参考网址:https://www.cnblogs.com/qingyunzong/p/8888080.html
0.环境准备
hadoop高可用搭建
1.伪分布式
(1)下载,上传,解压包
从微软镜像站下载
http://mirrors.hust.edu.cn/apache/
从清华镜像站下载
https://mirrors.tuna.tsinghua.edu.cn/apache/
#解压包到对应规划目录
tar -xvf spark-2.2.1-bin-hadoop2.7.tgz -C /opt/hadoop/apps
#创建软连接
ln -s spark-2.2.1-bin-hadoop2.7/ spark
(2)配置环境变量
vim ~/.bashrc export SPARK_HOME=/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/ export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin source ~/.bashrc
(3)配置spark-site.xml
cp spark-env.sh.template spark-env.sh vim spark-env.sh
export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161 export HADOOP_HOME=/opt/hadoop/apps/hadoop-2.7.1/ export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=7077 export SPARK_WORKER_MEMORY=1G
(4)启动及验证
a.启动
#在spark/sbin目录下执行
./start-all.sh
b.验证
Jps查看进程
[root@master sbin]# jps 5906 NameNode 6978 Worker 6281 DFSZKFailoverController 7050 Jps 6926 Master 6111 JournalNode
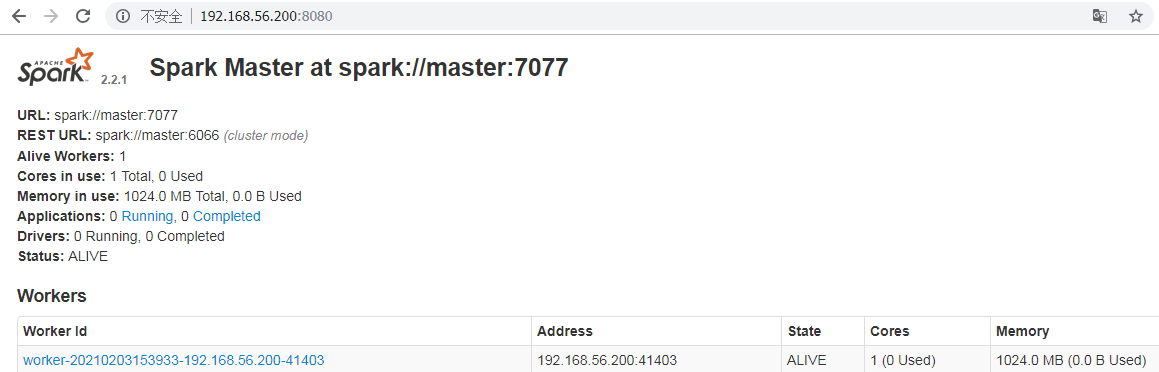
打开网页http://localhost:8080/查看
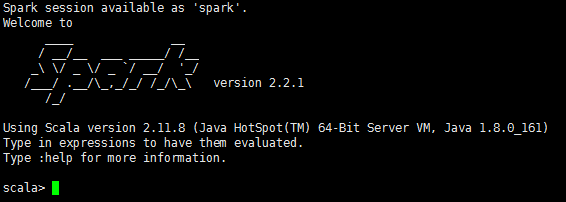
到spark的bin目录下./spark-shell命令查看
2.高可用安装
(1)配置spark-env.sh
export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161 export HADOOP_HOME=/opt/hadoop/apps/hadoop-2.7.1/ export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_WORKER_MEMORY=500m export SPARK_WORKER_CORES=1 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=slave1:2181,slave2:2181,slave3:2181 -Dspark.deploy.zookeeper.dir=/opt/hadoop/data/zookeeper/spark"
(2)配置slaves
vim slaves
master
slave1
slave2
slave3
(3)将文件分发给slave1,slave2,slave3
scp slaves slave1:/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/conf scp slaves slave2:/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/conf scp slaves slave3:/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/conf scp spark-env.sh slave1:/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/conf scp spark-env.sh slave2:/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/conf scp spark-env.sh slave3:/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/conf
(4)配置环境变量
vim ~/.bashrc
export SPARK_HOME=/opt/hadoop/apps/spark-2.2.1-bin-hadoop2.7/
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source ~/.bashrc
(5)启动及验证
#在spark/sbin目录下执行 ./start-all.sh
#slave1,slave2,slave3的master没有启动,需要手动启动
./start-master.sh
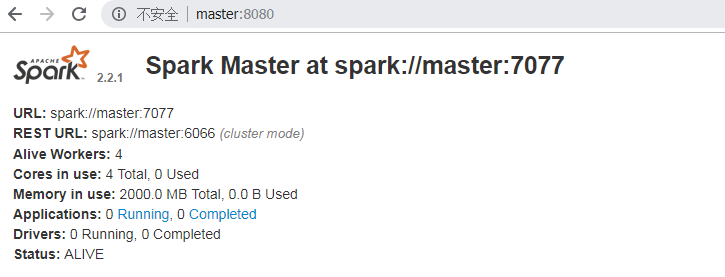
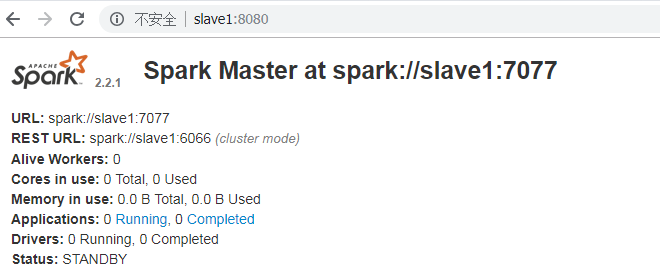
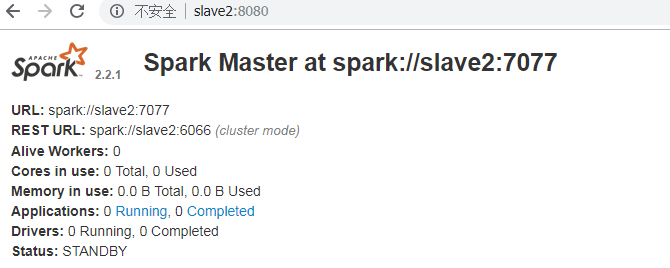

如果将master节点关闭

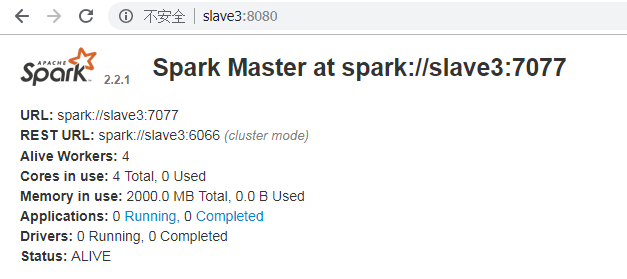
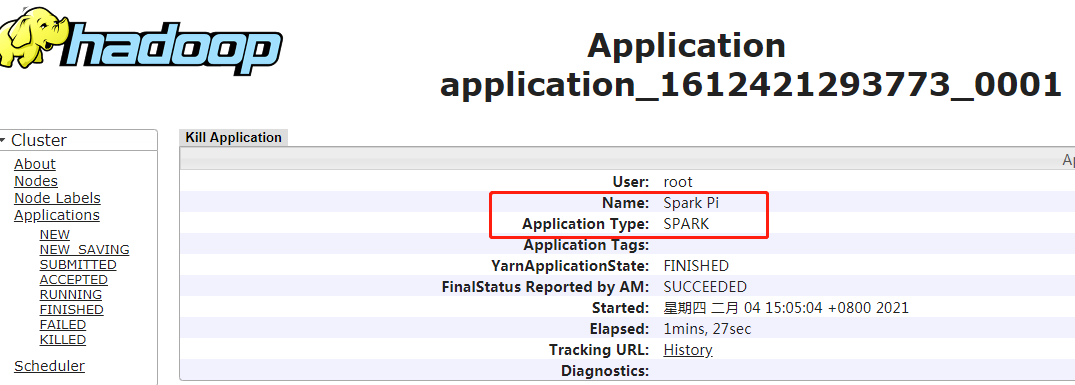
3.基于standalone提交任务
(1)提交第一个任务
#计算圆周率 /opt/hadoop/apps/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 500m --total-executor-cores 1 /opt/hadoop/apps/spark/examples/jars/spark-examples_2.11-2.2.1.jar 100
(2)启动spark-shell
#local模式启动 /opt/hadoop/apps/spark/bin/spark-shell #集群模式启动 /opt/hadoop/apps/spark/bin/spark-shell --master spark://slave1:7077 --executor-memory 500m --total-executor-cores 1
#sc是SparkContext,spark是SparkSession
(3)运行wordcount程序
a.编写文件,并上传到hdfs
#1.创建文件夹 mkdir -p /opt/hadoop/data/spark/exercise #2.编辑文件 vim word.txt #文件内容如下 hello java hello scala hello python hello spark hello spark hello hadoop hello scala hello spark hello lilei hello spark hello hadoop hello hadoop hello java #3.将文件上传至hdfs hdfs dfs -mkdir -p /spark/input
b.spark-shell命令下执行程序
sc.textFile("/spark/input/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/spark/output")
4.基于yarn提交任务
(1)启动spark-shell
spark-shell --master yarn --deploy-mode client
报错:


[root@master sbin]# spark-shell --master yarn --deploy-mode client Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 21/02/04 12:24:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 21/02/04 12:25:07 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041. 21/02/04 12:25:24 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. 21/02/04 12:28:12 ERROR spark.SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master. at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:85) at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:62) at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173) at org.apache.spark.SparkContext.<init>(SparkContext.scala:509) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2516) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:918) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:910) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:910) at org.apache.spark.repl.Main$.createSparkSession(Main.scala:101) at $line3.$read$$iw$$iw.<init>(<console>:15) at $line3.$read$$iw.<init>(<console>:42) at $line3.$read.<init>(<console>:44) at $line3.$read$.<init>(<console>:48) at $line3.$read$.<clinit>(<console>) at $line3.$eval$.$print$lzycompute(<console>:7) at $line3.$eval$.$print(<console>:6) at $line3.$eval.$print(<console>) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:786) at scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:1047) at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:638) at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:637) at scala.reflect.internal.util.ScalaClassLoader$class.asContext(ScalaClassLoader.scala:31) at scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:19) at scala.tools.nsc.interpreter.IMain$WrappedRequest.loadAndRunReq(IMain.scala:637) at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:569) at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:565) at scala.tools.nsc.interpreter.ILoop.interpretStartingWith(ILoop.scala:807) at scala.tools.nsc.interpreter.ILoop.command(ILoop.scala:681) at scala.tools.nsc.interpreter.ILoop.processLine(ILoop.scala:395) at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply$mcV$sp(SparkILoop.scala:38) at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37) at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37) at scala.tools.nsc.interpreter.IMain.beQuietDuring(IMain.scala:214) at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:37) at org.apache.spark.repl.SparkILoop.loadFiles(SparkILoop.scala:98) at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply$mcZ$sp(ILoop.scala:920) at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909) at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909) at scala.reflect.internal.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:97) at scala.tools.nsc.interpreter.ILoop.process(ILoop.scala:909) at org.apache.spark.repl.Main$.doMain(Main.scala:74) at org.apache.spark.repl.Main$.main(Main.scala:54) at org.apache.spark.repl.Main.main(Main.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:775) at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180) at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:119) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) 21/02/04 12:28:12 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered! 21/02/04 12:28:13 WARN metrics.MetricsSystem: Stopping a MetricsSystem that is not running org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master. at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:85) at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:62) at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173) at org.apache.spark.SparkContext.<init>(SparkContext.scala:509) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2516) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:918) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:910) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:910) at org.apache.spark.repl.Main$.createSparkSession(Main.scala:101) ... 47 elided <console>:14: error: not found: value spark import spark.implicits._ ^ <console>:14: error: not found: value spark import spark.sql ^ Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_ version 2.2.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161) Type in expressions to have them evaluated. Type :help for more information. scala>
#停止yarn集群,修改yarn-site.xml,然后启动yarn集群
<!-- spark 部署到 yarn 上需要这两个配置 --> <!-- 是否启动一个线程检查每个任务正在使用的物理内存,如果超出分配值,则直接杀掉该任务,默认为 true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否启动一个线程检查每个任务正在试用的虚拟内存,如果超出分配值,则直接杀掉该任务,默认为 true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- spark 部署到 yarn 上需要这两个配置 -->
#结果 spark-shell --master yarn --deploy-mode client Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 21/02/04 14:23:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 21/02/04 14:23:19 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. Spark context Web UI available at http://192.168.56.200:4040 Spark context available as 'sc' (master = yarn, app id = application_1612418410824_0001). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_ version 2.2.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161) Type in expressions to have them evaluated. Type :help for more information.
(2)spark-shell下运行程序
scala> val array = Array(1,2,3,4) array: Array[Int] = Array(1, 2, 3, 4) scala> val rdd = sc.makeRDD(array) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:26 scala> rdd.count res1: Long = 4
(3)运行自带计算圆周率程序
/opt/hadoop/apps/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --executor-memory 500m --total-executor-cores 1 /opt/hadoop/apps/spark/examples/jars/spark-examples_2.11-2.2.1.jar 100