一、主题
作为网易云音乐的忠实粉丝,在学习了python爬虫后,我想爬取网易云音乐的歌词、评论数和总的评论信息。分析流行音乐榜上的数据是否属实,从评论数和具体的评论信息可以获取很多相关性答案,因为好的歌曲,大部分听歌者都会给予比较真诚的评论,通过词频分析统计生成出现次数多的评论信息,再生成词云,直观得体现对歌曲的评价。音乐歌评信息量比较大,所以我选择了最近比较常听的薛之谦的热门歌曲。
网址:http://music.163.com/#
二、步骤解析
1.从薛之谦歌曲的热门歌单页面开始,http://music.163.com/#/artist?id=5781,获取所有歌曲的id信息和对应的歌曲名称
#获取歌的id和name
def getIdandName(z):
songerList=[];
soup = BeautifulSoup(z, 'html.parser')
for i in range(0, 50):
a = soup.select('.f-hide ')[0].select('a')[i].attrs['href'] # 获取url
id=a.split('=')[1];
name = soup.select('.f-hide ')[0].select('a')[i].text
songerList.append(getAllSong(id,name))
oneComment=getAllComment(id,name)
return songerList
2.通过传过来的id,获取某歌曲的详情页,接下来就获取评论总数,由于用BeautifulSoup获取到的html无显示评论数,这是因为网易云的评论采取的是异步传输。因此打开Chrome开发者工具f12观察,发现奥秘在一个名为“R_SO_4_553543014?csrf_token=”的POST请求中,如下图所示:
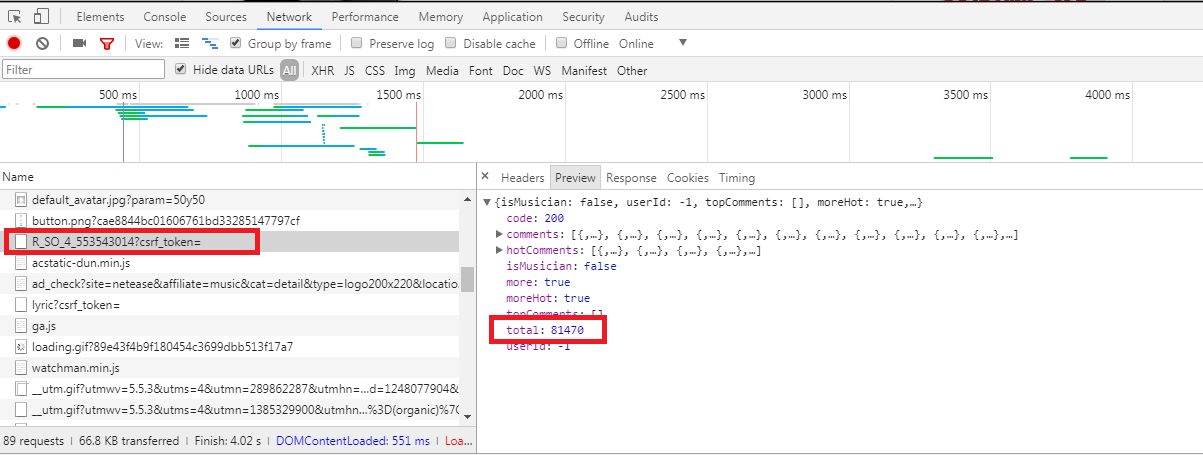
然而,通过该url,可看出R_SO_4后面跟着是歌曲的id信息,那post请求的参数是什么呢?如下图:
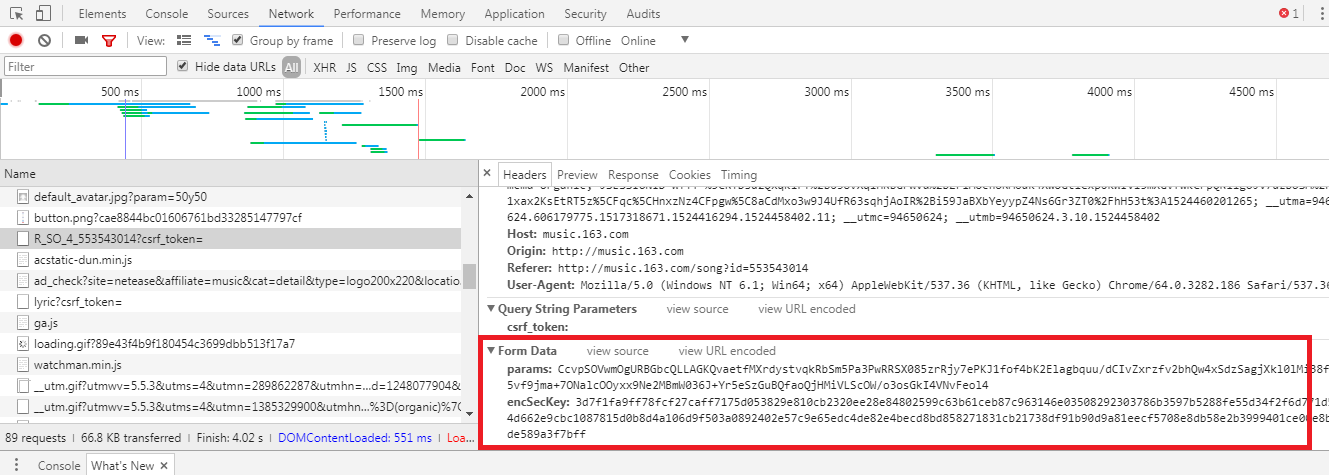
通过post请求,需要传递params和encSecKey两个参数,但是参数那连串是什么?通过了解,这是基于某种算法的加密,而解密算法又很复杂,没看懂。通过尝试和查询,得知歌曲详情页的首页的params和encSecKey是通用的,所以用相同的params和encSecKey可以获取第一页的评论,而评论总数在第一页也正好有,因此可以不用通过解密获取评论总数,代码如下:
#获取一首歌的总的评论数
def getCommentCount(id):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36"}
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_{}?csrf_token=".format(id)
data = {
"params": "nHfVBsNbW+WCrz7pAbdaq4uW2+4kADa+gNEfGWK7M5n36mWvsmGXsM2KzVUAeR62mhYlsSvc23I58Rf0dvg1Cglxuf5/l1wVRBCRROpjz9WuYSlWdiwXT/x45iud30RmjbTUsMSQuiehO6Ef3vHSdKWHma9pYm/eeYUF7IQ0hXI3HIz42NgwllBj4cy1XlOH",
"encSecKey": "0587c5b45f3b0771db2b3fe449e7dd9640ab56f679d73a9189096283e776e7a9f749630c6e0fa3f947778f1588b9ec71bd779279006f352e5804036909d5d772c9572c64db575bcce675fcc9055614f1c955abb798eed602cb43945748d8b0a9ecf293cde0ef523e63c3115a1a12b7113be447fba7947090f0d98d2c37cff72a"}
req = requests.post(url=url, headers=headers, data=data)
req.encoding = "utf-8"
comment = json.loads(req.text)
print(comment["total"])
return comment["total"]
3.获取歌曲的歌词,代码如下
#获取一首歌的歌词
def getLyric(id):
lyricUrl = 'http://music.163.com/api/song/lyric?id={}&lv=1&tv=1'.format(id)
r = requests.get(lyricUrl)
json_obj = r.text
j = json.loads(json_obj)
return j['lrc']['lyric']
4.接下来就是获取歌曲的所有评论了,由上面获取评论的信息可知,每个评论页都需要params和encSecKey参数,而这两个参数是被加密的,每个评论也的这两个参数都是不一样的,只能通过解密才能获取。而解密过程太繁琐,想学习也可以去学习下,这里就不做详细说明了。而我是通过另外的url获取,http://music.163.com/api/v1/resource/comments/R_SO_4_'+歌曲id+'?limit=20&offset=0' limit是一页显示的限制量,offset是偏移量,即如果第一页20,第二页的offset就得从20开始了,代码如下:
def getAllComment(id,name):
allpage = int(getAllPage(id))
for j in range(0,allpage):
k=j*20
lyricUrl = 'http://music.163.com/api/v1/resource/comments/R_SO_4_'+str(id)+'?limit=20&offset={}'.format(k)
headers = { # 请求头部
'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# post请求表单数据
data = {
'params': 'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ',
'encSecKey': '4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
req = requests.post(url=lyricUrl, headers=headers, data=data)
req.encoding = "utf-8"
comment = json.loads(req.text)
hot_commit = comment['comments'] # 获取json中的热门评论
#获取热门的第一条
for i in range(0, 20):
a = hot_commit[i]
b = a['content']
saveContent(b)
5.将获取到的歌曲id,歌曲名称,歌曲的歌词和评论总数存放在字典中,再将所有的字典放在列表,形成一个总的歌曲信息列表
#获取歌曲的所有信息保存到字典中
def getAllSong (id,name):
songers = {};
songers['id'] = id;
songers['name'] = name;
songers['count']=getCommentCount(id);
songers['lyric'] = getLyric(id);
return songers
songertotal=[]; songertotal=getIdandName (z)
6.将获取到的歌曲信息存放在excel表中
df=pandas.DataFrame(songertotal)
df.to_excel('xzq.xlsx',encoding='utf-8')
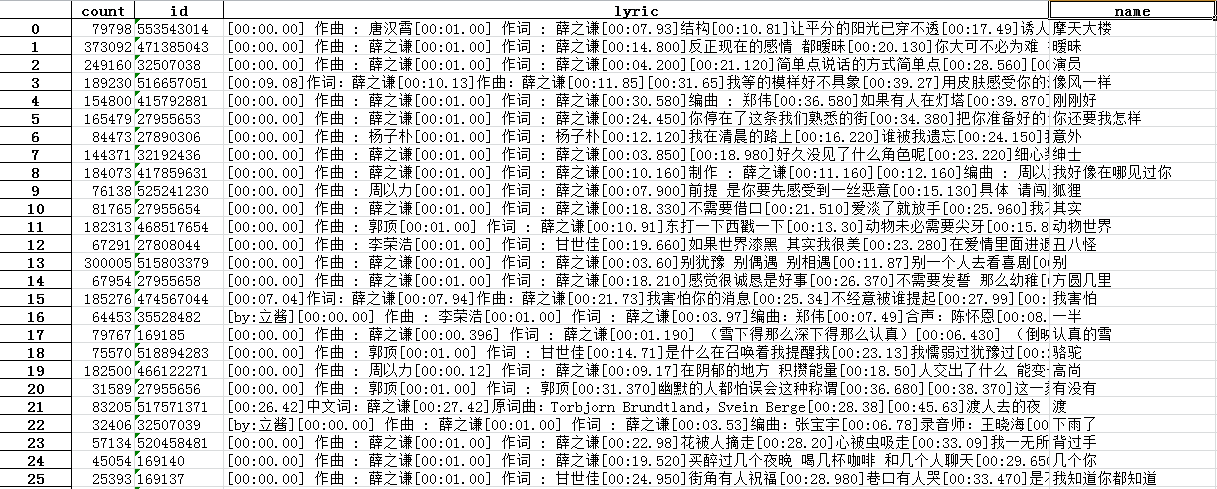
7.爬取所有的歌曲评论信息,存储在xzq.txt文件中,总共有10多万行
def saveContent(content):
f = open('xzq.txt','a',encoding='utf-8')
f.write('
'+content);
print(content)
f.close()

8.将该所有的歌曲评论信息,通过词频统计生成高频率词,放在文本中
def wordFrequency():
f = open('xzq.txt', 'r', encoding='utf-8')
result = f.read()
f.close();
str1 = ''',。‘’“”:;()!?、[ ]'''
dele = {'这', '在', '心', '种', '叫', '人', '么', 't', '人', '么', '行', '你', '尾',
'的', '虚', '
', '-', '出','我','一','了','有','他','是','个','歌','听','来','还','什','么','到',
'说','天','也','首','可','不','<<','>>'}
for i in str1:
result = result.replace(i, '')
tempwords = list(jieba.cut(result))
count = {}
words = list(set(tempwords) - dele)
for i in range(0, len(words)):
count[words[i]] = result.count(str(words[i]))
countList = list(count.items())
countList.sort(key=lambda x: x[1], reverse=True)
print(countList)
f = open('jieba.txt', 'a', encoding='utf-8')
cy={}
for i in range(500):
f.write(countList[i][0] + ':' + str(countList[i][1]) + '
')
cy[countList[i][0]]=countList[i][1]
f.close()
getWordColod(cy)
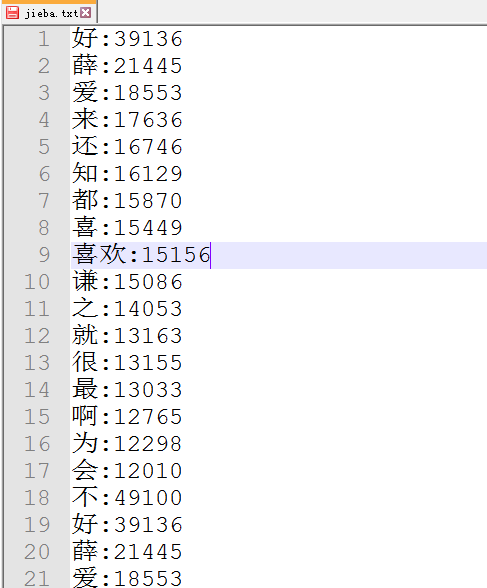
9.生成词云,我通过歌曲的评论的词频数和歌曲名+评论数生成了词云,代码、词云所用图片和词云截图如下:
#生成词云
def getWordColod(cy):
image = Image.open('./xzq1.png')
graph = np.array(image)
font = r'C:WindowsFontssimhei.TTF'
wc = WordCloud(font_path=font, background_color='White', max_words=50, mask=graph)
wc.generate_from_frequencies(cy)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()



三、遇到的问题和解决方法
1.首先遇到最大的问题是网易云对数据的安全保护措施太高,基本所有的数据都是加密的,因此需要找寻各种办法解决,这也是最花费时间的,我通过尝试和查阅资料,例如获取评论总数,因为只是需要第一页的评论总是,而第一页的params和encSecKey是通用的,所以随便找一首歌的params和encSecKey,拷贝过来,就可以将这两个参数传递过去,获取评论总数!而获取所有评论时,因为每个评论页的params和encSecKey都是不一样的,而评论页就有几千甚至几万页,解密又不会解,所有我找寻了其他的api接口,获取到了所有的评论。
2.在生成词云的时候,wordcloud总是导入不来,总是报错了,因为当时也没截图,所以也还原不了截图,我通过查阅资料,获取到一些解决办法,安装了wordcloud-1.4.1-cp36-cp36m-win_amd64.whl,但还是有问题,最后将python的环境换成了全局的,将所有的jar包通过全局下载全部重新下载一次,问题就解决了。具体步骤如下:
setting-->project interpreter-->show all-->add location 将路径改为全局路径

四、总代码
import requests
from bs4 import BeautifulSoup
import urllib.parse
import json
import openpyxl
import jieba
import pandas
from PIL import Image,ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
#保存进txt文件
def saveContent(content):
f = open('xzq.txt','a',encoding='utf-8')
f.write('
'+content);
print(content)
f.close()
#生成词云
def getWordColod(cy):
image = Image.open('./xzq1.png')
graph = np.array(image)
font = r'C:WindowsFontssimhei.TTF'
wc = WordCloud(font_path=font, background_color='White', max_words=50, mask=graph)
wc.generate_from_frequencies(cy)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()
#将保存的评论生成词频并生成词云
def wordFrequency():
f = open('xzq.txt', 'r', encoding='utf-8')
result = f.read()
f.close();
str1 = ''',。‘’“”:;()!?、[ ]'''
dele = {'这', '在', '心', '种', '叫', '人', '么', 't', '人', '么', '行', '你', '尾',
'的', '虚', '
', '-', '出','我','一','了','有','他','是','个','歌','听','来','还','什','么','到',
'说','天','也','首','可','不','<<','>>'}
for i in str1:
result = result.replace(i, '')
tempwords = list(jieba.cut(result))
count = {}
words = list(set(tempwords) - dele)
for i in range(0, len(words)):
count[words[i]] = result.count(str(words[i]))
countList = list(count.items())
countList.sort(key=lambda x: x[1], reverse=True)
print(countList)
f = open('jieba.txt', 'a', encoding='utf-8')
cy={}
for i in range(500):
f.write(countList[i][0] + ':' + str(countList[i][1]) + '
')
cy[countList[i][0]]=countList[i][1]
f.close()
getWordColod(cy)
#获取一首歌的总的评论数
def getCommentCount(id):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36"}
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_{}?csrf_token=".format(id)
data = {
"params": "nHfVBsNbW+WCrz7pAbdaq4uW2+4kADa+gNEfGWK7M5n36mWvsmGXsM2KzVUAeR62mhYlsSvc23I58Rf0dvg1Cglxuf5/l1wVRBCRROpjz9WuYSlWdiwXT/x45iud30RmjbTUsMSQuiehO6Ef3vHSdKWHma9pYm/eeYUF7IQ0hXI3HIz42NgwllBj4cy1XlOH",
"encSecKey": "0587c5b45f3b0771db2b3fe449e7dd9640ab56f679d73a9189096283e776e7a9f749630c6e0fa3f947778f1588b9ec71bd779279006f352e5804036909d5d772c9572c64db575bcce675fcc9055614f1c955abb798eed602cb43945748d8b0a9ecf293cde0ef523e63c3115a1a12b7113be447fba7947090f0d98d2c37cff72a"}
req = requests.post(url=url, headers=headers, data=data)
req.encoding = "utf-8"
comment = json.loads(req.text)
print(comment["total"])
return comment["total"]
#获取评论区总页数
def getAllPage(id):
allPage = int(str(getCommentCount(id)))/20-1;
return allPage;
#获取一首歌所有的的评论
def getAllComment(id,name):
allpage = int(getAllPage(id))
for j in range(0,allpage):
k=j*20
lyricUrl = 'http://music.163.com/api/v1/resource/comments/R_SO_4_'+str(id)+'?limit=20&offset={}'.format(k)
headers = { # 请求头部
'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# post请求表单数据
data = {
'params': 'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ',
'encSecKey': '4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
req = requests.post(url=lyricUrl, headers=headers, data=data)
req.encoding = "utf-8"
comment = json.loads(req.text)
hot_commit = comment['comments'] # 获取json中的热门评论
#获取热门的第一条
for i in range(0, 20):
a = hot_commit[i]
b = a['content']
saveContent(b)
#获取一首歌的歌词
def getLyric(id):
lyricUrl = 'http://music.163.com/api/song/lyric?id={}&lv=1&tv=1'.format(id)
r = requests.get(lyricUrl)
json_obj = r.text
j = json.loads(json_obj)
return j['lrc']['lyric']
#获取歌曲的所有信息保存到字典中
def getAllSong (id,name):
songers = {};
songers['id'] = id;
songers['name'] = name;
songers['count']=getCommentCount(id);
songers['lyric'] = getLyric(id);
return songers
#获取歌的id和name
def getIdandName(z):
songerList=[];
soup = BeautifulSoup(z, 'html.parser')
for i in range(0, 50):
a = soup.select('.f-hide ')[0].select('a')[i].attrs['href'] # 获取url
id=a.split('=')[1];
name = soup.select('.f-hide ')[0].select('a')[i].text
songerList.append(getAllSong(id,name))
oneComment=getAllComment(id,name)
return songerList
f=open('zjl.txt','r')
z = f.read();
f.close();
songertotal=[];
songertotal=getIdandName (z)
wordFrequency();
# 按照歌曲的点击与歌名生成词云
cy={}
for i in range(0,len(songertotal)):
a=songertotal[i]
cy[a['name']]=a['count']
getWordColod(cy)
print(songertotal)
#保存进excel
df=pandas.DataFrame(songertotal)
df.to_excel('xzq.xlsx',encoding='utf-8')
print(songertotal)
getWordColod(songertotal)
五、总结
通过这次的爬虫作业,使我对爬虫有更深刻的认识,虽然在这其中遇到了很多问题,但是也正是在这解决问题的过程中学会了很多。而这次的数据显示统计,使我更加了解薛之谦这个人,通过词云,我了解到他最受粉丝喜爱的歌曲是暧昧,评论的统计如"好“、”爱“、”喜欢“等高频率出现的词语,可以知道薛之谦的歌曲还是很深受大多数人的喜爱的。