本文将基于深度学习的卷积神经网络(CNN)应用于基于RGB-D-T的多模态人脸识别问题。 此外,引入了基于CNN的识别模块与各种纹理特征(LBP,HOG,HAAR,HOGOM)的后期融合,在基准RGB-D-T数据库上展示了更好的识别性能。 本文得到的结果表明,经典的纹理特征和基于CNN的特征可以相互补充以达到识别的目的。
已经开发了几种用于面部识别的算法来处理这些挑战。 这些算法的例子包括但不限于主成分分析(PCA),线性判别分析(LDA),局部二元模式(LBP),定向梯度直方图(HOG) ,Haarlike矩形特征(HAAR)和直方图Gabor有序度量(HOGOMs)。
在为人脸识别开发更好的特征和分类器的同时,多模式也被用作开发系统的解决方案。总体思路是,不同的模式应该对识别过程起补充作用。
最近在[18]中引入了包含同步RGB,深度和热量(以下称为RGB-D-T)图像的数据库,其中包括具有不同旋转,照明和表达的面部图像。
2.1 多模态人脸识别系统
深度图像可以在一定程度上处理由不同姿势引起的变化,但它们易受表情变化的影响。 对于热图像,它们对周围环境的温度变化敏感。深度信息已被广泛用于使用不同技术的人脸识别[3]。距离图像是在3D应用程序中使用的常见表示。基于3D的技术确实比2D模型更适合描述面部特征,从而增强了视点和光线变化的稳健性。这种RGB-D相机通常提供颜色和深度的同步图像。彩色图像表征人脸的外观和纹理信息,而深度图像提供每个像素距相机的距离,从而在一定程度上表示人脸的几何形状。
热红外图像记录物体发射的红外辐射量。辐射量随着温度的增加而增加,因此,这种图像可以让我们看到温度的变化。热图像提供了一种有希望的替代强度图像的方法,用于处理由于照明改变而导致的面部外观的变化[2]。在[18]中,收集了一个RGB-D-T人脸数据库,使用同步的RGB,深度和热图像进行人脸识别。
2.2 基于深度学习的人脸识别系统
面部识别有不同的深度学习技巧。主要基于使用深度卷积神经网络(CNN)的想法。大约二十年前,CNN已被用于人脸识别。
2.3 基于HOGOM的人脸识别
区分面部特征应该描述不同个体之间的差异并且在同一个体的变化期间保持稳定。Gabor滤波器可以提取面部的区别性局部纹理,但对于大型表情和光照变化不具有鲁棒性。为了增强Gabor特征的鲁棒性,Chai等人 最近通过使用有序度量(OMs)对Gabor滤波响应进行编码,Gabor有序度量(GOMs)。
GOM首先使用Gabor滤波器对面部图像进行卷积,然后使用OM对二进制数据的幅度,相位,实数和虚数滤波响应进行二值化。 之后,OM二进制代码被编码为可以被视为纹理基元的整数。 这些纹理基元在不同块中的统计分布被连接起来以形成最终的GOM特征,并且以GOM的直方图(HOGOM)的形式使用。
HOGOM的纹理特征结和通过深度学习获得的面部特征。 实验结果表明,当应用于多模态人脸识别数据集时,这种融合可以提高这两种特征的性能。
3、核心系统
通过融合具有不同权重的WNNC和CNN分类器来获得最终的分类器。
HOGOM描述符具有维度DHOGOM = Nscales×Norientation×Nbins×Nblocks。 在我们的实验中,我们使用了Nscales = 5,Norientations = 8,Nbins = 16和大小为32×32像素的块,将图像分成12个块。 然后特征向量首先被归一化。 然后,使用(主成分分析)PCA将其维数减少一半。
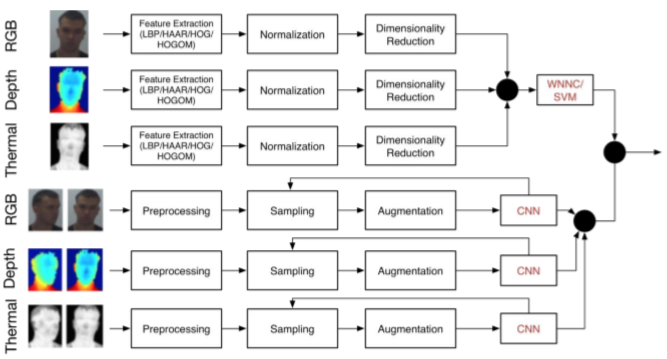
面部的RGB,深度和热量捕获用于训练模态特定的CNN,以决定两个样本是否来自同一个人。 结果与HOGOM训练的WNNC和SVM融合。
所提出的CNN方法被实现为预测两个输入图像是否对应于同一个人的二元分类问题。
图像的预处理首先通过将每个模态的面部边界框变换成平方区域来完成。较窄的尺寸被扩大以匹配另一个尺寸,之后裁剪平方区域并将其重新缩放到100×100像素的尺寸。
在每个时期应用分层采样来随机选择训练实例的子集,使得正面和负面实例的数量相等,并且正面和负面实例的每个主题的实例数量相等。
扩充用于增加可用训练实例的数量。在每个时期,采样对被随机地以0.5的概率水平翻转。 此外,每对的每个单独的帧在垂直和水平方向上随机移位±5%,引入±0.05范围内的随机噪声。
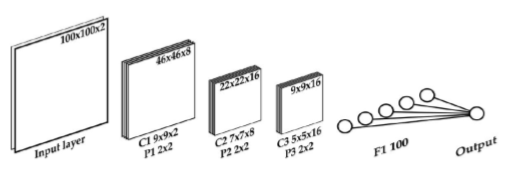
CNN选择的拓扑结构如图2所示。它由三个卷积层组成,每个卷积层都有一个2×2的最大池。 第一卷积层C1具有8个大小为9×9的卷积掩模,第二层C2具有16个大小为7×7的掩模,第三层C3具有16个大小为5×5的掩模。 最后,有一个100单位的完全连接图层和一个带有单个神经元的输出图层,可以预测两幅图像是否来自同一个主体。 拓扑中的所有神经元都是整流线性单位(ReLu)
4、实验结果
在[18]中首次引入的多模态RGB-D-T人脸数据集进行了实验。 该数据集由51人组成,大多数为20至40岁的高加索人。 在受控的实验室环境下,在不同的旋转,照明和面部表情条件下捕捉面部(参见图3)。 微软Kinect被用来捕捉RGB和Depth,而AXIS Q1922传感器被用来捕捉热图像。整个数据集总共45900张图像。
用HOGOM训练的WNNC和SVM分类器的结果与之前在[18]中使用的描述符相比是相对适中的。 为了简洁和易于理解,我们只提供训练样本数量最多的结果。 在表1至表4中,我们显示了每种模态的等误差率(EER),

由于脸部外观的变化很大,在旋转的情况下产生最高的EER。 关于模式,深度模式的误差通常较高。
在将训练样本的数量增加到25时,用HOGOM训练的线性SVM的情况下,分类错误实际上减少到零。
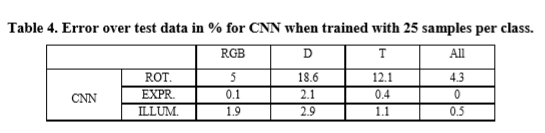
在CNN情况下,单独的形态预测在大多数情况下胜过WNNC提取的所有描述符,但与SVM方法相比具有更高的误差。
尽管HOGOM是用于旋转和表情模式变异的性能最差的描述子,但当与特定于模态的CNN融合时,获得最低的误差。
实验结果续
数据集:在[18]中首次引入的多模态RGB-D-T人脸数据集进行了实验。 该数据集由51人组成,大多数为20至40岁的高加索人。在不同的旋转,照明和面部表情条件下捕捉面部图像。微软Kinect被用来捕捉RGB和Depth,而AXIS Q1922传感器被用来捕捉热图像。整个数据集总共45900张图像。
使用2,5,10或25个均匀间隔的样本进行训练。 50个样品用于测试。为了简洁和易于理解,我们只提供训练样本数量最多的结果。 在表1至表4中,我们显示了每种模态的等误差率(EER)。在图4和图5中,我们显示了错误动态取决于训练样本的数量。
由于脸部外观的变化很大,在旋转的情况下产生最高的EER。 关于模式,深度模式的误差通常较高。
而模态融合不能系统地降低低于所有其他单独模态的误差。 在将训练样本的数量增加到25时,用HOGOM训练的线性SVM的情况下,分类错误实际上减少到零(表3)。
在CNN情况下,单独的形态预测在大多数情况下胜过WNNC提取的所有描述符,但与SVM方法相比具有更高的误差。(表4).
不用SVM的原因:然而,重要的是要注意,用于SVM模型的“一对多”方法不能处理新的看不见的主题。已发现加权后期融合可显着降低使用CNN时三种变化模式的误差,特别是对于照明变化。
本文工作:
通过结合LBP,HOG,HAAR和HOGOM等经典方法提取的面部特征,通过进行大量实验找出这些特征的互补性。这些实验表明,这些经典的面部特征中的至少一个,特别是HOGOM [4],可以互补地贡献于通过基于深度学习的面部特征获得的识别性能。
上面提到的面部特征融合已经应用于文献[18]的多模式RGB-D-T人脸数据库,突出了提出的特征融合在提高识别结果中的作用。
创新:基于深度学习的特征与基于经典外观的面部特征的融合,特别是与HOGOM的融合,以及使用具有这种融合的三模式面部数据库,之前没有人研究过。
缺点:三模式数据集不易获得,整个论文基本是以实验结果来推动的,为了降低EER而进行各种模式融合实验,缺乏有效的理论支持。