执行的基本步骤
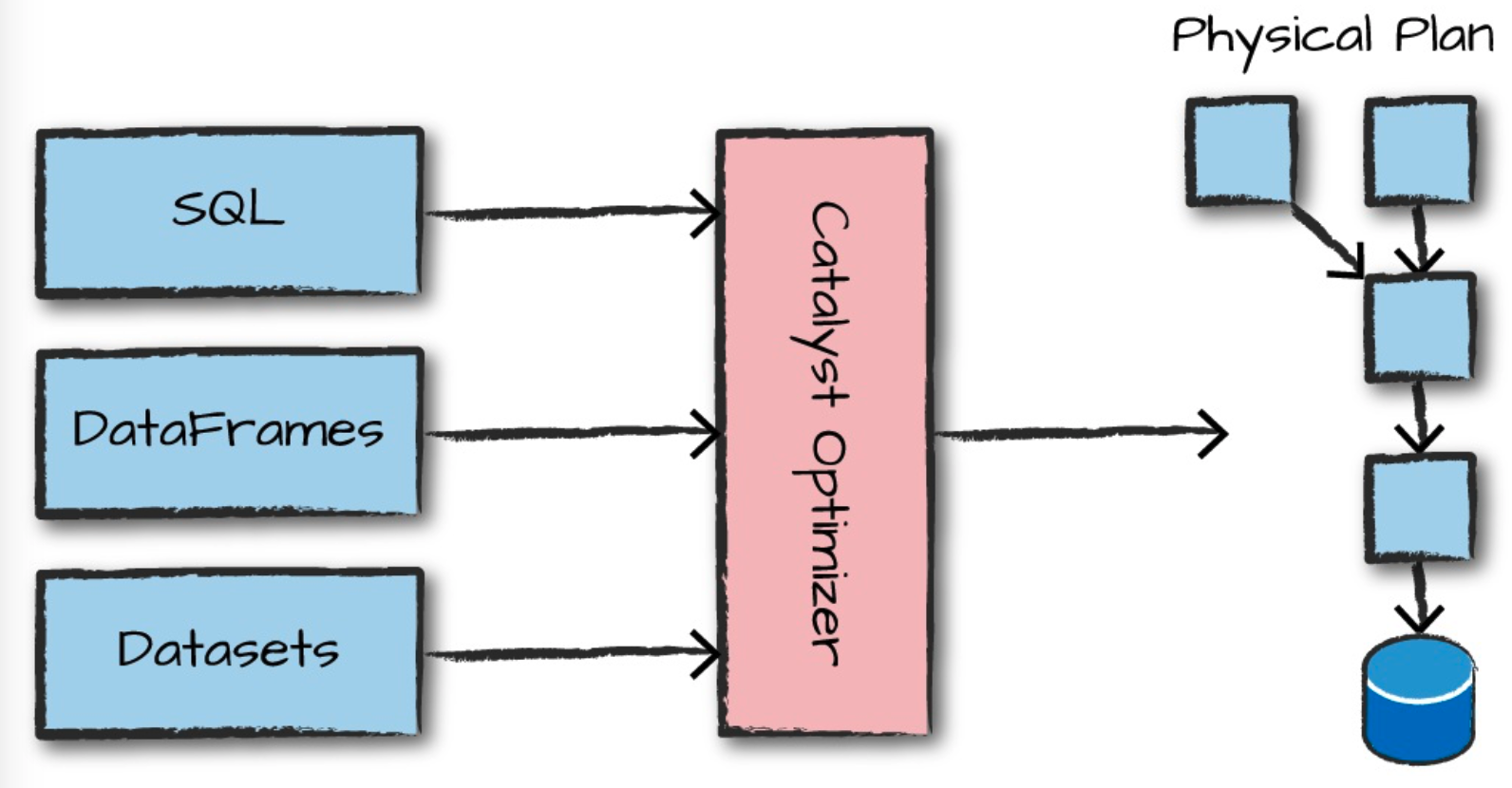
简单来说,Spark 对代码中Structured API的执行主要有以下几个步骤:
- (用户) 编写DataFrame/Dataset/SQL 代码
- 如果代码没有错误,Spark会将这些代码转换成逻辑计划(Logical Plan)
- Spark将生成的逻辑计划记过一系列优化,转换为物理计划(Physical Plan)
- Spark执行物理计划,即在集群上对RDD进行一系列操作。
我们可以通过console(如spark-shell)或者submit job(spark-submit)等方法将我们的代码提交到Spark。Spark使用 Catalyst Optimizer 优化器决定如果执行这些代码并生成相应的执行计划。
 |
逻辑执行计划
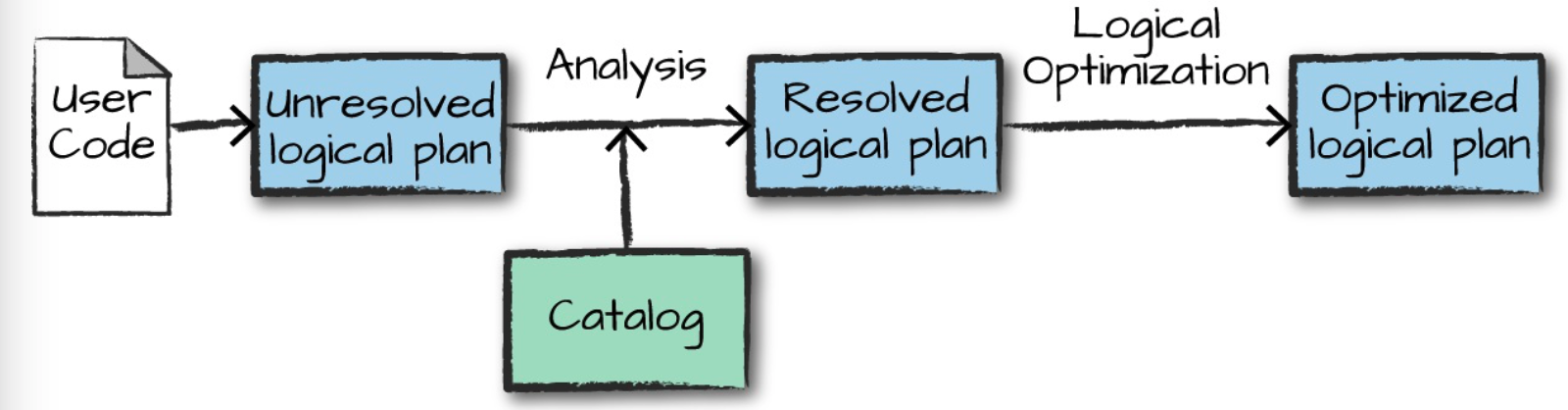
代码执行的第一阶段是将用户的代码转换成逻辑执行计划,如下图:
 |
|
The structured API logicial planning process
Credit: [Book]Spark - The Definitive Guide |
逻辑执行计划主要是一系列 抽象的转换过程,它并不涉及executors或者drivers,它仅仅是将用户的代码表达式转换成一个优化的版本。
用户的代码首先会被转换成 未解决的逻辑计划(unresolved logical plan) ,之所以将之称作 未解决的 , 是因为它并一定是正确的,它所引用到的表名或者列名可能存在,也可能不存在。
Spark之后会使用 calalog,一个含有所有table和DataFrame的元数据仓库,在 分析器(analyser) 中来解析校对所引用的表名或者列名。
假如 unresolved logical plan 通过了验证,这时的计划我们称之为 已解决的逻辑计划(resolved logical plan) 。它会传递到 Catalyst Optimizer 优化器,然后被经过一些列优化生成最优逻辑计划(Optimized logical plan)
物理执行计划
成功生成最优逻辑执行计划之后,Spark会开始将其转化为物理执行计划,即通过生成不同的物理执行策略,将其与 Cost Model 比较,选择最佳的执行计划,决定逻辑计划会如何在集群式执行,如下图:

|
|
The physical planning process
Credit: [Book]Spark - The Definitive Guide |
实际上,物理执行计划可以看做是一系列的RDD转换操作。这就是为什么我们可以经常听到有人将Spark被比作编译器 —— Spark可以替我们将DataFrame、Dataset和SQL中的查询编译成一些列的RDD转换过程。