1、什么是深度分页
深度分页其实就是搜索的深浅度,比如第1页,第2页,第10页,第20页,是比较浅的;第10000页,第20000页就是很深了。
假设我们要搜索9999到10009的10条数据
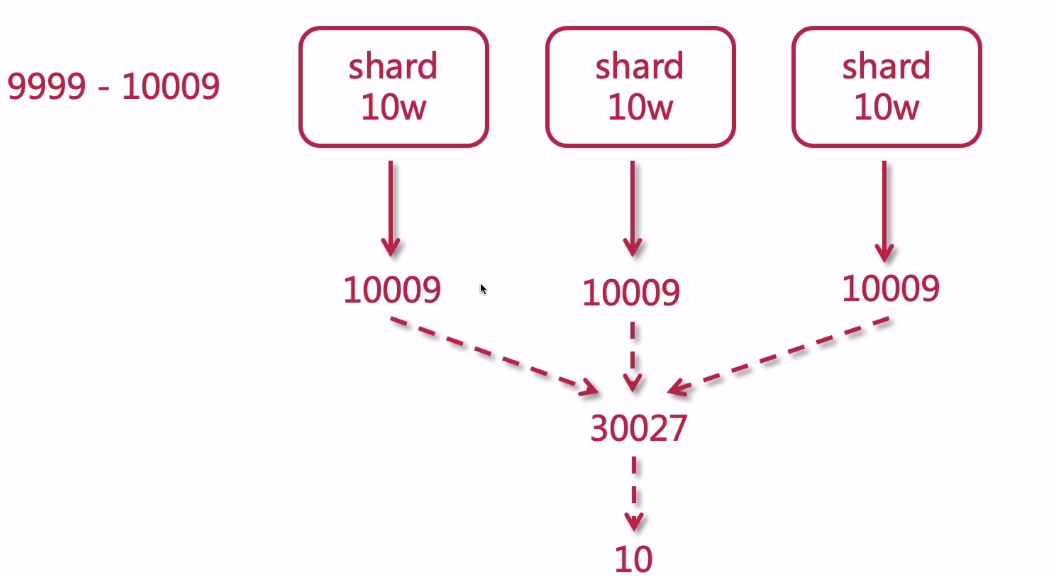
假设shard数有3个,每个shard有10万条数据
如此一来,搜索得太深,就会造成性能问题,会消耗内存和占用CPU。而且影响ES的性能。ES不支持10000条以上分页查询。
那么如何解决深度搜索带来的问题呢?
比如最多只能提供100页的数据,第101页的数据就没有了,毕竟用户不会搜索的那么深。比如淘宝的搜索,最多只显示100页。
2、深度搜索9999到10009

可以发现,请求的数据条数太多了,默认最多返回10000条数据。
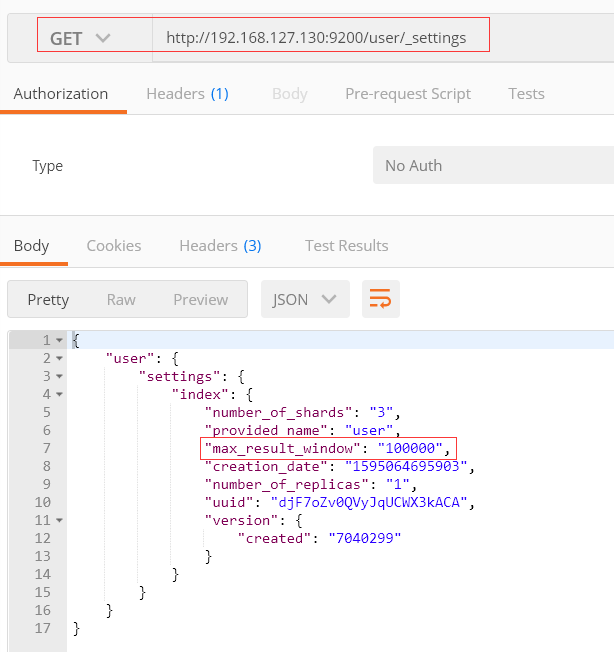
3、提升搜索量
修改最多10000条数据限制

可以看到,设置我10万已经成功
4、滚动搜索
1) 首次搜索
每页显示5条, 1m: 保持游标查询窗口1分钟
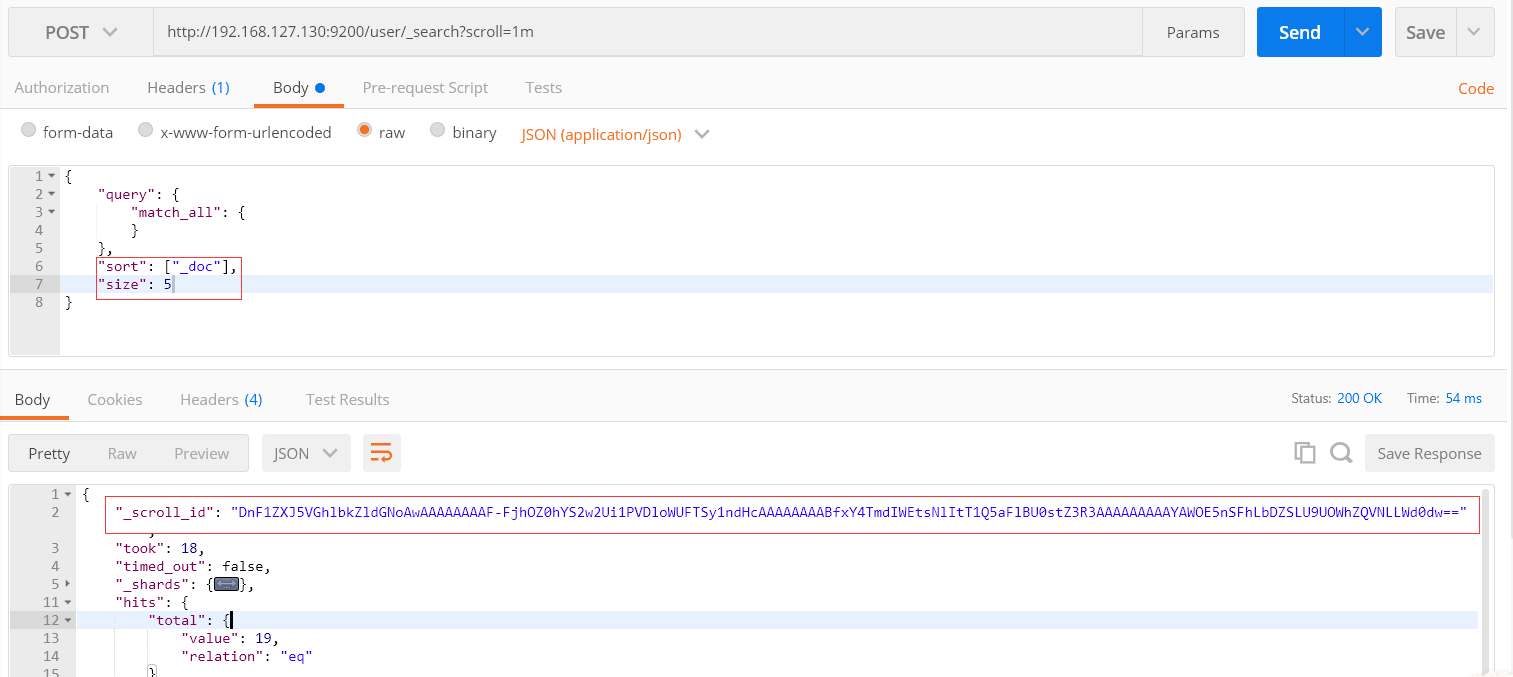
第二次搜索。
把上一次的scroll_id 赋值到本次scroll_id的值,时间是1分钟,如果过期了,首次搜索再调再调用1次。

优点: 解决了深度搜索的性能问题
缺点:滚动搜索有一个快照的概念,当数据更新时,不会马上在滚动搜索里显示。
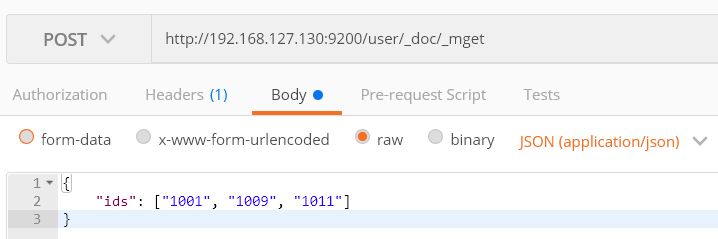
5、批量搜索
_mget
6 、批量操作 bulk
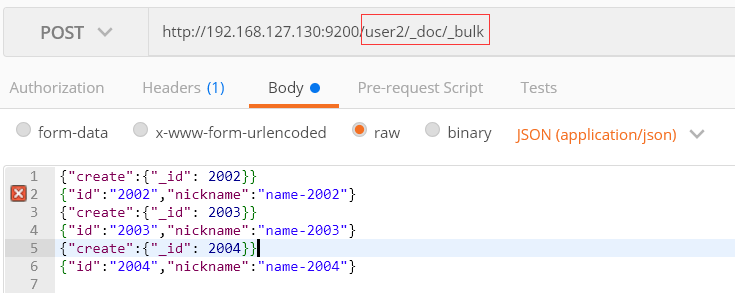
向user2批量添加数据

JSON内容为
{"create":{"_index":"user2","_type":"_doc","_id": 2002}}
{"id":"2002","nickname":"name-2002"}
{"create":{"_index":"user2","_type":"_doc","_id": 2003}}
{"id":"2003","nickname":"name-2003"}
{"create":{"_index":"user2","_type":"_doc","_id": 2004}}
{"id":"2004","nickname":"name-2004"}
上面的批量添加可以将index和type提取到url
index: 已经有了,进行修改; 否则,进行添加
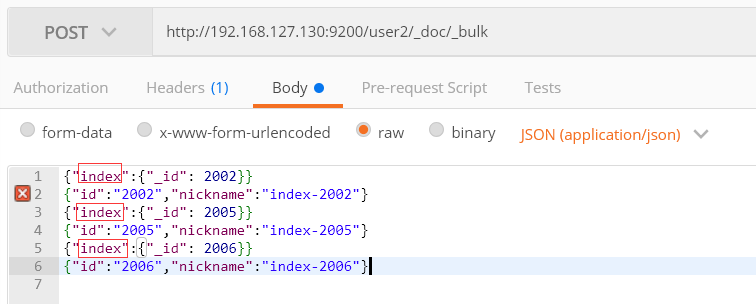
因为2002已经存在,则进行修改操作; 2005和2006没有,则进行添加操作。