httplib模块实现了HTTP和HTTPS的客户端部分,但是一般不直接使用,经常通过urllib来进行HTTP,HTTPS的相关操作。
如果需要查看其源代码可以通过查找命令定位:
find / -name "httplib.py"
整个请求过程的状态转移图如下所示:

httplib提供如下的类:
1. httplib.HTTPConnection(host[, port[, strict[, timeout[, source_address]]]])
一个HTTPConnection实例表示一次与HTTP server的连机事务,在实例化的时候至少需要一个主机地址。port参数如果没有指定会默认采用80端口。strict参数的默认值是false,当这个值为true的时候,如果状态行(status line)不是HTTP/1.0 or 1.1,则会引发BadStatusLine错误。timeout参数指定在多长时间后还未连接到主机则停止此联机行为。source_address参数是二元组形式(host,port),指定发起连接的客户机的IP和端口。
>>> h1 = httplib.HTTPConnection('www.cwi.nl') >>> h2 = httplib.HTTPConnection('www.cwi.nl:80') >>> h3 = httplib.HTTPConnection('www.cwi.nl', 80) >>> h3 = httplib.HTTPConnection('www.cwi.nl', 80, timeout=10)
其包含如下几个方法:
1.1 HTTPConnection.request(method, url[, body[, headers]])
以method方法来访问url地址,body参数可以是需要发送的数据字符串,还可以是文件对象,其将会在发送完headers之后发送出去。headers参数对应HTTP headers中需要的内容。如果headers参数没有指定,则headers中的Content-Length会根据body的大小自动添加(字符串的长度或者是文件的大小)。
1.2 HTTPConnection.getresponse()
一般在调用request之后用来获取返回结果,此方法返回一个HTTPResponse对象。
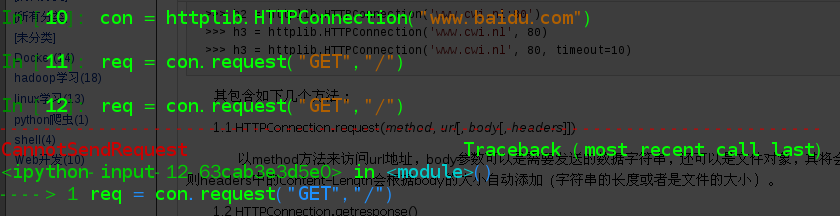
注意: 在发送一个新的请求之前要先读取返回的结果,否则会出错。源文件中对应的部分如下:
# Note: if a prior response exists, then we *can* start a new request. # We are not allowed to begin fetching the response to this new # request, however, until that prior response is complete. # if self.__state == _CS_IDLE: self.__state = _CS_REQ_STARTED else: raise CannotSendRequest()
测试实例:
1.3 HTTPConnection.set_debuglevel(level)
设置调试级别(相关的调试信息会打印出来),默认值是0,表示不打印调试信息。
In [14]: con = httplib.HTTPConnection("www.baidu.com") In [15]: con.set_debuglevel(1) # 请求过程中会输出一些调式信息 In [16]: req = con.request("GET","/") send: 'GET / HTTP/1.1 Host: www.baidu.com Accept-Encoding: identity '
1.4 HTTPConnection.connect()
当HTTPConnection对象创建的时候自动连接到服务器
1.5 HTTPConnection.close()
你懂的
你除了直接调用request()方法来访问服务器,还可以以下边4步实现此功能:
1.6.1 HTTPConnection.putrequest(request, selector[, skip_host[, skip_accept_encoding]]):
这是连接到服务器之后的第一步操作
1.6.2 HTTPConnection.putheader(header, argument[, ...])
发送请求头
1.6.3 HTTPConnection.endheaders(message_body=None)
向服务器发送一空行表示请求头的结束。
1.6.4 HTTPConnection.send(data)
向服务器发送数据。应该在endheaders函数调用之后,getresponse函数之前调用。
2. httplib.HTTPSConnection(host[, port[, key_file[, cert_file[, strict[, timeout[, source_address[, context]]]]]]])
这是HTTPConnection的一个子类,通过SSL来和安全主机交互,采用的默认端口是443.如果参数context指定时候,这其此参数必须是ssl.SSLContext(描述SSL的各种信息)的实例。
key_file和cert_file参数已经弃用。
3. httplib.HTTPResponse(sock, debuglevel=0, strict=0)
这个类会在成功连接后返回,不会被用户直接初始化。
HTTPResponse.read([amt]):
返回响应结果,或者读取下amt个字节
In [23]: response = con.getresponse() In [24]: response.read(10) Out[24]: '<!DOCTYPE '
HTTPResponse.getheader(name[, default])
获取指定文件头中指定的内容
In [26]: response.getheader("server") Out[26]: 'BWS/1.1' In [27]: response.getheader("date") Out[27]: 'Mon, 17 Oct 2016 10:59:40 GMT' In [28]: response.getheader("Date") Out[28]: 'Mon, 17 Oct 2016 10:59:40 GMT'
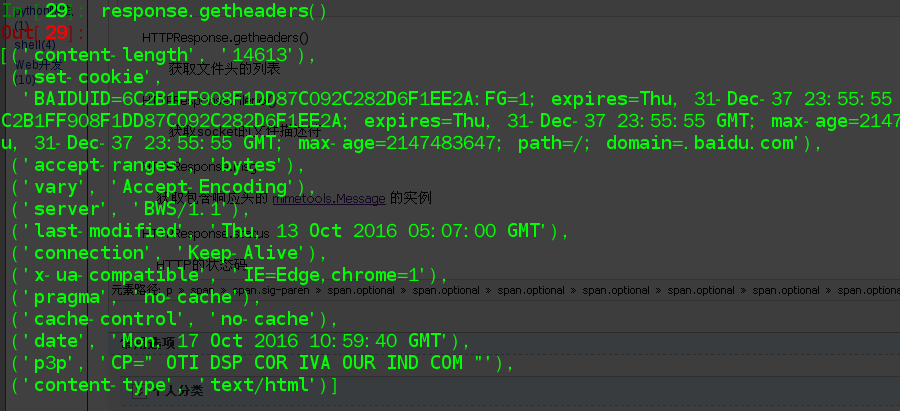
HTTPResponse.getheaders()
获取文件头的列表
HTTPResponse.fileno()
获取socket的文件描述符
HTTPResponse.msg-
获取包含响应头的
mimetools.Message的实例In [30]: message = response.msg In [31]: message Out[31]: <httplib.HTTPMessage instance at 0x39610e0>
# 获取响应头信息
In [33]: dict = message.dict In [34]: dict Out[34]: {'accept-ranges': 'bytes', 'cache-control': 'no-cache', 'connection': 'Keep-Alive', 'content-length': '14613', 'content-type': 'text/html', 'date': 'Mon, 17 Oct 2016 10:59:40 GMT', 'last-modified': 'Thu, 13 Oct 2016 05:07:00 GMT', 'p3p': 'CP=" OTI DSP COR IVA OUR IND COM "', 'pragma': 'no-cache', 'server': 'BWS/1.1', 'set-cookie': 'BAIDUID=6C2B1FF908F1DD87C092C282D6F1EE2A:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, BIDUPSID=6C2B1FF908F1DD87C092C282D6F1EE2A; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, PSTM=1476701980; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com', 'vary': 'Accept-Encoding', 'x-ua-compatible': 'IE=Edge,chrome=1'}
HTTPResponse.status
HTTP的状态码
HTTPResponse.reason
In [35]: response.reason Out[35]: 'OK'
4. httplib.HTTPMessage
这个类中存储HTTP的响应头信息。其通过 mimetools.Message实现,并提供处理头的使用函数,不会被用户实例化。
参考地址: https://docs.python.org/2/library/httplib.html#httplib.HTTPSConnection