1、数据倾斜
1.1 数据倾斜的现象
现象一:大部分的task都能快速执行完,剩下几个task执行非常慢
现象二:大部分的task都能快速执行完,但总是执行到某个task时就会报OOM,JVM out of Memory,task faild,task lost,resubmitting task等错误
1.2 出现的原因
大部分task分配的数据很少(某个可以对应的values只有几个),但某几个task分配的数据非常多(某个key对应的values非常多)
2、数据倾斜解决方案
2.1 聚合源数据
方案一:直接在生成hive表的hive etl中,对数据进行聚合处理
例如:在hive etl操作时,将key对应的values,全部使用一种特殊的格式进行拼接到字符串中(“key=sessionid, value: action_seq=1|user_id=1|search_keyword=火锅|category_id=001;action_seq=2|user_id=1|search_keyword=涮肉|category_id=001”),对可以进行groupby,那么在spark中直接获取到的是<key,values>,就有可能不需要shuffle操作,就可能避免数据倾斜。
方案二:使用更小维度进行聚合处理
例如:每个key对应的10万数据,但是这10万数据中如果按不同的城市、天数等维度进行聚合,可能每个key就对应1万数据,就可以避免数据倾斜
2.2 过滤导致倾斜的key
如果业务和需求可以接受的话,在使用spark sql查询hive表中的数据时,通过where语句将导致数据倾斜的key直接过滤掉
例如:有2个key对应的数据有10万,而其他的key都只有几百的数据,那么如果业务和需求允许的话,可以直接将那两个key过滤掉,自然就不会发生数据倾斜
2.3 提高shuffle操作reduce的并行度
reduce并行度增加后,可以让reduce task分配到的数据减少,有可能缓解或基本解决数据倾斜的问题
可以在shuffle算子中传入第二个参数设置reduce端的并行度
2.4 使用随机key实现双重聚合
先将一样的key通过随机数进行拼接为新的不同的key进行局部聚合,然后将添加的随机数去掉后重新进行局部聚合(对groupByKey、reduceByKey有比较好的效果)
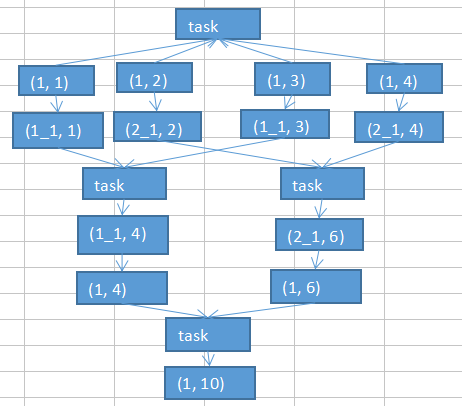
/** * 使用随机key实现双重聚合 * 处理sessionRowPairRdd..groupByKey()数据倾斜 */ final Random random=new Random(); //将相同的key进行随机打散后聚合 sessionRowPairRdd.mapToPair(new PairFunction<Tuple2<String,Row>, String, Row>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Row> call(Tuple2<String, Row> tuple2) throws Exception { return new Tuple2<String, Row>(random.nextInt(5)+"_"+tuple2._1, tuple2._2); } }).groupByKey() //将打散后的key还原后再次进行聚合 .mapToPair(new PairFunction<Tuple2<String,Iterable<Row>>, String, Iterable<Row>>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Iterable<Row>> call(Tuple2<String, Iterable<Row>> tuple2) throws Exception { String key = tuple2._1; return new Tuple2<String, Iterable<Row>>(key.split("_")[1], tuple2._2); } }).groupByKey(); /** * 使用随机key实现双重聚合 结束 */
2.5 将reduce join转换为map join
如果两个Rdd需要进行join操作,并且一个Rdd比较小,可以通过broadcast把小的Rdd广播出去
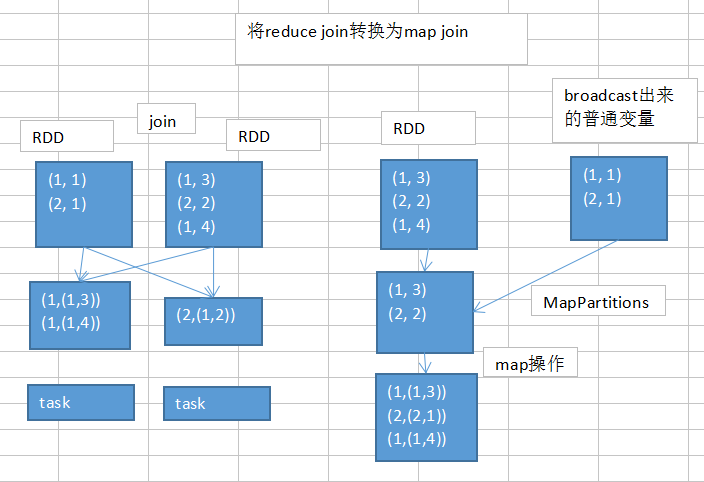
/** * 使用map join 替换reduce join * 处理 userIdPartAggrInfoPairRdd.join(userIdInfoPairRdd)导致的数据倾斜 */ //将小的Rdd userIdInfoPairRdd 作为广播变量 final Broadcast<Map<Long, Row>> broadcastUserIdInfoPairMap=javaSparkContext.broadcast(userIdInfoPairRdd.collectAsMap()); //使用map方式代替reduce join userIdJoinRdd=userIdPartAggrInfoPairRdd.mapToPair(new PairFunction<Tuple2<Long,String>, Long, Tuple2<String, Row>>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Tuple2<String, Row>> call(Tuple2<Long, String> tuple2) throws Exception { return new Tuple2<Long, Tuple2<String,Row>>(tuple2._1, new Tuple2<String, Row>(tuple2._2, broadcastUserIdInfoPairMap.value().get(tuple2._1))); } }); /** * 使用map join 替换reduce join 结束 */
2.6 sample采样倾斜key进行两次join
如果两个Rdd需要进行join操作,并且两个Rdd都比较大,不太适合使用2.5进行处理,但只有几个key会导致数据倾斜,可以先通过sample采样找出导致数据倾斜的key,然后根据找出导致数据倾斜的key将Rdd分为两个Rdd,用分成的两个Rdd分别于另一个Rdd经join后使用union进行合并为最后的Rdd

/** * 使用sample采样倾斜key进行两次join * 处理userIdPartAggrInfoPairRdd.join(userIdInfoPairRdd)导致的数据倾斜 */ //userIdPartAggrInfoPairRdd sample采样查找数据倾斜的sessionId final Long skewUserId= //进行sample采样 userIdPartAggrInfoPairRdd.sample(false, 0.1, 10) //将采样的数据映射为<userId,1> .mapToPair(new PairFunction<Tuple2<Long,String>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, String> tuple2) throws Exception { return new Tuple2<Long, Long>(tuple2._1, 1l); } //按userId进行统计<userId,count> }).reduceByKey(new Function2<Long, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Long call(Long v1, Long v2) throws Exception { return v1+v2; } //将统计结果映射为<count,userId> }).mapToPair(new PairFunction<Tuple2<Long,Long>, Long, Long>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple2) throws Exception { return new Tuple2<Long, Long>(tuple2._2, tuple2._1); } //按个数降序排列,并获取最大的userId }).sortByKey(false).take(1).get(0)._2; //将导致数据倾斜的userId过滤出来后与userIdInfoPairRdd进行join JavaPairRDD<Long, Tuple2<String, Row>> skewUserIdJoinRdd = userIdPartAggrInfoPairRdd.filter(new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple2) throws Exception { return tuple2._1.longValue()==skewUserId; } }).join(userIdInfoPairRdd); //将正常的userId过滤出来后与userIdInfoPairRdd进行join JavaPairRDD<Long, Tuple2<String, Row>> commonUserIdJoinRdd = userIdPartAggrInfoPairRdd.filter(new Function<Tuple2<Long,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<Long, String> tuple2) throws Exception { return tuple2._1.longValue()!=skewUserId; } }).join(userIdInfoPairRdd); //将导致数据倾斜的userId join后的rdd和正常的userId join后的rdd合并为最终的rdd userIdJoinRdd=skewUserIdJoinRdd.union(commonUserIdJoinRdd); /** * 使用sample采样倾斜key进行两次join结束 */
2.7 使用随机数以及扩容表进行join