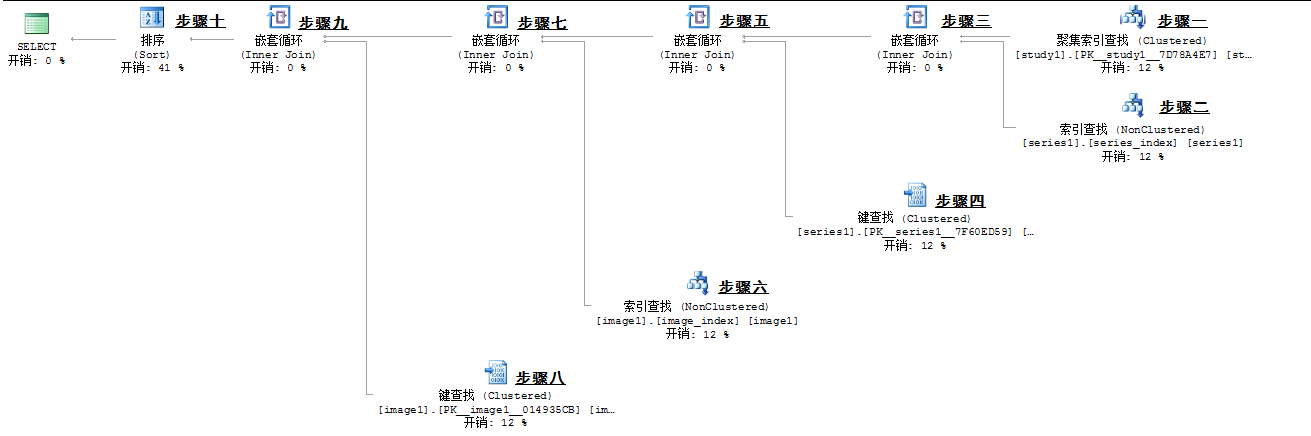
第一部分:执行计划怎么看?
1.从右往左看 + 从上往下看
同一行的执行计划步骤,右边的先执行。同一列的执行步骤,上边的先执行。
SQL Server优化器根据统计信息生成执行计划,由返回行数和统计信息直方图决定执行的先后顺序和表连接方式,但是最基本的一点:过滤条件先于与连接条件执行还是要遵守的。
表连接方式包含nested loop,merge join,hash join这三种,三种连接方式的区别有兴趣可以bing搜索查看,与Oracle的三种表连接方式一样,这里不再详述。
步骤一:根据统计信息发现3个where条件中【过滤条件3】的选择性最好,预估行数最少,于是放在执行计划最右。由于study_uid是主键,无需回表(即无需书签查找),因此实际上步骤一的聚集索引查找同时还兼顾了【((study1.user_group &8) != 0)】这个【过滤条件1】。
步骤一对应过滤条件1、3。
步骤二:这个index seek是根据步骤一得到的study_uid_id结合【连接条件1】,对series_index进行的索引查找,series_index是series表的study_uid_id这列的索引。
步骤三:步骤一和步骤二通过【连接条件1】进行nested loop合成一个中间表,这个中间表中有从series_index中拿到的series表的主键值,有了这个主键值我们就可以在步骤四中进行针对series的主键键查找。
步骤三对应连接条件1。
步骤四:这一步的目的就是通过步骤三得到的series表主键值,到series的聚集索引中找到主键对应的完整的行,在完整行记录中找到对应【过滤条件2】的行记录。
步骤四对应过滤条件2。
步骤五:步骤三、四通过nested loop合成一个中间表,这里的nested loop并不对应某个连接条件,只是纯粹的为了生成一个中间表。
步骤六:根据步骤五中间表里的series_uid_id值到image1表中进行索引查找,image_index就是image1.series_uid_id列的索引。
步骤七:步骤五、六进行nested loop生成中间表,这个中间表中含有image1表的主键值,这个主键值是执行步骤六时从image_index中拿到的。拿到这主键值我们就可以在步骤八中去取到最终我们需要的所有image1表的列了。
步骤七对应连接条件2。
步骤八:根据步骤七中间表中的image1主键值,到image1的主键聚集索引中去取我们需要的image1的列数据。
步骤九:步骤七、八进行nested loop生成最后的中间表。
步骤十:对步骤九中生成的中间表进行排序。
最终,我们就取到了需要的、排序好的所有数据。
2.查看每一步的详细信息
在出现错误的执行计划时,有时我们需要判断为什么优化器选错了执行计划,由于选错执行计划很有可能导致SQL语句变慢,因此搞清其中的原因是很有必要的。
将鼠标移到每一个执行计划node,会出现如下图所示的详细信息。
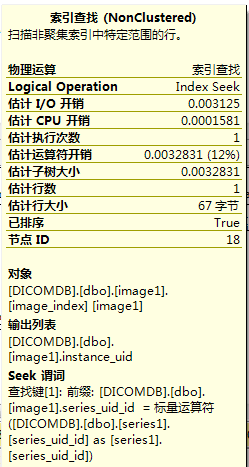
我们需要关注的主要有以下几点:
- 物理运算和逻辑运算:
1.表连接的物理运算方式:
1.嵌套循环
Logical Operation:nested loop
2.哈希连接
Logical Operation:hash join
3.合并连接
Logical Operation:merge join
2.索引访问的物理运算方式:
1.索引扫描
Logical Operation:index scan
2.索引查找
Logical Operation:index seek
3.聚集索引扫描
Logical Operation:cluster index scan
4.聚集索引查找
Logical Operation:cluster index seek
3.表访问的物理运算方式:
1.表扫描
Logical Operation:table scan
2.RID查找
Logical Operation:RID lookup
3.键查找
Logical Operation:key lookup。
(以前的bookmark lookup在SQL Server 2005之后被细分为RID lookup和key loopkup)
##关于RID LOOKUP和KEY LOOKUP的区别,一个是无主键一个是有主键时候出现的,RID LOOKUP的效率不如KEY LOOKUP,因此微软警告表一定要有主键##
4.其他的物理运算方式:
1.排序
Logical Operation:sort
2.流聚合和哈希匹配
Logical Operation:Aggregate。
在相应排序的流中,计算多组行的汇总值。group by子句出现时出现,一般配合min,max,avg,count,sum等组函数。哈希匹配适用于排序量较大时,优化器总是选择流聚合和哈希匹配两种物理运算中代价较小的一种。
3.计算标量
Logical Operation:Compute scalar,count(),avg(),sum()等计算组函数出现时出现,一般出现在流聚合物理运算之后,哈希匹配自带计算标量功能。
4.并行
Logical Operation:Parallel,与并行开销阈值和预估的执行时间有关。
- 估计行数
- 谓词(或seek 谓词,有时两者一起出现)
- 估计子树大小(即subtree cost和total subtree cost)
第二部分:怎么优化?
SQL Server的优化还是相对简单的,大致分为以下几种:
1.统计信息失真引起的
更新统计信息即可,方便起见应当创建定时更新全库统计信息的作业计划。
2.索引缺失或者索引过多或索引错误引起的
增删索引,或者更改联合索引顺序或者加包含列即可。
多表join时联合索引的存在对性能的提升很大,但是要保证有正确的联合索引顺序。
3.语句太烂引起的
类似not in,not exists,like '%xxx%'这些可能引发全表扫描的操作,具体情况具体改写吧......幺蛾子太多列不出来了。