面试总结
软通动力电话面试:
1.JDBC和hibernate的区别
(1)hibernate和jdbc主要区别就是,hibernate先检索缓存中的映射对象( 即hibernate操作的是对象),而jdbc则是直接操作数据库. (2)Hibernate是JDBC的轻量级的对象封装,它是一个独立的对象持久层框架,和App Server,和EJB没有什么必然的联系。Hibernate可以用在任何JDBC可以使用的场合 (3)Hibernate是一个和JDBC密切关联的框架,所以Hibernate的兼容性和JDBC驱动,和数据库都有一定的关系,但是和使用它的Java程序,和App Server没有任何关系,也不存在兼容性问题。 还有一点,正确的使用JDBC技术,它的效率一定比hibernate要好,因为hibernate是基于jdbc的技术.
2.Echarts的实现原理
Canvas
基于像素
单个html,类似于画笔在画布上画画
Echarts基于canvas画图
Svg
基于对象模型
多个图形元素
高保真
3.ajax是如何进行前后台交互的
1、url 请求地址 2、type 请求方式,默认是'GET',常用的还有'POST' 3、dataType 设置返回的数据格式,常用的是'json'格式,也可以设置为'html' 4、data 设置发送给服务器的数据 5、success 设置请求成功后的回调函数 6、error 设置请求失败后的回调函数 7、async 设置是否异步,默认值是'true',表示异步
上海中信信息发展有限公司:
1.SSM之间有什么关系,各自的作用
1.持久层:DAO层(mapper层)(属于mybatis模块) DAO层:主要负责与数据库进行交互设计,用来处理数据的持久化工作。 DAO层的设计首先是设计DAO的接口,也就是项目中你看到的Dao包。 然后在Spring的xml配置文件中定义此接口的实现类,就可在其他模块中调用此接口来进行数据业务的处理,而不用关心接口的具体实现类是哪个类,这里往往用到的就是反射机制,DAO层的jdbc.properties数据源配置,以及有 关数据库连接的参数都在Spring的配置文件中进行配置。 ps:(有的项目里面Dao层,写成mapper,当成一个意思理解。) 2.业务层:Service层(属于spring模块) Service层:主要负责业务模块的逻辑应用设计。也就是项目中你看到的Service包。 Service层的设计首先是设计接口,再设计其实现的类。也就是项目中你看到的service+impl包。 接着再在Spring的xml配置文件中配置其实现的关联。这样我们就可以在应用中调用Service接口来进行业务处理。 最后通过调用DAO层已定义的接口,去实现Service具体的实现类。 ps:(Service层的业务实现,具体要调用到已定义的DAO层的接口.) 3.控制层/表现层:Controller层(Handler层) (属于springMVC模块) Controller层:主要负责具体的业务模块流程控制,也就是你看到的controller包。 Controller层通过要调用Service层的接口来控制业务流程,控制的配置也同样是在Spring的xml配置文件里面,针对具体的业务流程,会有不同的控制器。 4.View层 (属于springMVC模块) 负责前台jsp页面的展示,此层需要与Controller层结合起来开发。 Jsp发送请求,controller接收请求,处理,返回,jsp回显数据。
2.使用Oracle的驱动是什么
oracle数据库的驱动是固定的,连接时,直接写oracle.jdbc.driver.OracleDriver即可
3.MVC模式实现技术有哪些
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。 MVC 是一种使用 MVC(Model View Controller 模型-视图-控制器)设计创建 Web 应用程序的模式: Model(模型)表示应用程序核心(比如数据库记录列表)。 View(视图)显示数据(数据库记录)。 Controller(控制器)处理输入(写入数据库记录)。 MVC 模式同时提供了对 HTML、CSS 和 JavaScript 的完全控制。 Model(模型)是应用程序中用于处理应用程序数据逻辑的部分。 通常模型对象负责在数据库中存取数据。 View(视图)是应用程序中处理数据显示的部分。 通常视图是依据模型数据创建的。 Controller(控制器)是应用程序中处理用户交互的部分。 通常控制器负责从视图读取数据,控制用户输入,并向模型发送数据。 MVC 分层有助于管理复杂的应用程序,因为您可以在一个时间内专门关注一个方面。例如,您可以在不依赖业务逻辑的情况下专注于视图设计。同时也让应用程序的测试更加容易。 MVC 分层同时也简化了分组开发。不同的开发人员可同时开发视图、控制器逻辑和业务逻辑。
4.get和post的区别
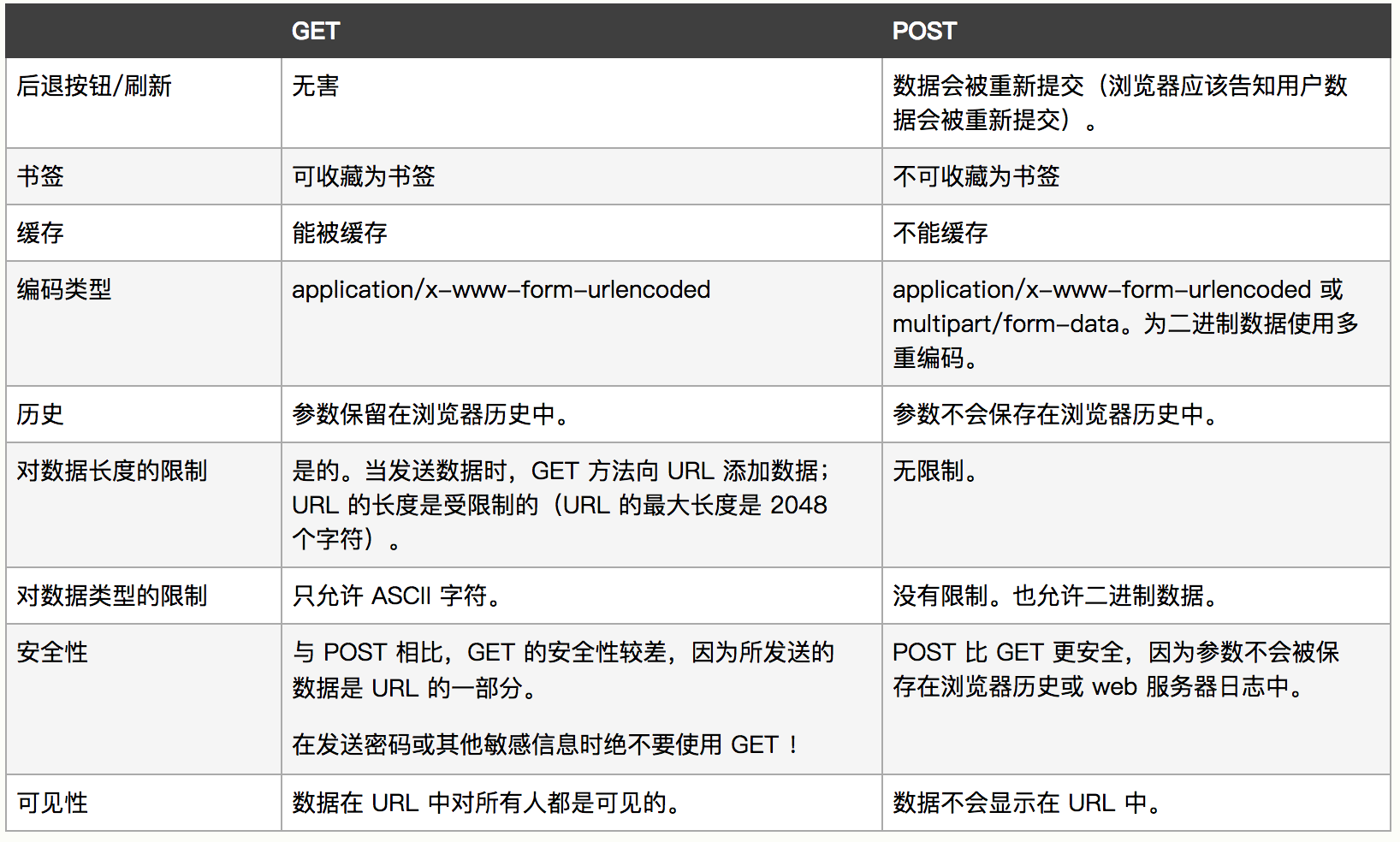
5.redis缓存机制
数据库缓存: sql语句时key值,查询结果resultSet是value,当同一个查询语句访问时(select * from t_product),只要曾经查询过,调用缓存直接返回resultSet,节省了数据库读取磁盘数据的时间。 持久层缓存: 减少了连接数据库的时间;减少了resultSet封装成对象的过程。 业务层和控制层的缓存: 减少调用层次。 描述缓存在业务层的逻辑: 查询商品信息 判断当前查询在缓存是否有数据 如果有数据,直接返回,当前请求结束; 如果没有数据,查询持久层数据库数据,获取数据存储再缓存一份,供后续访问使用; 缓存雪崩/缓存击穿 海量请求访问服务器,服务器的性能由缓存支撑,一旦一定范围的缓存数据未命中,请求的数据访问涌入数据库;承受不了压力造成宕机--重启--海量请求并未消失--宕机--重启,系统长时间不可用;这种情况就是缓存的雪崩。
多飞网络科技:
1.==和equals()的区别
对于==,比较的是值是否相等如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;如果作用于引用类型的变量,则比较的是所指向的对象的地址
对于equals方法,注意:equals方法不能作用于基本数据类型的变量,
equals继承Object类,比较的是是否是同一个对象如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;
诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
2.++i和i++的区别
i++是先赋值,然后再自增;++i是先自增,后赋值。
3.hibernate是通过什么对象访问数据库的
Hibernate,对于java来说很重要的一个东西,用于持久层。之前看了很多配置的,都不行,自己来写一个配置成功的。 环境:jdk1.8,eclipse-jee-oxygen,mysql-connector-java-5.1.46,hibernate 5.2. 首先要确保你的jdk,eclipse和mysql装好。然后下载jar包,mysql和hibernate的jar包。 然后安装JBoss插件,eclipse中Help-----eclipse market里面输入JBoss并搜索,找到JBoss之后,install,这里只需要对应hibernate的那些即可。
4.Oracle的存储方式
一、文件系统 (最简单的方式) 从本机存储划分出一部分空间给数据提供存储。 1.使用方式: ① 对这块区域做一个格式化(这是windows的称呼。在Linux和Unix系统中,叫创建文件系统。) ② 对磁盘进行挂载(windows中叫盘符) ## 对访问区域的一个接口 2.特点: 优点:数据文件容易访问,管理方便。 缺点:访问性能受到影响,中间多了一层文件系统 二、裸设备 该存储空间没有经过格式化,数据直接存放在该存储空间上。 普通用户无法访问,只有数据库软件才能够直接访问。 1.特点 优点:少了文件系统中间层,访问更加快捷,I/O性能比文件系统会提高20% 缺点:管理不方便,不能够cp,rf等操作。但是可以用Oracle工具处理(dd、RMAN) 三、ASM磁盘 ASM:Automatic Storage Management(Oracle 10g以后) 提供OMF管理方式: 手工建库时:db_create_file_dest=+DISK1 日志文件: db_create_logfile_dest=+DISK1 ASM磁盘,通过asm instance进行管理。数据库实例直接访问asm实例,这样访问方式更加紧密直接 Oracle 11g以后,允许操作系统和ASM之间进行交互 四、启动管理ASM的实例 1.编辑ASM初始化参数文件内容 $ORACLE_HOME/dbs/init+ASM.ora *.background_dump_dest='/u01/app/oracle/admin/+ASM/bdump' *.core_dump_dest='/u01/app/oracle/admin/+ASM/bdump' *.instance_type='asm' *.large_pool_size=12M *.remote_login_passwordfile='SHARED' *.user_dump_dest='/u01/app/oracle/admin/+ASM/bdump' 2.启用ASM实例 $ export ORACLE_SID=+ASM $ sqlplus / as sysdba SQL> startup nomount ASM instance started Total System Global Area 82736155 bytes Fixed Size 6254372 byyes Variable Size 73625362 bytes ASM Cache 25173827 bytes
3.(第一次使用ASM)启动时会报错 ORA-29701 unable to connect to Cluster Manager 需要做如下处理: $ cd $ORACLE_HOME/bin $ su root(以root身份执行,但是不更改环境变量) $ ./localconfig delete $ ./localconfig add 5.裸设备绑定关系 /dev/raw/raw2: bound to major 58,minor 0 /dev/raw/raw3: bound to major 58,minor 1 /dev/raw/raw4: bound to major 58,minor 2 /dev/raw/raw5: bound to major 58,minor 3 6.创建磁盘组 create diskgroup disk1 normal redundancy failgroup fg1 disk '/dev/raw/raw1' name d1 failgroup fg2 disk '/dev/raw/raw2' name d2 failgroup fg3 disk '/dev/raw/raw3' name d3 failgroup fg4 disk '/dev/raw/raw4' name d4 failgroup fg5 disk '/dev/raw/raw5' name d5 failgroup fg6 disk '/dev/raw/raw6' name d6; 注:external redundancy (主)表明冗余度仅要求一个故障组,假设这个磁盘对 于正在运行的数据库操作 normal redundancy 标准冗余度提供双向镜像,要求一个磁盘中要有两个故 障组 high redundancy 提供三向镜像,要求一个磁盘中要有三个磁盘组 create diskgroup disk1 external redundancy disk '/dev/raw/raw3'; 在一个磁盘组中的各个磁盘中的文件,被粗糙的或精细的分割,粗糙分割为1M为单位分布于所有的磁盘中,适用于数据仓库,精细分割为128KB位单位分布文件,适用于OLTP。 7.查看新的可用磁盘组 SQL> select GROUP_NUMBER,name,type,total_mb,free_mb from v$asm_diskgroup; SQL> select group_number,disk_number,name,failgroup,create_date,path from v$asm_disk;
8.删除磁盘组 drop diskgroup disk1 drop diskgroup disk1 including contents;(磁盘组中有数据库对象) 9.为磁盘组添加磁盘 alter diskgroup disk1 ass failgroup fg4 disk '/dev/raw/raw4' name d4; 10.从磁盘组中删除一个磁盘成员 alter diskgroup disk1 drop disk d4; 11.可以同时对磁盘组进行DROP和ADD操作,这样只发生一次平衡操作,减少CPU和I/O时间 aletr diskgroup disk1 add failgroup fg4 disk '/dev/raw/raw4' name d4 group disk d3;
北京爱朗格瑞:
1.hibernate如何处理sql语句
hibernate本来就支持 原sql 调用执行sql的方法就行了 调用方法的时候注意看所需的参数 @Autowired private SessionFactory sessionFactory; sessionFactory.getCurrentSession().createSQLQuery(sql);
2.JDBC是如何处理sql中传入的参数的
一、数组形式的参数 优点: 针对简单sql,可以节约部分内存空间。减少代码量、易读。 缺点: 1、相同的参数不可以复用,让array占用更多的空间。(当然,以现在的硬件来说,这点空间/内存、多余添加数组值花费的时间 完全微不足道) 2、如果是in的参数,要动态拼接(?)占位符。(个人认为最麻烦、繁琐的,扩展:oracle对in最大支持1000) 3、如果sql中参数过多,其实不好阅读修改。 个人习惯用List添加参数,然后再把List转换成Array。 好处是:如果用数组,当sql存在动态条件,那么无法确定数组长度。而用List就不需要自己去维护。 二、map形式的参数 优点: 1、解决了in参数的问题。 2、参数值可以复用。 三、javaBean形式的参数 如果参数是通过JavaBean传到dao层,那么不用把bean转换成map。相对的如果是通过map传到dao层的,也用map形式也无需转换成javaBean。
3.SVN中标记和标记合并的作用
SVN的“合并(Merge)”功能:这个功能是用来将分支(branch)与主干(Trunk)合并用的。通过自动合并,可以将大部分文件的变动合并到一起,形成一个集合全部改动的文件。
SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS、CVS,它采用了分支管理系统,它的设计目标就是取代CVS。互联网上很多版本控制服务已从CVS迁移到Subversion。
4.使用vue.js开发
那么什么是Vue组件呢?它是vue.js最强大的功能之一,是可扩展的html元素,是封装可重用的代码,同时也是Vue实例,可以接受相同的选项对象(除了一些根级特有的选项) 并提供相同的生命周期钩子。
组件系统是Vue.js其中一个重要的概念,它提供了一种抽象,让我们可以使用独立可复用的小组件来构建大型应用,任意类型的应用界面都可以抽象为一个组件树:
那么什么是组件呢?
组件可以扩展HTML元素,封装可重用的HTML代码,我们可以将组件看作自定义的HTML元素。
使用组件的好处?
提高开发效率
方便重复使用
简化调试步骤
提升整个项目的可维护性
便于多人协同开发
掌缘信息科技:
1.Linux基本操作命令,如何查看文件内容
查看文件内容的命令: cat 由第一行开始显示内容,并将所有内容输出 tac 从最后一行倒序显示内容,并将所有内容输出 more 根据窗口大小,一页一页的现实文件内容 less 和more类似,但其优点可以往前翻页,而且进行可以搜索字符 head 只显示头几行 tail 只显示最后几行 nl 类似于cat -n,显示时输出行号 tailf 类似于tail -f 1.cat 与 tac (不常用) cat的功能是将文件从第一行开始连续的将内容输出在屏幕上。 cat语法:cat [-n] 文件名 (-n : 显示时,连行号一起输出) tac的功能是将文件从最后一行开始倒过来将内容数据输出到屏幕上。 tac语法:tac 文件名。 2.more和less(常用) more功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上。 more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能 。more命令从前向后读取文件,因此在启动时就加载整个文件。 命令格式: more [-dlfpcsu ] [-num ] [+/ pattern] [+ linenum] [file ... ] 命令功能: more命令和cat的功能一样都是查看文件里的内容,但有所不同的是more可以按页来查看文件的内容,还支持直接跳转行等功能。 命令参数: +n 从笫n行开始显示 -n 定义屏幕大小为n行 +/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示 -c 从顶部清屏,然后显示 -d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能 -l 忽略Ctrl+l(换页)字符 -p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似 -s 把连续的多个空行显示为一行 -u 把文件内容中的下画线去掉 常用操作命令: Enter 向下n行,需要定义。默认为1行 Ctrl+F 向下滚动一屏 空格键 向下滚动一屏 Ctrl+B 返回上一屏 = 输出当前行的行号 :f 输出文件名和当前行的行号 V 调用vi编辑器 !命令 调用Shell,并执行命令 q 退出more 使用实例: 实例1:显示文件中从第3行起的内容 命令: cat test.log #显示所有日志内容 more +3 test.log #从第三行开始显示日志内容 实例2.将日志内容设置为每屏显示4行 命令: more -4 test.log 实例3.从文件中查找第一个出现"liu"字符串的行,并从该处前两行开始显示输出 命令: more +/liu test.log 实例4.当一个目录下的文件内容太多,可以用more来分页显示。这得和管道 | 结合起来 命令: cat test.log | more -5 #“|”表示管道,作用是可以将前面命令的输出当做后面命令的输入 less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大。less 的用法比起 more 更加的有弹性。 在 more 的时候,我们并没有办法向前面翻, 只能往后面看,但若使用了 less 时,就可以使用 [pageup] [pagedown] 等按 键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。 命令格式: less [参数] 文件 命令功能: less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。 命令参数: -b <缓冲区大小> 设置缓冲区的大小 -e 当文件显示结束后,自动离开 -f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件 -g 只标志最后搜索的关键词 -i 忽略搜索时的大小写 -m 显示类似more命令的百分比 -N 显示每行的行号 -o <文件名> 将less 输出的内容在指定文件中保存起来 -Q 不使用警告音 -s 显示连续空行为一行 -S 行过长时间将超出部分舍弃 -x <数字> 将“tab”键显示为规定的数字空格 /字符串:向下搜索“字符串”的功能 ?字符串:向上搜索“字符串”的功能 n:重复前一个搜索(与 / 或 ? 有关) N:反向重复前一个搜索(与 / 或 ? 有关) b 向后翻一页 d 向后翻半页 h 显示帮助界面 Q 退出less 命令 u 向前滚动半页 y 向前滚动一行 空格键 滚动一行 回车键 滚动一页 [pagedown]: 向下翻动一页 [pageup]: 向上翻动一页 使用实例: 实例1:ps查看进程信息并通过less分页显示同时显示行号 命令: ps -ef|less -N 实例2.浏览多个文件 命令: less test2.log test.log 说明: 输入 :n后,切换到 test.log 输入 :p 后,切换到test2.log ps:当正在浏览一个文件时,也可以使用 :e命令 打开另一个文件。 命令: less file1 :e file2 附加备注 (1)全屏导航 ctrl + F - 向前移动一屏 ctrl + B - 向后移动一屏 ctrl + D - 向前移动半屏 ctrl + U - 向后移动半屏 (2)单行导航 j - 向前移动一行 k - 向后移动一行 (3)其它导航 G - 移动到最后一行 g - 移动到第一行 q / ZZ - 退出 less 命令 (4)其它有用的命令 v - 使用配置的编辑器编辑当前文件 h - 显示 less 的帮助文档 &pattern - 仅显示匹配模式的行,而不是整个文件 (5)标记导航 当使用 less 查看大文件时,可以在任何一个位置作标记,可以通过命令导航到标有特定标记的文本位置: ma - 使用 a 标记文本的当前位置 'a - 导航到标记 a 处 (6)查找 more, less 都具备查找功能,按/ 然后输入要找的字串,再按 Enter 即可,按 n(next) 会继续找,大写的 N 则是往回(上)找,按 q(quit)或者ZZ离开 3.head和tail(常用) head和tail通常使用在只需要读取文件的前几行或者后几行的情况下使用。head的功能是显示文件的前几行内容 head的语法:head [n number] 文件名 (number 显示行数) tail的功能恰好和head相反,只显示最后几行内容 tail的语法:tail [-n number] 文件名 查看日志文件的前1000行 1. head -n 1000 日志文件 查看日志文件最后1000行 tail -f -n 1000 日志文件 (实时打印最新的日志信息) tail -1000n 日志文件(实时打印最新的日志信息) tail -1000 日志文件(打印出日志文件的最后1000条信息) tail -n +1000 日志文件(从第1000行开始显示日志信息) 查看日志文件的中间多少行 cat 日志文件 | head -n 3000 | tail -n + 1001 4.nl (不常用) nl的功能和cat -n一样,同样是从第一行输出全部内容,并且把行号显示出来 nl的语法:nl 文件名
2.设计模式在编码过程中如何体现的
1、开闭原则:一个软件实体应当对扩展开放,对修改关闭。即软件实体应尽量在不修改原有代码的情况下进行扩展。a、抽象化的基本功能不变,不会被修改;b、把可变性的封装起来。 2、里氏转换原则:父类可以被子类代替。里氏转换原则是对开闭原则的一个补充,违反里氏转换原则就是违反开闭原则,并且是代理模式的基础。 使用时需注意以下几点: 1、子类必须实现父类所有方法; 2、尽量把父类设计成抽象类或接口; 3、依赖倒转原则:抽象类不依赖于细节,细节应当依赖于抽象,高层模块不应当依赖于底层模块,都依赖与抽象。
4、接口隔离原则:使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖于它不需要的那些接口; 5、迪米特原则:一个对象应尽可能少的了解其他对象。各个对象建的耦合度比较低,都能够独立运行; 6、聚合原则:用聚合类达到代码复用,而不是用继承关系来复用代码; 7、单一原则:一个类只负责一个功能领域的相应职责。
南京微小宝:
1.jsp内置对象各个作用
1、request对象 request 对象是 javax.servlet.httpServletRequest类型的对象。 该对象代表了客户端的请求信息,主要用于接受通过HTTP协议传送到服务器的数据。(包括头信息、系统信息、请求方式以及请求参数等)。request对象的作用域为一次请求。 2、response对象 response 代表的是对客户端的响应,主要是将JSP容器处理过的对象传回到客户端。response对象也具有作用域,它只在JSP页面内有效。 3、session对象 session 对象是由服务器自动创建的与用户请求相关的对象。服务器为每个用户都生成一个session对象,用于保存该用户的信息,跟踪用户的操作状态。session对象内部使用Map类来保存数据,因此保存数据的格式为 “Key/value”。 session对象的value可以使复杂的对象类型,而不仅仅局限于字符串类型。 4、application对象 application 对象可将信息保存在服务器中,直到服务器关闭,否则application对象中保存的信息会在整个应用中都有效。与session对象相比,application对象生命周期更长,类似于系统的“全局变量”。 5、out 对象 out 对象用于在Web浏览器内输出信息,并且管理应用服务器上的输出缓冲区。在使用 out 对象输出数据时,可以对数据缓冲区进行操作,及时清除缓冲区中的残余数据,为其他的输出让出缓冲空间。待数据输出完毕后,要及时关闭输出流。 6、pageContext 对象 pageContext 对象的作用是取得任何范围的参数,通过它可以获取 JSP页面的out、request、reponse、session、application 等对象。pageContext对象的创建和初始化都是由容器来完成的,在JSP页面中可以直接使用 pageContext对象。 7、config 对象 config 对象的主要作用是取得服务器的配置信息。通过 pageConext对象的 getServletConfig() 方法可以获取一个config对象。当一个Servlet 初始化时,容器把某些信息通过 config对象传递给这个 Servlet。 开发者可以在web.xml 文件中为应用程序环境中的Servlet程序和JSP页面提供初始化参数。 8、page 对象 page 对象代表JSP本身,只有在JSP页面内才是合法的。 page隐含对象本质上包含当前 Servlet接口引用的变量,类似于Java编程中的 this 指针。 9、exception 对象 exception 对象的作用是显示异常信息,只有在包含 isErrorPage="true" 的页面中才可以被使用,在一般的JSP页面中使用该对象将无法编译JSP文件。excepation对象和Java的所有对象一样,都具有系统提供的继承结构。exception 对象几乎定义了所有异常情况。在Java程序中,可以使用try/catch关键字来处理异常情况; 如果在JSP页面中出现没有捕获到的异常,就会生成 exception 对象,并把 exception 对象传送到在page指令中设定的错误页面中,然后在错误页面中处理相应的 exception 对象。
2.冒泡算法
1 public class MyBubbleSort { 2 3 public static void main(String[] args) { 4 int[] arr = {3, 2, 5, 1, 8, 1, 11, 8}; 5 int[] results = bubbleSort(arr); 6 for(int item : results){ 7 System.out.print(item + " "); 8 } 9 } 10 11 /** 12 * 冒泡排序,升序排列 13 * 数组当中比较小的数值向下沉,数值比较大的向上浮! 14 */ 15 public static int[] bubbleSort(int[] arr) { 16 // 外层for循环控制循环次数 17 for(int i=0;i<arr.length;i++){ 18 int tem = 0; 19 // 内层for循环控制相邻的两个元素进行比较 20 for(int j=i+1;j<arr.length;j++){ 21 if(arr[i]>arr[j]){ 22 tem = arr[j]; 23 arr[j]= arr[i]; 24 arr[i] = tem; 25 } 26 } 27 } 28 return arr; 29 } 30 }
南京实点实分网络科技:
1.JAVA序列化
----什么是序列化? --1--java序列化是指把java对象转换为字节序列的过程,而java反序列化是指把字节序列恢复为java对象的过程 --2--序列化:对象序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性。序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。序列化后的字节流保存的java对象的状态以及相关的描述信息。序列化机制的核心作用就是对象状态的保存与重建。 --3--反序列化:客户端从文件中或网络上获得序列化后的对象字节流后,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。 --4--序列化就是把实体对象状态按照一定的格式写入到有序字节流,反序列化就是从有序字节流重建对象,恢复对象状态 ----为什么需要序列化与反序列化 当两个进程进行远程通信时,可以相互发送各种类型的数据,包括文本,图片,音频,视频等,而这些数据都会以二进制的形式在网络上传送。 当两个java进行进行通信时,要传送对象,怎么传对象,通过序列化与反序列化。 也就是说,发送方需要把对象转换为字节序列,然后在网络上传送,另一方面,接收方需要从字节序列中恢复出java对象 ----序列化的好处 --1--永久性保存对象,保存对象的字节序列到本地文件或者数据库中,实现了数据的持久化,通过序列化可以把数据永久的保存到硬盘上, --2--利用序列化实现远程通信,可以在网络上传送对象的字节序列。 --3--在进程间传递对象 ----序列化算法步骤 --1--把对象实例相关的类元数据输出 --2--递归输出类的超类描述直到不再有超类 --3--类元数据完了以后,开始从最懂曾的超类开始输出对象实例的实际数据值。 --4--从上至下递归输出实例的数据 ----Java 如何实现序列化和反序列化 --1-- JDK类库中序列化API java.io.ObjectOutputStream: 表示输出对象流 它的writeObject(Object obj)方法可以对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中; --2--java.io.ObjectInputStream:表示对象输入流 它的readObject()方法源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回 --2--实现序列化的要求 只有实现了Serializable或Externalizable接口的对象才能被序列化,否则抛出异常! --3--实现java对象序列化与反序列化的方法 例 a 类,它的对象需要序列化,有3种方法 如果类a仅仅实现了Serializable接口,则 ObjectOutputStream采用默认的序列化方式,对a对象的非transient实例变量进行序列化 ObjectInputStream采用默认的反序列化方式,对a对象的非transient实例变量进行反序列化 如果类a仅仅实现了Serializable接口,并且还定义了a对象的writeObject(ObjectOutputStream out) 和readObject(ObjectInputStream in),则 ObjectOutputStream调用a对象的writeObject(ObjectOutputStream out)的方法进行序列化 ObjectInputStream调用a对象的readObject(ObjectInputStream in)的方法进行序列化 如果a类实现了ExternaInalizable接口,且User类必须实现readExternam(ObjectInput in)和wiriteExternal(ObjectOutput out)方法,则 ObjectOutputStream调用a对象的wiriteExternal(ObjectOutput out)的方法进行序列化 ObjectInputStream调用a对象的readExternam(ObjectInput in)的方法进行序列化‘’ ----JDK类库中序列化的步骤 --1--创建一个对象输出流,它可以包装一个奇特类型的目标输出流,如文件输出流: objectOutputStream oos=new objectOutputStream(new FileOutStream(c:\object.out)); --2--通过对象输出流writeObject()方法写对象: oos.writeObject(new a("xiaoxiao","145263","female")); ----JDK类库中反序列化的步骤 --1--创建一个对象输入流,它可以包装一个其他类型输入流,如文件输入流: objectInputStream ois=new ObjectInputStream(new FileInputStream("object.out")); --2--通过对象输出流的readObject()方法读取对象: a aa=(a)ois.readObject(); --3--为了正确读数据,完成反序列化,必须保证向对象输出流写对象的顺序与从对象输入流中读对象的顺序一致
2.如何以递归算法输出一个文件夹下的文件和文件目录
import java.io.File; public class TestFile { public static void main(String[] args) { File f=new File("D:\shixun"); printFile(f,0); } public static void printFile(File file,int level) { //打印树状的层次关系 for(int i=0;i<level;i++) { System.out.print("*"); } //输出目录或者文件的名字 System.out.println(file.getName()); if(file.isDirectory()) {//判断file是否为目录 File [] listFiles=file.listFiles(); for(File temp:listFiles) { //自己调用自己 printFile(temp,level+1); } } } }
3.Object的8种常用方法
getClass(), hashCode(), equals(), clone(), toString(), notify(), notifyAll(), wait(), finalize()
阿贝斯:
1.servlet的生命周期
Servlet 生命周期包括三部分: 1.初始化:Web 容器加载 servlet,调用 init()方法 2.处理请求:当请求到达时,运行其 service()方法。service()自动派遣运行与请求相对应的doXXX(doGet 或者 doPost)方法。 3.销毁:服务结束,web 容器会调用 servlet 的 distroy()方法销毁 servlet。
2.map有哪些是线程安全的
JAVA中线程安全的map有:Hashtable、synchronizedMap、ConcurrentHashMap。
java中map中线程安全怎么实现:
同步的map就是Hashtable, concurrenthashmap。
你看到的Hashtable就是直接在hashmap上加了个锁,concurrenthashmap就是分成多个分段锁。
java代码中线程安全级别:
绝对线程安全。
在任何环境下,调用者都不需要考虑额外的同步措施,都能够保证程序的正确性。
这个定义要求很严格,java里面满足这个要求的类比较少,对于实现jsr133规范(java内存模型)的jdk(一般指jdk5.0之上),一般的不变类都是满足绝地线程安全的。比如 String,Integer类。一般情况下,定义了如果一个类里面所有字段都是final类型的,一般都认为这个类是不变的。不变类都是绝对线程安全的。
相对线程安全
在一般情况下,调用者都不需要考虑线程同步,大多数情况下,都能够正常运行。jdk里面大多数类都是相对安全的。最常见的例子是java里面Vector类。
3.上传文件使用的什么类来接收
尚哲智能:
1.什么是事务,作用是什么
一个事务是有下列属性的一个工作单元: 原子性(ATOMICITY): 一个事务要被完全的无二义性的做完或撤消。在任何操作出现一个错误的情况下,构成事务的所有操作的效果必须被撤消,数据应被回滚到以前的状态。 一致性(CONSISTENCY): 一个事务应该保护所有定义在数据上的不变的属性(例如完整性约束)。在完成了一个成功的事务时,数据应处于一致的状态。换句话说,一个事务应该把系统从一个一致-状态转换到另一个一致状态。举个例子,在关系数据库的情况下, 一个一致的事务将保护定义在数据上的所有完整性约束。 隔离性(ISOLATION): 在同一个环境中可能有多个事务并发执行,而每个事务都应表现为独立执行。串行的执行一系列事务的效果应该同于并发的执行它们。这要求两件事: 在一个事务执行过程中,数据的中间的(可能不一致)状态不应该被暴露给所有的其他事务。 两个并发的事务应该不能操作同一项数据。数据库管理系统通常使用锁来实现这个特征。 持久性(DURABILITY): 一个被完成的事务的效果应该是持久的。
2.SQL优化的方案
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 5.in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3 6.下面的查询也将导致全表扫描: select id from t where name like '%abc%' 7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2 8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)='abc'--name以abc开头的id 应改为: select id from t where name like 'abc%' 9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。 10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引, 否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。 11.不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(...) 12.很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num) 13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引, 如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。 14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率, 因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。 一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。 15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。 这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。 16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间, 其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。 17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。 18.避免频繁创建和删除临时表,以减少系统表资源的消耗。 19.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。 20.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log , 以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。 21.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。 22.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。 23.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。 24.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。 在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。 25.尽量避免大事务操作,提高系统并发能力。26.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
3.JAVA的内存模型
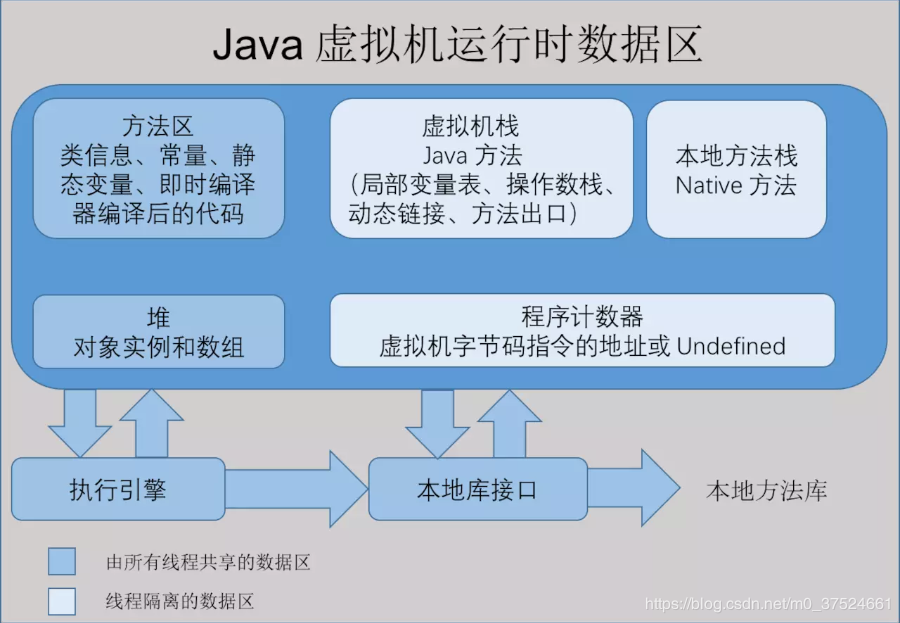
程序计数器:线程私有;记录指令执行的位置; 虚拟机栈:线程私有;生命周期和线程一致;存储局部变量表、操作数栈、动态链接、方法出口等信息。
本地方法栈:线程私有;为虚拟机使用到的 Native 方法服务。 堆:线程共享;JVM 所管理的内存中最大的一块区域,主要是存放对象实例和数组; 方法区:线程共享;存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
4.js中常用函数方法
1:常规写法 //函数的写法 function run{ alert("常规写法") //这里是你函数的内容 } //调用 run() 2:匿名函数写法 var run = function(){ alert("这是一种声明函数的写法,左边是一个变量,右边是一个函数的表达式, 意思就是把一个匿名函数的表达式赋值给了一个变量myrun,只是声明了一个变量指向了一个函数对象")//这里是你函数的内容 } run() 3:将方法作为一个对象 //作为对象方法,函数写法,这里创建了两个函数外面用{}包裹起来 var Text = { run1 : function(){ alert("这个必须放在一个对象内部,放在外边会出错")//这里是函数内容 }, run2 : function(){ alert("这个必须放在一个对象内部,放在外边会出错")//这里是函数内容 } } Text.run1()//调用第一个函数 Text.run2()//调用第二个函数 4.构造函数中给对象添加方法 javascript中的每个对象都有prototype属性,Javascript中对象的prototype属性的解释是:返回对象类型原型的引用。 // 给对象添加方法 var funName = function(){}; funName.prototype.way = function(){ alert('这是在funName函数上的原始对象上加了一个way方法,构造函数中用到'); } // 调用 var funname = new text();// 创建对象 funname.way();//调用对象属性 5.自执行函数 js自执行函数查到了几种不同写法,放上来给大家看看 //方法1:最前最后加括号 ( function(){alert(1);}() ); /*这是jslint推荐的写法,好处是,能提醒阅读代码的人,这段代码是一个整体。 例如,在有语法高亮匹配功能的编辑器里,光标在第一个左括号后时,最后一个右括号也会高亮,看代码的人一眼就可以看到这个整体。 */ //方法2:function外面加括号 (function(){alert(1);})(); //这种做法比方法1少了一个代码整体性的好处。 //方法3:function前面加运算符,常见的是!与void 。 !function(){alert(1);}(); void function(){alert(2);}();
5.如何使用异常,异常有哪些
从根本上讲所有的异常都属于Throwable的子类,从大的方面讲分为Error(错误)和Exception(异常)。Eror是程序无法处理的异常,当发生Error时程序线程会终止运行。我们一般意义上讲的异常就是指的Exception,这也是面试官常问的问题。 下面就简单说一下关于Exception(以下都简称异常)的一点理解。 异常分为运行时异常(RuntimeException,又叫非检查时异常)和非运行时异常(又叫检查异常)。下面列举一下常见的运行时异常: NullPointerException - 试图访问一空对象的变量、方法或空数组的元素 ArrayIndexOutOfBoundsException - 数组越界访问 NoClassDefFoundException - JAVA运行时系统找不到所引用的类 ArithmeticException - 算术运算中,被0除或模除 ArrayStoreException - 数据存储异常,写数组操作时,对象或数据类型不兼容 ClassCastException - 类型转换异常 IllegalArgumentException - 方法的参数无效 IllegalThreadStateException - 试图非法改变线程状态,比方说试图启动一已经运行的线程 NumberFormatException - 数据格式异常,试图把一字符串非法转换成数值(或相反) SecurityException - 如果Applet试图执行一被WWW浏览器安全设置所禁止的操作 IncompatibleClassChangeException - 如改变了某一类定义,却没有重新编译其他引用了这个类的对象。如某一成员变量的声明被从静态改变为非静态,但其他引用了这个变量的类却没有重新编译,或者相反。如删除了类声明中的某一域或方法,但没有重新编译那些引用了这个域或方法的类 OutOfMemoryException - 内存不足,通常发生于创建对象之时 IncompatibleTypeException - 试图实例化一个接口,Java运行时系统将抛出这个异常 UnsatisfiedLinkException - 如果所需调用的方法是C函数,但Java运行时系统却无法连接这个函数 InternalException - 系统内部故障所导致的异常情况,可能是因为Java运行时系统本身的原因。如果发现一可重现的InternalException,可以直接给Sun公司发电邮。
6.spring中AOP和IOC
IOC:控制反转也叫依赖注入。利用了工厂模式 将对象交给容器管理,你只需要在spring配置文件总配置相应的bean,以及设置相关的属性,让spring容器来生成类的实例对象以及管理对象。在spring容器启动的时候,spring会把你在配置文件中配置的bean都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些bean分配给你需要调用这些bean的类(假设这个类名是A),分配的方法就是调用A的setter方法来注入,而不需要你在A里面new这些bean了。 注意:面试的时候,如果有条件,画图,这样更加显得你懂了. AOP:面向切面编程。(Aspect-Oriented Programming) AOP可以说是对OOP的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。 将程序中的交叉业务逻辑(比如安全,日志,事务等),封装成一个切面,然后注入到目标对象(具体业务逻辑)中去。 实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码.
7.JDK1.8有什么新特性
1、default关键字
2、Lambda 表达式
3、函数式接口
4.方法与构造函数引用
5、局部变量限制
6、Date Api更新
7、流
江苏金茂电子商务:
1.JAVA如何实现一个账号只能一个用户登录,其他人无法登录
1 .在用户登录时,把用户添加到一个ArrayList中 2 .再次登录时查看ArrayList中有没有该用户,如果ArrayList中已经存在该用户,则阻止其登录 3 .当用户退出时,需要从该ArrayList中删除该用户,这又分为三种情况 ① 使用注销按钮正常退出 ② 点击浏览器关闭按钮或者用Alt+F4退出,可以用JavaScript捕捉该页面关闭事件, 执行一段Java方法删除ArrayList中的用户 ③ 非正常退出,比如客户端系统崩溃或突然死机,可以采用隔一段时间session没活动就删除该session所对应的用户来解决,这样用户需要等待一段时间之后就可以正常登录。
2.SQL查询一张表中重复数据的方法
1.查询出所有数据进行分组之后,和重复数据的重复次数的查询数据,先列下: select count(username) as '重复次数',username from xi group by username having count(*)>1 order by username desc 2.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) 3.查找表中多余的重复记录(多个字段) select * from people a where (a.peopleId,a.seq) in (select peopleId,seq from people group by peopleId,seq having count(*) > 1)
3.如何实现批量更新
--创建表 create table test1 ( a varchar2(100), b varchar2(100) ); create table test2 ( a varchar2(100), b varchar2(100) ); --插入语句 declare i number; begin for i in 1..10 loop insert into test1(a,b)values(i,i); end loop; for i in 1..5 loop insert into test2(a,b)values(i,i||i); end loop; end; --查询一下: select t.*,t.rowid from test1 t select t.*,t.rowid from test2 t --全都更新的方式: update test1 t1 set t1.b = (select t2.b from test2 t2 where t1.a = t2.a) --如果没有以下语句结果就不一样了,请注意 where exists (select '' from test2 t2 where t1.a = t2.a); --开始批量更新 declare countpoint number := 0; begin for row_id in (select t1.rowid,t2.b from test1 t1,test2 t2 where t1.a = t2.a) loop update test1 t1 set t1.b = row_id.b where t1.rowid = row_id.rowid; countpoint := countpoint + 1; if mod(countpoint, 5) = 0 then dbms_output.put_line('countpoint:' || countpoint); commit; end if; end loop; commit; end; --删除数据 delete test1; delete test2; --删除表 drop table test1; drop table test2;
4.Switch函数中放什么类型的参数
jdk1.7以前的版本switch(expr1)中,expr1是一个整数表达式,整数表达式可以是int基本类型或Integer包装类型,由于,byte,short,char都可以隐含转换为int,
所以,这些类型以及这些类型的包装类型也是可以的。因此传递给 switch 和case 语句的参数应该是 int、 short、 char 或者 byte,还有enum。 long,string 都不能作用于swtich。 在jdk 1.7中switch的参数类型可以是字符串类型。
南京数族公司:
1.java容器有哪些
数组,String,java.util下的集合容器
数组长度限制为 Integer.Integer.MAX_VALUE;
String的长度限制: 底层是char 数组 长度 Integer.MAX_VALUE 线程安全的
List:存放有序,列表存储,元素可重复
Set:无序,元素不可重复
Map:无序,元素可重复
2.第三方支付接口用过没讲一讲
3.hashtable和hashmap的区别
1、继承的父类不同 Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。 2、线程安全性不同 javadoc中关于hashmap的一段描述如下:此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。 Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,
但使用HashMap时就必须要自己增加同步处理。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)
这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,
以防止对映射进行意外的非同步访问。
Map m = Collections.synchronizedMap(new HashMap(...)); Hashtable 线程安全很好理解,因为它每个方法中都加入了Synchronize。这里我们分析一下HashMap为什么是线程不安全的: HashMap底层是一个Entry数组,当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的头结点。对链表而言,新加入的节点会从头结点加入。
4.redis持久化
RDB 持久化:该机制可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。 AOF 持久化:记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件 进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小 无持久化:让数据只在服务器运行时存在。 同时应用 AOF 和 RDB:当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的 数据集通常比 RDB 文件所保存的数据集更完整
5.hashmap线程不安全,如何使他安全
6.token存redis时,redis崩溃怎么办
7.mycat分库分表
1、分区 对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm。 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表呢,还是一张表。分区可以把表分到不同的硬盘上,但不能分配到不同服务器上。 优点:数据不存在多个副本,不必进行数据复制,性能更高。 缺点:分区策略必须经过充分考虑,避免多个分区之间的数据存在关联关系,每个分区都是单点,如果某个分区宕机,就会影响到系统的使用。 2、分片 对业务透明,在物理实现上分成多个服务器,不同的分片在不同服务器上。如HDFS。 3、分表 同库分表:所有的分表都在一个数据库中,由于数据库中表名不能重复,因此需要把数据表名起成不同的名字。 优点:由于都在一个数据库中,公共表,不必进行复制,处理更简单。 缺点:由于还在一个数据库中,CPU、内存、文件IO、网络IO等瓶颈还是无法解决,只能降低单表中的数据记录数。表名不一致,会导后续的处理复杂(参照mysql meage存储引擎来处理) 不同库分表:由于分表在不同的数据库中,这个时候就可以使用同样的表名。 优点:CPU、内存、文件IO、网络IO等瓶颈可以得到有效解决,表名相同,处理起来相对简单。 缺点:公共表由于在所有的分表都要使用,因此要进行复制、同步。一些聚合的操作,join,group by,order等难以顺利进行。 4、分库 分表和分区都是基于同一个数据库里的数据分离技巧,对数据库性能有一定提升,但是随着业务数据量的增加,原来所有的数据都是在一个数据库上的,
网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。 当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等。此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。 分库只是一个通俗说法,更标准名称是数据分片,采用类似分布式数据库理论指导的方法实现,对应用程序达到数据服务的全透明和数据存储的全透明
8.linux常用命令
https://blog.csdn.net/qq_23329167/article/details/83856430
9.springmvc工作原理和注解
1、 用户发送请求至前端控制器DispatcherServlet。 2、 DispatcherServlet收到请求调用HandlerMapping处理器映射器。 3、 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。 4、 DispatcherServlet调用HandlerAdapter处理器适配器。 5、 HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。 6、 Controller执行完成返回ModelAndView。 7、 HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。 8、 DispatcherServlet将ModelAndView传给ViewReslover视图解析器。 9、 ViewReslover解析后返回具体View。 10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。 11、 DispatcherServlet响应用户。
10.springboot常用注解
1、@Component:放在类上,把普通类实例化到spring容器中。可以说很多注解都是基于这个注解的。 2、@Bean: 放在方法上,用@Bean标注方法等价于XML中配置bean,这个方法一般返回一个实体对象,告诉spring这里产生一个对象,然后这个对象会交给Spring管理。产生这个对象的方法Spring只会调用一次,随后这个Spring将会将这个Bean对象放在自己的容器中。 3、@Configuration:标注当前类是配置类,并会将当前类内声明的一个或多个以@Bean注解标记的方法的实例纳入到srping容器中,并且实例名就是方法名。(其实就是靠@Component注解) 4、@ConfigurationProperties:将配置文件中的参数映射成一个对象,通过prefix来设定前缀,然后将后面的和对象的属性名一致就能实现注入(当然这个对象需要注入的属性需要提供get和set方法 - - - 因为spring底层其实就是通过反射调用该对象的set方法)
11.zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。 ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。 ZooKeeper包含一个简单的原语集, [1] 提供Java和C的接口。 ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_homesrc ecipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
家哇网络:
1.ArrayList和LinkedList的区别
ArrayList 是动态数组结构,有索引,查询快(时间复杂度O(1)),增删慢(因为要移动索引)
LinkedList是链表结构,无索引,有指向前后的指针,查询需要从头开始向下寻找(时间复杂度O(n)),增删快(只需要修改链表中指针的指向,不需要移动其他)
2.requestBody和resourceBody的作用
@RequestBody:
作用:
主要用来接收前端传递给后端的json字符串中的数据的(请求体中的数据的);
3.如何实现上传文件
4.JAVA如何实现定时任务
普通thread
这是最常见的,创建一个thread,然后让它在while循环里一直运行着,通过sleep方法来达到定时任务的效果。这样可以快速简单的实现。
用Timer和TimerTask
上面的实现是非常快速简便的,但它也缺少一些功能。
用Timer和TimerTask的话与上述方法相比有如下好处:
当启动和去取消任务时可以控制
第一次执行任务时可以指定你想要的delay时间
在实现时,Timer类可以调度任务,TimerTask则是通过在run()方法里实现具体任务。
Timer实例可以调度多任务,它是线程安全的。
当Timer的构造器被调用时,它创建了一个线程,这个线程可以用来调度任务:
ScheduledExecutorService
ScheduledExecutorService是从Java SE 5的java.util.concurrent里,做为并发工具类被引进的,这是最理想的定时任务实现方式。
相比于上两个方法,它有以下好处:
相比于Timer的单线程,它是通过线程池的方式来执行任务的
可以很灵活的去设定第一次执行任务delay时间
提供了良好的约定,以便设定执行的时间间
5.文件流有哪些
字节流和字符流