spark streaming项目 学习笔记

为什么要flume+kafka?
生成数据有高峰与低峰,如果直接高峰数据过来flume+spark/storm,实时处理容易处理不过来,扛不住压力。而选用flume+kafka添加了消息缓冲队列,spark可以去kafka里面取得数据,那么就可以起到缓冲的作用。
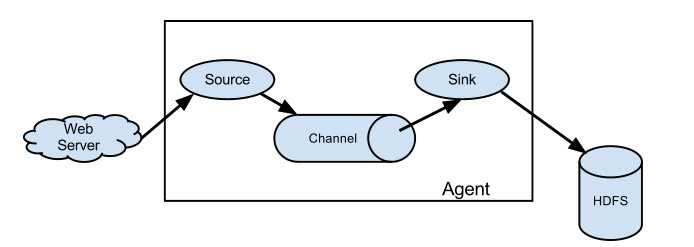
Flume架构:
参考学习:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
启动一个agent:
bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
添加example.conf:
|
# example.conf: A single-node Flume configuration
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1
# Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444
# Describe the sink a1.sinks.k1.type = logger
# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
开一个终端测试:
|
$ telnet localhost 44444 T Trying 127.0.0.1... C Connected to localhost.localdomain (127.0.0.1). E Escape character is '^]'. H Hello world! <ENTER> O OK |
Flume将会输出:
|
12/06/19 15:32:19 INFO source.NetcatSource: Source starting 12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444] 12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. } |
<二> kafka架构
producer:生产者
consumer:消费者
broker:缓冲代理
topic:主题
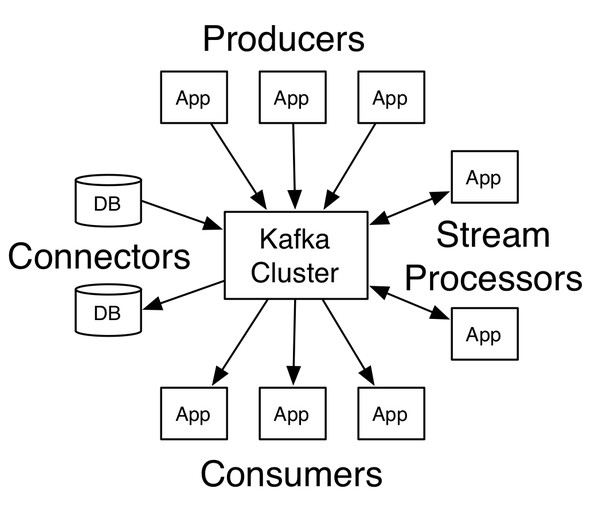
安装:
下载->解压->修改配置
添加环境变量:
|
$ vim ~/.bash_profile ……
export ZK_HOME=/home/centos/develop/zookeeper export PATH=$ZK_HOME/bin/:$PATH
export KAFKA_HOME=/home/centos/develop/kafka export PATH=$KAFKA_HOME/bin:$PATH |
启动zk:
zkServer.sh start
查看zk状态:
zkServer.sh status
|
$ vim config/server.properties: #需要修改配置内容 broker.id=1 listeners=PLAINTEXT://:9092 log.dirs=/home/centos/app/kafka-logs |
后台启动kafka:
nohup kafka-server-start.sh $KAFKA_HOME/config/server.properties &
创建topic:
kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 1 --topic halo
-- 注:这里2181是zk端口
查看topic列表:
kafka-topics.sh --list --zookeeper node1:2181
-- 注:这里2181是zk端口
生产一个主题halo:
kafka-console-producer.sh --broker-list node1:9092 --topic halo
-- 注:这里9092是kafka端口
消费主题halo数据:
kafka-console-consumer.sh --zookeeper node1:2181 --topic halo --from-beginning
Setting up a multi-broker cluster
复制server.properties :
|
> cp config/server.properties config/server-1.properties > cp config/server.properties config/server-2.properties |
编辑内容:
|
config/server-1.properties: broker.id=1 listeners=PLAINTEXT://:9093 log.dirs=/home/centos/app/kafka-logs-1
config/server-2.properties: broker.id=2 listeners=PLAINTEXT://:9094 log.dirs=/home/centos/app//kafka-logs-2 |
现在后台启动broker:
|
>nohup kafka-server-start.sh $KAFKA_HOME/config/server-1.properties & ... >nohup kafka-server-start.sh $KAFKA_HOME/config/server-2.properties & ... |
现在我们创建一个具有三个副本的主题:
|
> bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 3 --partitions 1 --topic replicated-halo |
好了,我们查看下topic主题下详细信息
|
> bin/kafka-topics.sh --describe --zookeeper node1:2181 --topic replicated-halo Topic:replicated-halo PartitionCount:1 ReplicationFactor:3 Configs: Topic: replicated-halo Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0 |
- "leader" is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
- "replicas" is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive.
- "isr" is the set of "in-sync" replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.
【附:jps -m显示具体的进程信息】
一个kafka生产栗子:
package com.lin.spark.kafka; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; import java.util.Properties; /** * Created by Administrator on 2019/6/1. */ public class KafkaProducer extends Thread { private String topic; private Producer<Integer, String> producer; public KafkaProducer(String topic) { this.topic = topic; Properties properties = new Properties(); properties.put("metadata.broker.list", KafkaProperities.BROKER_LIST); properties.put("serializer.class", "kafka.serializer.StringEncoder"); properties.put("request.required.acks", "1"); producer = new Producer<Integer, String>(new ProducerConfig(properties)); } @Override public void run() { int messageNo = 1; while (true) { String message = "message_" + messageNo; producer.send(new KeyedMessage<Integer, String>(topic,message)); System.out.println("Send:"+message); messageNo++; try{ Thread.sleep(2000);//2秒钟打印一次 }catch (Exception e){ e.printStackTrace(); } } } //测试 public static void main(String[] args){ KafkaProducer producer = new KafkaProducer("halo"); producer.run(); } }
测试消费的数据:
> kafka-console-consumer.sh --zookeeper node1:2181 --topic halo --from-beginning

对应的消费者代码:
package com.lin.spark.kafka; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; /** * Created by Administrator on 2019/6/2. */ public class KafkaConsumer extends Thread { private String topic; public KafkaConsumer(String topic) { this.topic = topic; } private ConsumerConnector createConnector(){ Properties properties = new Properties(); properties.put("zookeeper.connect", KafkaProperities.ZK); properties.put("group.id",KafkaProperities.GROUP_ID); return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties)); } @Override public void run() { ConsumerConnector consumer = createConnector(); Map<String,Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(topic,1); Map<String, List<KafkaStream<byte[], byte[]>>> streams = consumer.createMessageStreams(topicCountMap); KafkaStream<byte[], byte[]> kafkaStream = streams.get(topic).get(0); ConsumerIterator<byte[], byte[]> iterator = kafkaStream.iterator(); while (iterator.hasNext()){ String result = new String(iterator.next().message()); System.out.println("result:"+result); } } public static void main(String[] args){ KafkaConsumer kafkaConsumer = new KafkaConsumer("halo"); kafkaConsumer.run(); } }
一个简单kafka与spark streaming整合例子:
启动kafka,并生产数据
> kafka-console-producer.sh --broker-list 172.16.182.97:9092 --topic halo
参数固定:
package com.lin.spark import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object KafkaStreaming { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkStreamingKakfaWordCount").setMaster("local[4]") val ssc = new StreamingContext(conf,Seconds(5)) val topicMap = "halo".split(":").map((_, 1)).toMap val zkQuorum = "hadoop:2181"; val group = "consumer-group" val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) lines.print() ssc.start() ssc.awaitTermination() } }
参数输入:
package com.lin.spark import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object KafkaStreaming { def main(args: Array[String]): Unit = { if (args.length != 4) { System.err.println("参数不对") } //args: hadoop:2181 consumer-group halo,hello_topic 2 val Array(zkQuorum, group, topics, numThreads) = args val conf = new SparkConf().setAppName("SparkStreamingKakfaWordCount").setMaster("local[4]") val ssc = new StreamingContext(conf, Seconds(5)) val topicMap = topics.split(",").map((_,numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) lines.print() ssc.start() ssc.awaitTermination() } }