背景
要想完全彻底的搞清楚 epoll 底层原理,我们有必要了解一下整个 IO 的发展历程,计算机内核的每一次的优化升级都是由于其自身的缺点进而发展出来的,从而促使底层系统函数的迭代升级,进而才会促使整个 IT 技术的升级迭代。这里不会讲太细节性的东西,例如:网络通信、CPU 中断等,这个有兴趣的同学可以下来更加细致的去了解,可以参考 epoll 三部曲来一步一步的了解:epoll 本质
从以下的各个阶段会通过图文解释来讲清楚整个 IO 历程,尽可能用简单易懂的方式来循序渐进的引导,从而是大家对 epoll 有个深刻的认知。
一、阻塞 IO 之 BIO
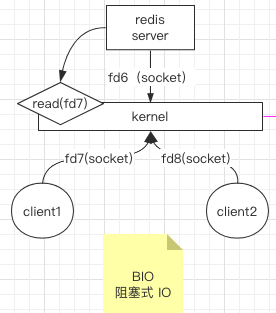
解释:fd 表示的是文件描述符,因为 linux 环境下一切结尾文件,它可以理解为 java 对象的引用,当 redis 服务启动的时候,会建立 socket 链接,如图中的 fd6,假设外部有两个客户端来连接 redis,则会与 redis 建立 socket 连接,分别为 fd7 和 fd8,当其中一个客户端发起读取操作,会将读取操作交给内核 kernel 来发起系统调用命令,系统调用命令 read 发起 read 请求将数据读取返后返回给客户端。后续基本上都是这个逻辑,就不会再重复解释了。
在这种 IO 模型的场景下,我们是给每一个客户端连接创建一个线程去处理它。不管这个客户端建立了连接有没有在做事,都要去维护这个连接,直到连接断开为止。创建过多的线程就会消耗过高的资源,以 Java BIO 为例
- BIO 是一个同步阻塞 IO
- 一个线程映射到一个轻量级进程(用户态中)然后去调用内核线程执行操作
- 对线程的调度,用户态和内核态切换以及上下文和现场存储等等都要消耗很多 CPU 和缓存资源
- 同步:客户端请求服务端后,服务端开始处理假设处理1秒钟,这一秒钟就算客户端再发送很多请求过来,服务端也忙不过来,它必须等到之前的请求处理完毕后再去处理下一个请求,当然我们可以使用伪异步 IO 来实现,也就是实现一个线程池,客户端请求过来后就丢给线程池处理,那么就能够继续处理下一个请求了
- 阻塞:inputStream.read(data) 会通过 recvfrom 去接收数据,如果内核数据还没有准备好就会一直处于阻塞状态
由此可见阻塞 I/O 难以支持高并发的场景,具体代码如下:
public static void main(String[] args) throws IOException { ServerSocket serverSocket = new ServerSocket(9999); // 新建一个线程用于接收客户端连接。伪异步 IO new Thread(() -> { while (true) { System.out.println("开始阻塞, 等待客户端连接"); try { Socket socket = serverSocket.accept(); // 每一个新来的连接给其创建一个线程去处理 new Thread(() -> { byte[] data = new byte[1024]; int len = 0; System.out.println("客户端连接成功,阻塞等待客户端传入数据"); try { InputStream inputStream = socket.getInputStream(); // 阻塞式获取数据直到客户端断开连接 while ((len = inputStream.read(data)) != -1) { // 或取到数据 System.out.println(new String(data, 0, len)); // 处理数据 } } catch (IOException e) { e.printStackTrace(); } }).start(); } catch (IOException e) { e.printStackTrace(); } } }).start(); }
见最上面的图,相应的问题就显而易见了:
二、非阻塞 IO 之 NIO
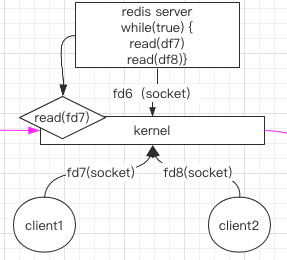
在 BIO 中只能监控一个 socket 且只能阻塞的问题,如何解决?简单易想的方案就是:我们改写一下,不让整个链路阻塞,那怎么实现呢?
让所有客户端排好队,内核来逐个循环来取,有指令执行了就直接执行就可以了,没有就接着下一个扫描,这样看起来就解决了每个客户端需要单独一个线程来阻塞等待执行了。
那么问题由来了:
虽然 NIO 解决了 BIO 中的阻塞问题,但是如果有 1000 个客户端连接,那么 NIO 采用轮询的方式就有问题了。因为从 用户态 到 内核态 频繁的切换,也会很耗性能,如果第一次循环第一个连接没有相应的读取指令,过去之后读取指令马上就来了,那还需要等到剩余的 999 次循环以及用户态和内核态的切换才能再次来到当前连接执行。如何才能降低这种资源的浪费与性能的提升呢?
三、多路复用 IO 之 select
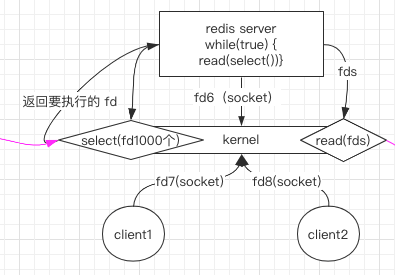
NIO 中我们知道频繁的 用户态 到 内核态 切换,导致性能和资源浪费严重,那我们是否可以不这么来回切换状态,那就有了多路复用之 select 了,即:
还是原来的 1000 个客户端连接,我们将用户态所有的连接打包统一交给内核,之后再由内核来统一循环,内核循环一圈后得到 要执行的 fds,再发送给 server,由 server 发起 用户态-->内核态的调用。这就是基本的多路复用策略。用一段伪代码来实现:
// 假设现目前获得了很多 serverSocket.accept(); 后的客户端连接 List<Socket> sockets; sockets = getSockets(); while (true) { // 阻塞,将所有的 sockets 传入内核让它帮我们检测是否有数据准备就绪 // n 表示有多少个 socket 准备就绪了 int n = select(sockets); for (int i = 0; i < sockets.length; i++) { // FD_ISSET 挨个检查 sockets 查看下内核数据是否准备就绪 if (FD_ISSET(sockets[i]) { // 准备就绪了,挨个处理就绪的 socket doSomething(); } } }
由此也能看出 select 的一些缺陷:
- 单进程能打开的最大文件描述符为 1024
- 监视 sockets 的时候需要将所有的 sockets 的文件描述符传入内核并且设置对应的进程,传入的东西太大了
- 内核同样也会一直在重复循环,然而其中也可能只有几个 fds 可用,导致内核一直很忙,这样的效率仍然不高。
四、多路复用 IO 之 poll
poll 跟 select 相似对其进行了部分优化,比如单进程能打开的文件描述符不受限制,底层是采用的链表实现。
五、多路复用 IO 终极 epoll
epoll 的出现相较于 select 晚了几年,它对 select,poll 进行了大幅度的优化。


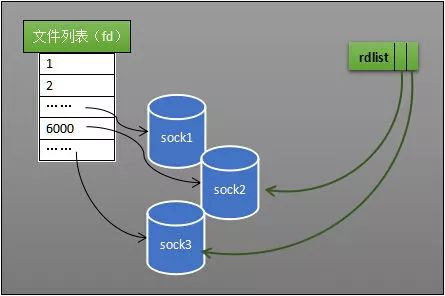
就上图说明,相较于 select 可以发现主要是多了一个 eventpoll(rdlist),之前的需要监视的 socket 都需要绑定一个进程,现在都改为指向了 eventpoll
它是什么呢,我们看下 epoll 实现的伪代码:
// 假设现目前获得了很多 serverSocket.accept(); 后的客户端连接 List<Socket> sockets; sockets = getSockets(); // 这里就是在创建 eventpoll int epfd = epoll_create(); // 将所有需要监视的 socket 都加入到 eventpoll 中 epoll_ctl(epfd, sockets); while (true) { // 阻塞返回准备好了的 sockets int n = epoll_wait(); // 这里就直接对收到数据的 socket 进行遍历不需要再遍历所有的 sockets // 是怎么做到的呢,下面继续分析 for (遍历接收到数据的 socket) { } }
解释:
epoll_create:当某个进程调用 epoll_create 方法时,内核会创建一个 eventpoll 对象。eventpoll 对象也是文件系统中的一员,和 socket 一样,它也会有等待队列。
创建一个代表该epoll的eventpoll对象是必须的,因为内核要维护“就绪列表”等数据,“就绪列表”可以作为eventpoll的成员。
epoll_ctl:创建epoll对象后,可以用 epoll_ctl 添加或删除所要监听的socket,内核会将 eventpoll 添加到这些 socket 的等待队列中。
当socket收到数据后,中断程序会操作eventpoll对象,而不是直接操作进程。eventpoll对象相当于是socket和进程之间的中介,socket的数据接收并不直接影响进程,而是通过改变eventpoll的就绪列表来改变进程状态。
epoll_wait:阻塞返回准备好了的 sockets
六、就绪队列
就绪队列就是下图的 rdlist 它是 eventpoll 的一个成员,指的是内核中有哪些数据已经准备就绪。这个是怎么做到的呢,当我们调用 epoll_ctl() 的时候会为每一个 socket 注册一个 回调函数,当某个 socket 准备好了就会 回调 然后加入 rdlist 中的,rdlist 的数据结构是一个双向链表。
总结
epoll 提升了系统的并发,有限的资源提供更多的服务较于 select、poll 优势总结如下:
- 内核监视 sockets 的时候不再需要每次传入所有的 sockets 文件描述符,然后又全部断开(反复)的操作了,它只需通过一次 epoll_ctl 即可
- select、poll 模型下进程收到了 sockets 准备就绪的指令执行后,它不知道到底是哪个 socket 就绪了,需要去遍历所有的 sockets,而 epoll 维护了一个 rdlist 通过回调的方式将就绪的 socket 插入到 rdlist 链表中,我们可以直接获取 rdlist 即可,无需遍历其它的 socket 提升效率(注意需记住:多路复用 + 消息回调 的方式)
最后我们考虑下 epoll 的适用场景:
只要同一时间就绪列表不要太长都适合。比如 Nginx 它的处理都是及其快速的,如果它为每一个请求还创建一个线程,这个开销情况下它还如何支持高并发。
netty
最后我们来看下 netty:
netty 也是采用的多路复用模型我们讨论在 linux 情况下的 epoll 使用情况,netty 要如何使用才能更加高效呢?
如果某一个 socket 请求时间相对较长比如 100MS 会大幅度降低模型对应的并发性,该如何处理呢,java 代码如下。
public class NIOServer { public static void main(String[] args) throws IOException { Selector serverSelector = Selector.open(); Selector clientSelector = Selector.open(); new Thread(() -> { try { // 对应IO编程中服务端启动 ServerSocketChannel listenerChannel = ServerSocketChannel.open(); listenerChannel.socket().bind(new InetSocketAddress(8000)); listenerChannel.configureBlocking(false); listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT); while (true) { // 一致处于阻塞直到有 socket 数据准备就绪 if (serverSelector.select() > 0) { Set<SelectionKey> set = serverSelector.selectedKeys(); Iterator<SelectionKey> keyIterator = set.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); if (key.isAcceptable()) { try { // (1) 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept(); clientChannel.configureBlocking(false); clientChannel.register(clientSelector, SelectionKey.OP_READ); } finally { keyIterator.remove(); } } } } } } catch (IOException ignored) { } }).start(); new Thread(() -> { try { while (true) { // 阻塞等待读事件准备就绪 if (clientSelector.select() > 0) { Set<SelectionKey> set = clientSelector.selectedKeys(); Iterator<SelectionKey> keyIterator = set.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); if (key.isReadable()) { try { SocketChannel clientChannel = (SocketChannel) key.channel(); ByteBuffer byteBuffer = ByteBuffer.allocate(1024); // (3) 面向 Buffer clientChannel.read(byteBuffer); byteBuffer.flip(); System.out.println(Charset.defaultCharset().newDecoder().decode(byteBuffer) .toString()); } finally { keyIterator.remove(); key.interestOps(SelectionKey.OP_READ); } } } } } } catch (IOException ignored) { } }).start(); } }
来分析下上面这段代码
-
用 serverSelector 来处理所有客户端的连接请求
-
用 clientSelector 来处理所有客户端连接成功后的读操作
-
1. 将 SelectionKey.OP_ACCEPT 这个操作注册到了 serverSelector 上面
相当于上述将的将我们去创建 eventpoll 并且将当前 serverSocket 进行监视并且注册的是 ACCEPT 建立连接这个事件,将当前 Thread 移除工作队列挂入 eventpoll 的等待队列
-
2. serverSelector.select() > 0 就是有 socket 数据准备就绪这里也就是有连接建立准备就绪
相当于 epoll_wait 返回了可读数量(建立连接的数量),然后我们通过 clientSelector.selectedKeys(); 拿到了就绪队列里面的 socket
-
3. 我们知道建立连接这个操作是很快的,建立成功后给 socket 注册到 clientSelector 上并且注册 READ 事件
就相当于我们又建立了一个 eventpoll 传入的就是需要监视读取事件的 socket(这其实就是之前讲的列子 sockets = getSockets()),然后 eventpoll 从工作队列中移除,需要监视的 sockets 全部指向 eventpoll ,eventpoll 的等待队列就是当前 new Thread 这个线程。
-
4. 一旦某个 socket 读准备就绪,那么 eventpoll 的 rdlist 数据就会准备好,同时会唤醒当前等待的线程来处理数据
这里思考下由于建立连接的那个线程非常快速只有绑定读取事件给 clientSelector,所以时间可以忽略。但是在 clientSelector 中获取到数据后一般需要进行业务逻辑操作,可能耗时会比较长。
如果出现这种情况由于是单线程的,那么其它 socket 的读就绪事件可能就无法得到及时的响应,所以一般的做法是,不要在这个线程中处理过于耗时的操作,因为会极大的降低其并发性,对于那种可能相对较慢的操作我们就丢给线程池去处理。
if (key.isReadable()) { // 耗时就扔进线程池中 executor.execute(task); }
其实这也就是 netty 的处理方式,我们默认使用 netty 的时候,会创建 serverBootstrap.group(boosGroup, workerGroup) 其中默认情况 boosGroup 是一个线程在处理,workerGroup 是 n * cup 个线程在处理这样就能大幅度的提升并发性了。
另外有的小伙伴会说,netty 这样处理,最终又将客户端的操作去建立一个线程又丢给线程池了,这和我们使用阻塞式 I/O 每个请求建立一个连接一样扔进线程池有撒区别。
区别就在于,对于阻塞I/O每一个请求过来会创建一个连接(就算有线程池一样有很多线程创建维护的开销),而对于多路复用来说建立连接只是一个线程在处理,并且它会将对于的 read 事件注入到其它 selector 中,对于用户来说,肯定不会建立了连接那我就时时刻刻我不停的在发送请求了,多路复用的好处就体现出来了,连接你建立 OK linux 内核维护,我不去创建线程开销。当你真正有读的请求来的时候,我再给你取分配资源执行(如果耗时就走线程池),这里真正的请求过来的数量是远远低于建立成功的 sockets 数目的。那么对于的线程池线程开销也会远远低于每个请求建立一个线程的开销。
但是如果对于那种每次获取就绪队列的时候都是接近满负荷的话就不太适用于了多路复用的场景了。