2014 CVPR
Facebook AI研究院
简单介绍
- 人脸识别中,通常经过四个步骤,检测,对齐(校正),表示,分类
- 论文主要阐述了在对齐和表示这两个步骤上提出了新的方法,模型的表现超越了前人的工作
- 对齐方面主要使用了3D人脸模型来对齐人脸,表示方面使用了9层的一个CNN,其中使用了局部卷积
人脸对齐
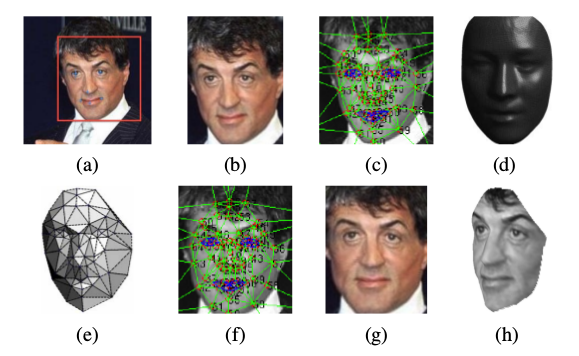
已经存在一些人脸数据库的对齐版本(比如LFW-a),但是对齐人脸仍然是一件很困难的事,由于受到姿态(人脸的非平面性),非刚性表情等因素的影响。已经有很多方法成功用于人脸对齐,论文使用的方法是基于基准点的3D建模方法,把人脸转为3D的正脸。主要步骤为:
- 用LBP+SVR的方法检测出人脸的6个基准点,眼镜两个点,鼻子一个点,嘴巴三个点,如下图(a)
- 通过拟合一个对基准点的转换(缩放,旋转,平移)对图像进行裁剪,得到下图(b)
- 对图像定位67个基准点,并进行三角剖分,得到下图(c)
- 用一个3D人脸库USF Human-ID得到一个平均3D人脸模型(正脸),如图(d)
- 学习一个3D人脸模型和原2D人脸之间的映射P,并可视化三角块,如图(e)
- 通过相关的映射,把原2D人脸中的基准点转换成3D模型产生的基准点,得到如图(f)所示,最后的正脸就是图(g)。
人脸表示
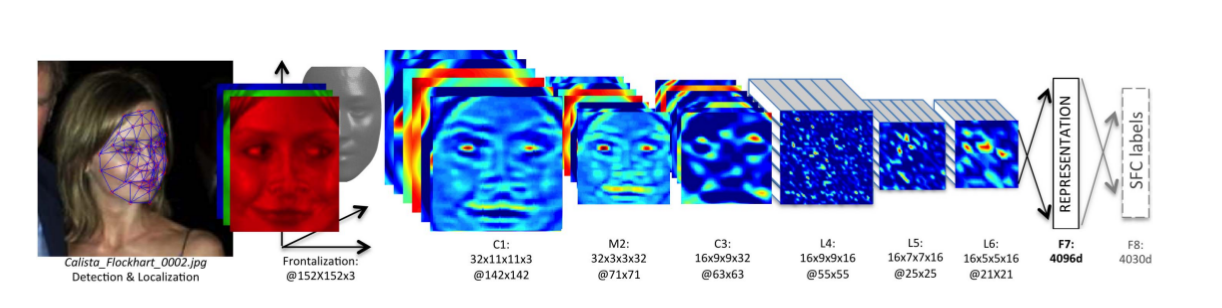
- 如下图所示,训练了一个DNN来提取人脸图像的特征表示
- C1和C3表示卷积层,M2表示最大池化层,“32x11x11x3@142x142”表示使用32个大小为11x11x3的卷积核,输出feature map的大小为142x142。前三层主要提取低水平特征,其中最大池化可以使输出对微小的偏移更加鲁棒(可能人脸对齐歪了一些也没关系),因为最大池化会损失信息所有没有使用太多。
- L4,L5,L6是局部卷积层,对于feature map上每个位置,学到不同的卷积核(即一张feature map上的卷积核参数不共享),因为人脸的不同区域会有不同的统计特征,比如眼睛和眉毛之间的区域比鼻子和嘴巴之间的区域具有更高的区分能力。局部卷积层会导致更大的参数量,需要很大的数据量才能支撑的起。
- F7和F8是全连接层,用来捕捉(不同位置的)特征的相关性,比如眼睛的位置和形状,和嘴巴的位置和形状。F7层的输出提取出来作为人脸特征,和LBP特征对比。F8层的特征喂给softmax用于分类
- .对F7层的输出特征进行归一化(除以训练集上所有样本中的最大值),得到的特征向量值都为0到1之间。
验证度量
验证就是输入两个实例,判断它们是不是属于同一类。用监督学习来进行人脸验证被广泛研究。但是有监督学习中训练数据和测试数据的不一致会导致很差的泛化能力,如果将模型拟合在小的数据集则会大大减小它泛化到其它数据集的能力。无监督度量是直接对两个特征向量做内积,而有监督度量有卡方相似度和孪生网络。
- 卡方相似度
[chi^2(f_1, f_2) = sum_i w_i(f_1[i] - f_2 [i]) ^2 / (f_1[i] + f_2[i])
]
其中(f_1)和(f_2)为DeepFace特征表示,在前面的阶段“人脸表示”得到。(w)用一个线性SVM学到,SVM的变量为((f_1[i] - f_2 [i]) ^2 / (f_1[i] + f_2[i]))。
- 孪生网络(Siamese network)
把上面那个网络,复制两份,两个人脸分别输入两个小网络,两个小网络共享参数,最后计算两个输出的特征向量的距离,用一个全连接层映射为一个逻辑单元(相同还是不相同)。网络的参数和上面那个一致,为了防止过拟合,训练的时候只训练最高两层。特征的度量公式为(d(f_1, f_2) = sum_i alpha left | f_1[i] - f_2[i] ight |)。网络结构可参考下图所示。

实验-SFC数据集(Social Face Classification)
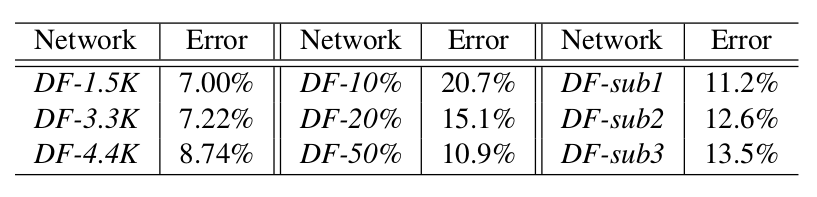
- 4.4M人脸,4030人,每人800到1200张人脸。用人脸表示的网络训练(多分类任务)。
- DF-1.5K,DF-3.3K,DF-4.4K表示人数(1.5M,3.3M,4.4M的人脸),发现从1.5K到3.3K错误提升不大,说明模型可以容纳3.3M的人脸。到4K时错误率上升到了8.74%,可以使用更多的人脸(错误率升的不大)。
- DF-10%,20%,50%表现人脸数量比,10%的时候错误率为20.7%,表明数据集太少,过拟合了。
- sub1表示砍掉C3层,sub2表示砍掉L4和L5,sub3表示这三层都砍了。由结果可以看出网络深度的必要性。
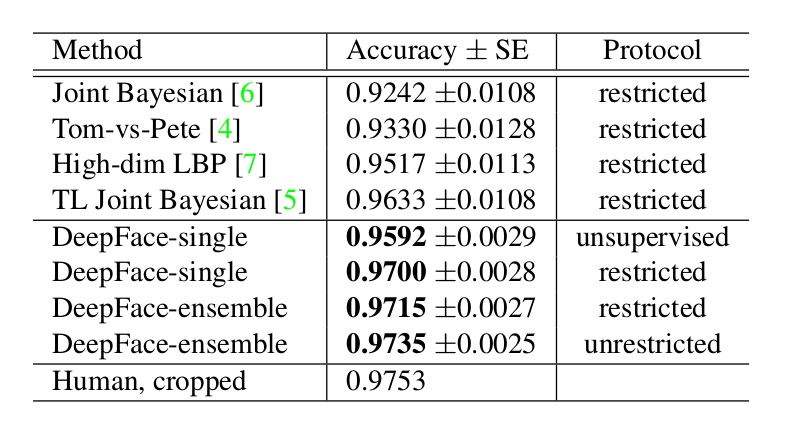
实验-LFW数据集(Labeled Faces in the Wild database)
- 13,323网页照片,5,749个名人。将其分为6000个人脸对(10份这样的6000人脸对)
- DeepFace-single,像SFC一样用网络训练多分类任务
- unsupervised表示使用无监督度量,直接对两个特征向量内积,这个时候的表现已经和之前最好的表现差不多了。
- restricted表示训练时只能获取相同或不同的标签,这里DeepFace-single使用了卡方相似度,效果提升到97%
- DeepFace-ensemble,训练多个网络(不同类型的输入,3D对齐RGB;灰度图像加上梯度大小和方向;2D对齐RGB)做集成,效果再次提升。
- unrestricted表示训练时可以获得额外的训练对,允许加入更多的训练对,效果再次提升。
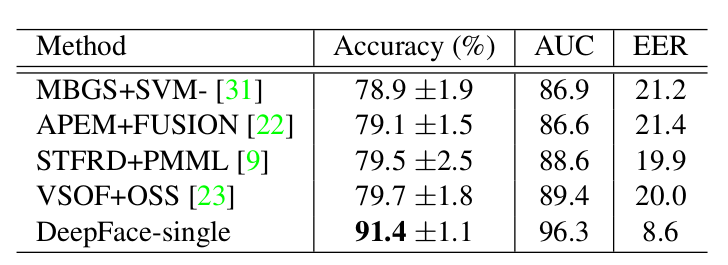
实验-YTF数据集(YouTube Faces)
- 3,425个视频,1,595个人。将其分为5,000个视频对(10分这样的视频对)
- 这里DeepFace-single使用了卡方相似度,可以看到表现超越了之前的模型
总结
- DeepFace是CNN用于人脸识别的开山之作,主要在人脸对齐和人脸表示方面提出了新方法
- 在人脸对齐方面使用3D模型来进行对齐
- 然后把对齐后的人脸送入到一个9层的网络中训练,模型的表现超越了前人的工作