第一章 使用神经网络识别手写数字
---1.1 感知器
- 感知器是一种人工神经元.它接受几个二进制输出并产生一个二进制输入.如果引入权重和阈值,那么感知器的参数可以表示为:
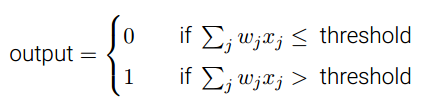 ,如果再引入偏置(表示激活感知器有多容易的估算),那么规则可以简洁表示为:
,如果再引入偏置(表示激活感知器有多容易的估算),那么规则可以简洁表示为: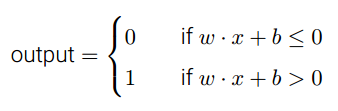
- 感知器是单输出的,但这个单输出可以被用于多个其它感知器的输入.
- 感知器可以很容易地计算基本的逻辑功能,如与,或,与非.所以感知器网络可以计算任何逻辑功能.
- 一般可以将输入层也画为一层有输出但没有输入的感知器,但它实际上只表示一种输出期望值的特殊单元.
- 使感知器能够自动调整权重和偏置的学习算法是神经网络有别于传统逻辑门的关键.
---1.2 S型神经元
- 网络中单个感知器上权重或偏置的微小改动可能会引起输出翻转,从而导致其余网络的行为改变.所以逐步修改权重和偏置来让输出接近期望很困难,所以引入了S型神经元(逻辑神经元).
- S型神经元和感知器类似,但是权重和偏置的微小改动只引起输出的微小变化.S型神经元的输入可以是0和1中的任意值,输出是σ(wx+b),其中σ被称为s型函数(逻辑函数):
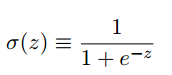 ,也就是输出为:
,也就是输出为: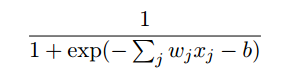
- σ函数是阶跃函数的平滑版本.这意味着权重和偏置的微小变化会产生一个微小的输出变化:
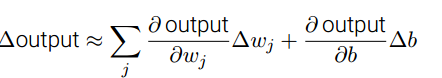 ,这意味着输出的变化是权重和偏置的变化的线性函数.
,这意味着输出的变化是权重和偏置的变化的线性函数. - 练习:
- 感知器网络的结果只和wx+b的正负有关,同时乘一个正的常数c不会改变结果的正负性
- 神经元网络中的权重和偏置都乘以一个趋向正无穷的常数c后,当wx+b != 0时,输出σ(z)近似为1,和感知器网络完全一致.当感知器的wx+b=0时,输出σ(z)=0.5,所以会不同.
---1.3 神经网络的架构
- 神经网络一般由输入层(包含输入神经元),输出层(包含输出神经元)和隐藏层组成.有时这种多层网络被称为多层感知器(MLP),但要注意它是由S型神经元构成的.
- 设计网络的输入输出层通常是比较直接的,取决于输入数据的格式和希望得到的输出数据.
- 前馈神经网络中不存在回路,这种网络的应用较为广泛.递归神经网络允许反馈环路的存在.
---1.4 一个简单的分类手写数字的网络
- 识别手写数字的问题可以分成两个子问题:分割图像,分类数字.重点是第二个问题.
- 假设一个数字是28*28的灰度图,那么输入层就包含784个输入神经元.
- 输出层使用10个神经元来表示0~9的数字.为什么不用4个神经元,通过二进制表示10个数字?这个问题没有确切的答案,只能通过启发式的方法来解释:假设神经网络中每个隐藏层的神经元视图识别图像中的某一部分,那么很显然10个输出神经元是更合理的方案.
- 练习:
- 第三层的神经元将原先代表的十进制数转换为二进制,为1的位给予1的权重,为0的位给予0的权重.
---1.5 使用梯度下降算法进行学习
- 用于学习的数据集是经典的MNIST数据集,采用的代价函数(损失函数)是均方误差(MSE):
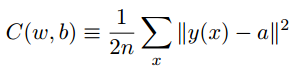
- 之所以最小化二次代价函数而不是直接最大化正确分类的图像数量,是因为在神经网络中后者关于权重和偏置的函数不是平滑的.而用前者能更好地解决如何用权重和偏置中的微小改变来取得更好的效果.
- 神经网络中经常需要大量变量,因此采用梯度下降法来计算代价函数最小值:重复计算梯度,然后沿着相反的方向移动
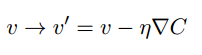 .将权重和偏置代入到公式中,就得到了神经网络学习的规则:
.将权重和偏置代入到公式中,就得到了神经网络学习的规则: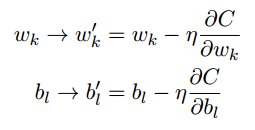 .
. -
假如需要计算每个训练输入的梯度值,训练速度会相当缓慢.因此引入了随机梯度下降,只计算小批量数据(mini-batch)的梯度值来求平均值:
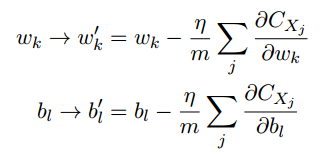 .
. -
随机梯度下降不断地选定小批量数据来进行训练,直到用完了所有的训练输入,就称为完成了一个迭代期(epoch),然后会开始一个新的迭代期.
-
练习:
- 优点:时效性,速度快.缺点:一次只选一个训练输入,偏差较大
---1.6 实现我们的网络来分类数字
- 将数据集分为训练集(用于学习),验证集(用于设置超参数),测试集(用于检验).
- 一个Network类接受一个列表sizes表示各层神经元的数量,然后用随机函数生成偏置和权重.它包含初始化__init__,前向计算feedforward,随机梯度下降SGD,计算小批量数据update_mini_batch,反向传播backprop,评估evaluate和偏导cost_derivative等方法.此外,我们还需要计算sigmoid和它的导数的两个函数sigmoid和sigmoid_prime.(注意:如果使用python3的话要将代码中的xrange改为range,mnist_loader返回的数据要改为list)
- 采用epoch=30,mini_batch=10,theta=3.0的参数,这个sizes=[784,30,10]的三层神经网络的识别率就达到了95%左右.
- 对有些问题,复杂的算法<=简单的学习算法+好的训练数据
- 练习:
- 同样参数的情况下仅有输入层和输出层的神经网络的识别率大概为62%
---1.7 迈向深度学习
- 神经网络如何识别人脸?一个启发式的想法是分解为子问题:
- 图像的左上角有一个眼睛吗?右上角有一个眼睛吗?中间有一个鼻子吗?下面中央有一个嘴巴吗?上面有头发吗?
- 子问题可以被继续分解:例如左上角有睫毛吗?有眉毛吗?有虹膜吗?
- 上述子问题同样可以被继续分解,并通过多个网络层传递.最终子网络可以回答那些只包含若干个像素点的简单问题.
- 上述这种包含多层结构(两层或更多隐藏层)的网络被称为深度神经网络.
- 深度神经网络能构建起一个复杂概念的层次结构.
第二章 反向传播算法如何工作
---2.1 热身:神经网络中使用矩阵快速计算输出的方法
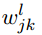 表示从第(l-1)层的第k个神经元到第l层的第j个神经元的链接上的权重,
表示从第(l-1)层的第k个神经元到第l层的第j个神经元的链接上的权重,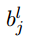 表示在第l层第j个神经元的偏置.
表示在第l层第j个神经元的偏置.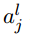 表示第l层第j个神经元的激活值.由此得到了激活值之间的关系
表示第l层第j个神经元的激活值.由此得到了激活值之间的关系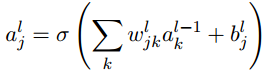 .
.-
对每一层l定义权重矩阵(其中第j行第k列的元素是
),偏置向量(每个元素是)和激活向量(每个元素是).所以上式可以改写为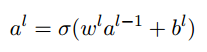 ,其中σ是向量化函数(作用σ到向量中的每个元素).中间量
,其中σ是向量化函数(作用σ到向量中的每个元素).中间量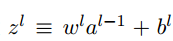 称为带权输入(每个元素是第l层第j个神经元的激活函数的带权输入).
称为带权输入(每个元素是第l层第j个神经元的激活函数的带权输入).
---2.2 关于代价函数的两个假设
- 反向传播的目标是计算代价函数关于w和b的偏导数.为了让反向传播可行,需要作出两个主要假设:
- 代价函数可以被写成一个在每个训练样本x上的代价函数的均值
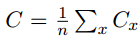
- 代价可以写成神经网络输出的函数,以二次代价函数为例
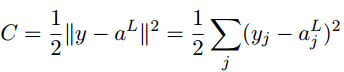
---2.3 Hadamard乘积,s⊙t
- 假设s和t是两个同样维度的向量,那么s⊙t表示按元素的乘积,称为Hadamard乘积或Schur乘积
---2.4 反向传播的四个基本方程
- 首先引入一个中间量,称为在第l层第j个神经元上的误差,被定义为
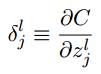 .
. -
反向传播基于四个基本方程:
- 输出层误差的方程:
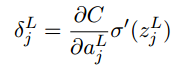
- 使用下一层的误差来表示当前层的误差:
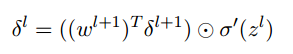
- 代价函数关于网络中任意偏置的改变率:
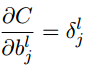
- 代价函数关于任何一个权重的改变率:
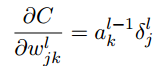

- 如果输入神经元激活值很低,或者输出神经元已经饱和了(过高或过低的激活值),权重会学习缓慢.
---2.5 四个基本方程的证明(可选)
- 使用链式法则证明了上一节的四个基本方程,本文不做记录
---2.6 反向传播算法
- 反向传播方程给出了一种计算代价函数梯度的方法:
- 输入x:为输入层设置对应的激活值a1
- 前向传播:对从前往后对每层计算相应的z=wa+b和a=σ(z)
- 输出层误差:根据BP1计算误差向量
- 反向误差传播:对后往前根据BP2对每层计算误差向量
- 输出:根据BP3和BP4计算代价函数的梯度.
---2.7 代码
- 解释了1.6节中的updata_mini_batch方法和backprop方法.
- 可以使用全矩阵方法使得反向传播算法同时对一个小批量数据中的所有样本进行梯度计算.这会提高运算速度.
---2.8 在哪种层面上,反向传播是快速的算法?
- 与直接计算偏导数相比,反向传播的优点是可以同时计算所有的偏导数,只需要一次前向传播加上一次后向传播,所以速度非常快.
---2.9 反向传播:全局观
- 反向传播到底在干什么:两个神经元之间的连接其实是关联与一个变化率因子,这个变化率因子是一个神经元的激活值相对于其他神经元的激活值的偏导数.路径的变化率因子其实就是这条路径上的众多因子的乘积.将这个过程简化就得到了反向传播算法.
第3章 改进神经网络的学习方法
---3.1 交叉熵代价函数
- 人类通常在犯错比较明显的时候学习的速度最快.而神经元在这种饱和情况下学习很有难度(也就是偏导数很小),这是因为二次代价函数关于权重和偏置的偏导数是
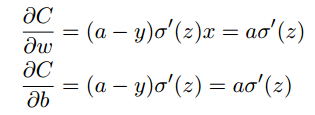 ,而σ函数的导数在接近0和1时都很小
,而σ函数的导数在接近0和1时都很小
- 解决上述问题的方法是引入交叉熵代价函数:
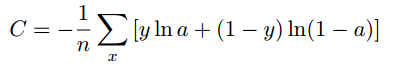
- 它是非负的,并且当实际输出接近目标值时它接近0,因此可以作为代价函数.
- 它关于权重的偏导数是
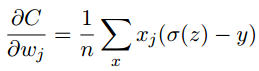 ,也就是误差越大,学习速度越快.
,也就是误差越大,学习速度越快.
- 如果输出层是线性神经元,那么二次代价函数不再会导致学习速度下降的问题,可以选用.如果输出神经元是S型神经元,交叉熵一般都是更好的选择.
- 另一种解决学习缓慢问题的方法是柔性最大值(softmax)神经元层.它的想法是定义一种新的输出层,应用柔性最大值函数在带权输入上
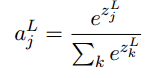 .这种函数使得输出的是一些相加为1的正数的集合,因此可以看做一个概率分布.
.这种函数使得输出的是一些相加为1的正数的集合,因此可以看做一个概率分布. - 柔性最大值层结合对数似然函数类似于S型输出层结合交叉熵代价,都可以解决学习缓慢的问题.
---3.2 过度拟合和规范化
- 神经网络因为权重和偏置数量巨大,所以特别容易发生过拟合现象.
- 检测过拟合的一种方法是早停(early stop):跟踪测试数据集合上的准确率随训练变化的情况,如果准确率不再提升那么就停止训练.一般会用验证集而不是测试集来进行早停.
- 最好的降低过拟合的方式就是增加训练样本量,但训练数据其实是很难得的资源.
- 规范化也是一种缓解过拟合的技术.效果是让网络倾向于学习小一点的权重,它是寻找小的权重和最小化原始代价函数之间的折中,相对重要性由λ控制.
- L2规范化(权重衰减)的想法是增加一个额外的规范化项
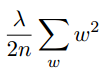 到代价函数上.其中λ是规范化参数,注意规范化项里不包含偏置.
到代价函数上.其中λ是规范化参数,注意规范化项里不包含偏置. - 规范化能帮助减轻过拟合的一种解释是:小的权重在某种程度上意味着更低的复杂性,也就对数据给出了一种更简单却更强大的解释.但实际上这只是一种实验事实.
- L1规范化的规范化项为
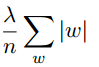 ,区别是在L1规范化中,权重通过一个常量向0进行缩小,在L2规范化中,权重通过一个和w成比例的量进行缩小.所以L1规范化倾向于聚集网络的权重在相对少量的高重要度连接上.
,区别是在L1规范化中,权重通过一个常量向0进行缩小,在L2规范化中,权重通过一个和w成比例的量进行缩小.所以L1规范化倾向于聚集网络的权重在相对少量的高重要度连接上. - 弃权(dropout)是一种相当激进的技术.原理是在小批量数据中随机地暂时删除一半的隐藏神经元然后进行训练,不断地重复这个过程后就得到了一个权重和偏置的集合.
- 人为扩展训练数据:以MNIST为例,可以通过对图像进行小的旋转,转换,扭曲等变换得到新的训练数据.
---3.3 权重初始化
- 之前我们选用均值为0标准差为1的独立高斯随机变量来选择权重和偏置.它的问题是输入隐藏神经元的带权和的绝对值会很大,也就是隐藏神经元会饱和,从而导致这些权重学习得非常缓慢.
- 假如有一个n个输入权重的神经元,那么应该使用均值为0标准差为1/√n的高斯随机分布来初始化这些权重.这会让带权和的分布变得尖锐,从而使神经元不容易饱和.
- 偏置的初始化仍用均值为0标准差为1的高斯分布.因为偏置不会让神经网络更容易饱和.
- 新的权重初始化方法会加快训练,并且有时候可以提升最终性能.
---3.4 再看手写识别问题:代码
- 使用了新的network2.py来改进神经网络.Network类中添加了新的权重初始化default_weight_initializer,准确率accuracy,总损失total_cost,保存save等方法,并且在计算小批量数据时使用了L2规范化.另外添加了交叉熵代价CrossEntropyCost,数字向量化vectorized_result,读取load等函数.
---3.5 如何选择神经网络的超参数
- 宽泛策略:可以尝试通过简化数据集(例如减少分类种类或者样本数量),提高监控速率来提高训练速度.
- 学习速率η:首先选择一个能使代价立即开始下降而非震荡或增加的值作为η的阈值的估计,并逐渐增加η的量级,直到找到一个η的值使得在开始的若干回合代价就开始震荡或增加.按照这个方法可以估计出适合的η的最大量级,然后选用大概阈值的一半来作为学习速率.注意学习速率的主要目的是控制梯度下降的步长,所以仍是通过训练集来选取的.
- 早停可以用于确定训练的迭代期数量.因为分类准确率在整体趋势下降的时候仍可能震荡,所以应该是在一段时间内都不再提升的时候再终止,例如10个回合.
- 可以通过早停采用可变的学习速率,也就是当准确率不再提升时,按照某个量下降学习速率,比如10或2,直到学习速率是初始值的1/1024或1/1000为止.
- 规范化参数λ:一开始令λ=0,先确定η的值,然后从1开始按10的量级寻找适合的λ.
- 小批量数据大小:是一个相对独立的超参数,所以只需折中地选择一个速度较快且效果较好的值.
- 网格搜索(grid search):一种自动进行超参数优化的方式.
---3.6 随机梯度下降的变化形式
- 介绍了随机梯度下降的变化形式,Hessian技术和momentum技术.
- 人工神经元的其他模型:使用双曲正切的tanh神经元
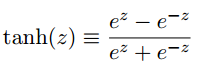 ,修正线性神经元ReLU
,修正线性神经元ReLU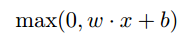
第4章 神经网络可以计算任何函数的可视化证明
---4.1 两个预先声明
- "神经网络可以计算任何函数"这句话有两个预先声明:
- 这不是说一个网络可以被用来准确地计算任何函数,而是尽可能好的一个近似.
- 可以被近似的函数一般是连续函数,因为神经网络计算的就是输入的连续函数.
---4.2 一个输入和一个输出的普遍性
- 对于S型函数σ来说,偏置可以使图像左右平移,权重可以使图像变宽或变陡(甚至接近阶跃函数)
- 阶跃的位置s=-b/w,也就是和b成正比,和w成反比.
- 使用不同的权重叠加多个隐藏神经元的阶跃函数,可以得到阶梯状或凸起的函数,从而近似各种函数.
---4.3 多个输入变量
- 先从两个输入变量x,y开始,此时的函数图像是三维的,而x和y的权重分别使x轴和y轴方向发生阶跃,如果使偏置b=-3h/2就构成了一个塔形函数.通过组合多个这样的网络就可以得到任意多的塔型.
---4.4 S型神经元的延伸
- 只要激活函数s(z)满足在z->-∞和z->∞时定义明确且彼此不同,那么基于这样一个激活函数的神经元就可以普遍用于计算,因为它存在阶跃.
---4.5 修补阶跃函数
- 在激活函数的阶跃段存在一个故障窗口,因为函数在这里表现得和阶跃函数非常不同.通过令权重为一个足够大的值可以解决这个问题.还可以通过大量叠加函数来解决,因为在一个近似中的故障窗口的点不会在另一个故障窗口中.
---4.6 结论
- 单个隐藏层就有可能拟合函数了,但深度学习网络有一个分级结构.普遍性显示了神经网络能计算任何函数,而深度网络最适用于学习能够解决许多现实世界问题的函数.
第5章 深度神经网络为何很难训练
---5.1 消失的梯度问题
-
如果只是单纯地在先前创建的network2上增加隐藏层的层数,会发现效果并没有显著提高,甚至变差了.这是因为通过隐藏层反向传播的时候梯度倾向于变小,导致前面的隐藏层中的神经元学习速度慢于后面的隐藏层,这就是梯度弥散(梯度消失).
- 梯度弥散是可以避免的,但替代方法又会造成前面的层中的梯度过大,也就是梯度爆炸.
---5.2 什么导致了消失的梯度问题?深度神经网络中的梯度不稳定性
-
先假设隐藏层都只包含一个神经元.会发生梯度弥散是因为隐藏层梯度的变化值要乘上该层后面的隐藏层的权重和σ',因为权重通常小于1,而σ'小于1/4,所以越前面的隐藏层的梯度变化越小.同理,如果权重很大,而σ'不是很小,那么就发生了梯度爆炸.
- 根本问题就是前面层的梯度是来自后面的层上项的成绩.所以当层次过多时仍采用标准的基于梯度的学习算法,就会产生不稳定的梯度问题.解决方法有使用ReLu作为激活函数,使用Batch Normalization层等.
---5.3 在更加复杂网络中的不稳定梯度
-
假如每个隐藏层包含多个神经元,仍可以得到与上节相似的结论
---5.4 其它深度学习的障碍
-
激活函数的选择,权重的初始化,学习算法的实现方式等因素都影响着深度学习的难度.
第6章 深度学习
---6.1 介绍卷积网络
- 卷积神经网络(CNN)是一个利用空间结构的特殊网络架构,擅长于分类图像.
- 局部感受野(local receptive fields):在卷积网络中,把输入看作是矩形排列的神经元更有帮助.第一个隐藏层中的每个神经元会连接到输入神经元的一个小区域,这块区域就叫局部感受野.它是输入像素上的一个小窗口.每个局部感受野中的输入神经元对应的连接都学习一个权重,而隐藏神经元也同时学习一个总的偏置.在整个输入图像上交叉移动局部感受野,每个局部感受野对应不同的隐藏神经元.跨距是指每次交叉移动的像素大小.
- 共享权重和偏置(shared weights/biases):第一层隐藏神经元中的每一个都有相同的权重(和局部感受野大小相同的矩阵)和偏置,这意味它们检测完全相同的特征,只是在输入图像的不同位置.卷积网络能更好地适应图像的平移不变性.因此,把从输入层到隐藏层的映射称为一个特征映射,以这种方式定义特征映射的权重和偏置称为共享权重和共享偏置,共享权重和偏置经常被称为一个卷积核或者滤波器.一个完整的卷积层由几个不同的特征映射组成.共享权重和偏置的优点是大大减少了参与的卷积网络的参数.
- 池化层/混合层(pooling layers):通常紧接在卷积层之后使用,目的是简化卷积层输出的信息.一个混合层取得从卷积层输出的每一个特征映射并且从它们准备一个凝缩的特征映射,比如每个单元概括了前一层的一个2*2的区域.
- 最大值混合(max-pooling):输出输入区域的最大激活值.
- L2混合(L2 pooling):输出输入区域中激活值的平方和的平方根.
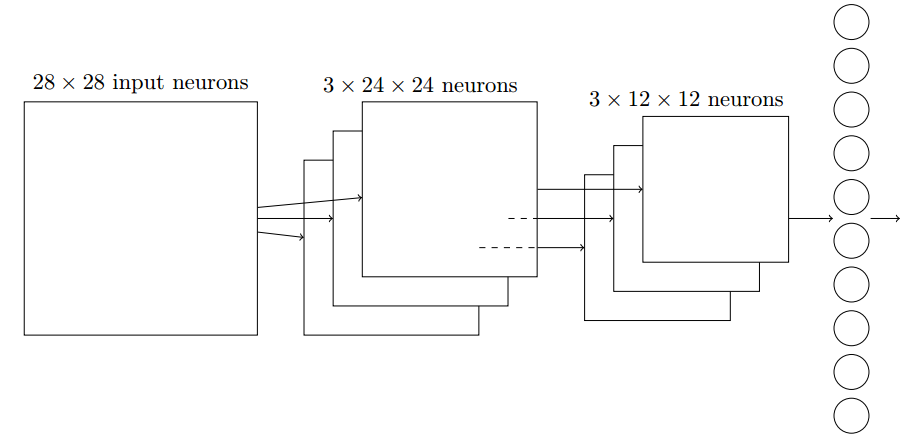
---6.2 卷积神经网络在实际中的应用
- 应用第二个卷积-混合层意味着这一层输入原始输入图像的一个凝缩版本.这一层中的特征检测器可访问所有前面层的特征,但仅在其特定的局部感受野中.
- 修正线性单元ReLu的性能一般优于基于S型激活函数的网络,这可能是因为它在z取最大极限时不会饱和.
- 以算法形式来扩展训练数据很可能可以显著提升分类准确率,例如将图像上下左右平移一个像素,旋转,位移,扭曲图像.
- 通过增加一个额外的全连接层并采用dropout技术可以再次显著提高准确率.一般只对全连接层应用dropout即可,因为卷积层先天就有抵抗过拟合的特性.
- 通过投票来组合几个不同的网络也是一种好方法,也就是集成学习的思想.
- 通过卷积层,规范化,ReLU,GPU等技术,我们缓解了梯度不稳定问题.
---6.3 卷积网络的代码
- 使用Theano库实现了network3.由于看本书的目的是更好地学习TensorFlow和keras,因此这里的代码我没有自己再实现一遍.
---6.4 图像识别领域中的近期进展
- 介绍了一些最近的使用神经网络的图像识别成果,例如ImageNet的识别.
---6.5 其他的深度学习模型
- 递归神经网络(RNN):与前馈神经网络不同,RNN是某种体现出了随时间动态变化的特性的神经网络.它在处理时序数据和过程上效果不错,例如语音识别或自然语言处理.
- 长短期记忆单元(LSTM):因为RNN中梯度不仅通过层反向传播,还会根据时间反向传播,所以不稳定梯度的问题特别严重.通过引入LSTM进入RNN中可以解决这个问题.
- 深度信念网络(DBN):DBN是一种生成式模型,不仅可以用于识别,还可以进行生产.另外DBN可以进行无监督和半监督的学习.
---6.6 神经网络的未来
- 介绍了一些关于神经网络,深度学习,人工智能的思考.