1.利用Redis缓存实现商品分类查询
1.1 编辑ItemCatController
@RequestMapping("/list")
public List<EasyUITree> findItemCatList(Long id){
Long parentId = (id==null?0L:id); //根据parentId=0 查询一级商品分类信息
//Long parentId = 0L;
//return itemCatService.findItemCatListByParentId(parentId); //版本号 1.0.2 调用次方法 开发人员为xxxx
return itemCatService.findItemCatCache(parentId);
}
1.2 编辑ItemCatService
package com.jt.service;
@Override
public List<EasyUITree> findItemCatListByParentId(Long parentId){
QueryWrapper<ItemCat> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("parent_id",parentId);
List<ItemCat> itemCatList = itemCatMapper.selectList(queryWrapper);
List<EasyUITree> treeList = new ArrayList<>(); //先准备一个空集合.
//需要将数据一个一个的格式转化.
for(ItemCat itemcat : itemCatList){
Long id = itemcat.getId(); //获取ID
String text = itemcat.getName(); //获取文本
//如果是父级,则默认应该处于关闭状态 closed, 如果不是父级 则应该处于打开状态. open
String state = itemcat.getIsParent()?"closed":"open";
//利用构造方法 为VO对象赋值 至此已经实现了数据的转化
EasyUITree tree = new EasyUITree(id,text,state);
treeList.add(tree);
}
//用户需要返回List<EasyUITree>
return treeList;
}
@Override
public List<EasyUITree> findItemCatCache(Long parentId) {
//1.准备key
String key = "ITEM_CAT_LIST::" + parentId;
List<EasyUITree> treeList = new ArrayList<>();
Long startTime = System.currentTimeMillis(); //记录开始时间
//2.判断redis中是否有数据
if(jedis.exists(key)){
//表示key已存在不是第一次查询.直接从redis中获取数据.返回数据
String json = jedis.get(key);
treeList = ObjectMapperUtil.toObject(json, treeList.getClass());
Long endTime = System.currentTimeMillis();
System.out.println("查询缓存的时间为:"+(endTime-startTime)+"毫秒");
}else{
//表示key不存在,执行数据库查询
treeList = findItemCatListByParentId(parentId);
Long endTime = System.currentTimeMillis();
System.out.println("查询数据库的时间为:"+(endTime-startTime)+"毫秒");
//2.将数据转化为json
String json = ObjectMapperUtil.toJSON(treeList);
//3.将返回值结果,保存到redis中. 是否需要设定超时时间?? 根据业务
jedis.set(key, json);
}
return treeList;
}
2.利用AOP实现redis缓存
2.1 传统项目弊端
说明:
1).由于将redis的操作写到service层中,必须导致业务的耦合性高
2).如果采用上述的方式完成缓存,则改缓存不通用,并且代码冗余.效率低.
2.2 AOP的核心理念
公式: AOP = 切入点表达式 + 通知方法

2.3 切入点表达式
1). bean(bean的ID) 按照指定的bean名称拦截用户的请求,之后执行通知方法. 只能匹配单个bean对象
2).within(包名.类名) 可以按照类通配的方式去拦截用户的请求. 控制粒度较粗.
3).execution(返回值类型 包名.类名.方法名(参数列表)) 方法参数级别 控制粒度较细
4).@annotation(包名.注解名称) 按照注解的方式去拦截用户请求.
2.4 通知方法
1.前置通知: 主要在 目标方法执行之前执行
2.后置通知: 在目标方法执行之后执行
3.异常通知: 在目标方法执行的过程中报了异常之后执行.
4.最终通知: 无论什么时候都要执行的通知方法.
上述的通知方法,无法控制目标方法是否执行.所以一般"只做记录不做改变"
5.环绕通知: 一般采用环绕通知 实现对业务的控制.
2.5 AOP入门案例
package com.jt.aop;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Component //标识为一个javaBean
@Aspect //标识为一个切面
public class CacheAOP {
//1.定义切入点表达式
@Pointcut("bean(itemCatServiceImpl)") //只拦截xxx类中的方法
public void pointCut(){ }
/**
* 2.定义通知方法
* 需求:
* 1.想获取目标方法名称
* 2.获取目标方法对象
* 3.获取用户传递的参数
*/
@Before("pointCut()")
public void before(JoinPoint joinPoint){
System.out.println("我是前置通知");
//1.获取类名称
String className = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
//2.获取对象
Object target = joinPoint.getTarget();
//3.获取参数
Object[] objs = joinPoint.getArgs();
System.out.println("类名名称:"+className);
System.out.println("方法名称:"+methodName);
System.out.println("对象名称:"+target);
System.out.println("方法参数:"+objs);
}
}
2.6 AOP实现缓存业务
2.6.1 自定义注解@CacheFind
说明:该注解由于使用的业务较多,所以将改注解写入Common中.
package com.jt.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(value = RetentionPolicy.RUNTIME)//标识运行时有效
@Target(ElementType.METHOD)//标识作用于方法上
public @interface CacheFind {
//1.设定key
public String key();
//2.超时时间
public int seconds() default 0;
}
2.6.2 使用自定义注解

2.6.3 切换代码执行
在尽可能不改变源码的基础上,进行功能的扩展

2.7 利用AOP实现缓存业务
package com.jt.aop;
import com.jt.annotation.CacheFind;
import com.jt.utils.ObjectMapperUtils;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.Signature;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
import java.lang.reflect.Method;
import java.util.Arrays;
import java.util.List;
@Component //标识为一个javaBean
@Aspect //标识为一个切面
public class CacheAOP {
//注入redis配置
@Autowired
private Jedis jedis;
/**
* AOP缓存业务的实现
* 1 切入点表达式应该拦截自定义的注解 @CacheFind
* 2 通知方法: 环绕通知 @Around
* 注意事项:如果使用环绕通知,则必须在第一个参数的位置添加ProceedingJoinPoint
*/
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint, CacheFind cacheFind){
try {
Object result=null;
//1.动态获取注解中的值
String prekey = cacheFind.key();
//获取方法中的参数
String args = Arrays.toString(joinPoint.getArgs());
//构建key
String key = prekey+ "::"+args;
//检查redis中是否有数据
if (jedis.exists(key)){
//缓存中有数据
System.out.println("redis缓存查询");
String json = jedis.get(key);
//动态获取目标方法的返回值类型
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
Class<?> returnType = methodSignature.getReturnType();
//将缓存中取出来的数据转化为对象
result = ObjectMapperUtils.toObject(json,returnType );
}else {
//缓存中没有数据
System.out.println("AOP数据库查询");
//执行目标方法
result = joinPoint.proceed();
//将结果转化为json串
String json = ObjectMapperUtils.toJSON(result);
//判断缓存时候设置了超时时间
if (cacheFind.seconds()>0)
//设置超时时间
jedis.setex(key,cacheFind.seconds(),json);
else
//不设置超时时间
jedis.set(key,json);
}
return result;
} catch (Throwable throwable) {
throwable.printStackTrace();
throw new RuntimeException(throwable);//将检测异常转化为运行时异常
}
}
}
2.8 AOP缓存注解--商品列表->商品分类名称显示
2.8.1 业务描述
业务说明:用户在查询商品列表时.由于ajax业务调用动态的获取商品分类名称进行数据的展现.每次获取都需要查询数据库性能低.
优化策略: 利用Redis缓存实现.
2.8.2 代码优化
在业务层或者控制层添加自定义注解CacheFind,实现功能的扩展

3. redis常见面试题
3.1 缓存穿透
特点: 用户高并发环境下,访问数据库中根本不存在的数据.
影响:由于用户高并发访问,则数据库可能存在宕机的风险.

3.2 缓存击穿
说明: 由于用户高并发的访问. 访问的数据刚开始有缓存,但是由于特殊原因 导致缓存失效.(数据’‘单个’’)
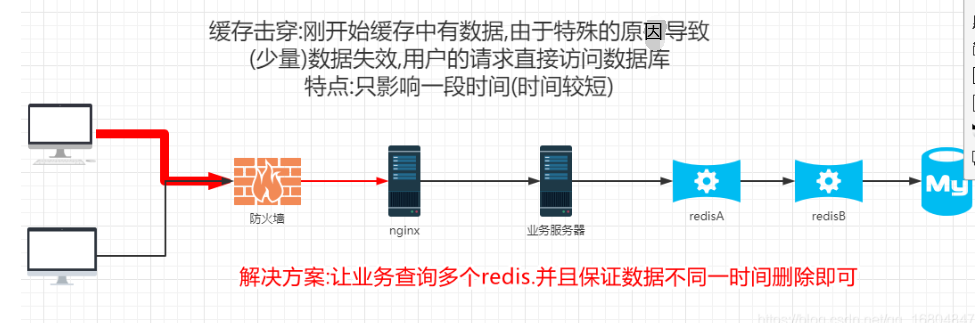
3.3缓存雪崩
说明: 由于高并发的环境下.大量的用户访问服务器. redis中有大量的数据在同一时间超时(删除).
解决方案:不要同一时间删除数据.

3.4 Redis持久化问题
3.4.1 问题说明
说明:Redis中的数据都保存在内存中.如果服务关闭或者宕机则内存资源直接丢失.导致缓存失效.
3.4.2 持久化原理说明
说明:Redis中有自己的持久化策略.Redis启动时根据配置文件中指定的持久化方式进行持久化操作. Redis中默认的持久化的方式为RDB模式.
3.4.3 RDB模式
特点说明:
1.RDB模式采用定期持久化的方式. 风险:可能丢失数据.
2.RDB模式记录的是当前Redis的内存记录快照. 只记录当前状态. 持久化效率最高的
3.RDB模式是默认的持久化方式.
持久化命令:
命令1: save 同步操作. 要求记录马上持久化. 可能对现有的操作造成阻塞
名来2: bgsave 异步操作. 开启单独的线程实现持久化任务.
持久化周期:
save 900 1 在900秒内,如果执行一次更新操作,则持久化一次.
save 300 10 在300秒内,如果执行10次更新操作,则持久化一次.
save 60 10000 在60秒内,如果执行10000次更新操作,则持久化一次.
save 1 1 ???不可以 容易阻塞 性能太低.不建议使用.
用户操作越频繁,则持久化周期越短.
3.4.4 AOF模式
特点:
1.AOF模式默认是关闭状态 如果需要则手动开启.
2.AOF能够记录程序的执行过程 可以实现数据的实时持久化. AOF文件占用的空间较大.回复数据的速度较慢.
3.AOF模式开启之后.RDB模式将不生效.
AOF配置:

持久化周期配置:
appendfsync always 实时持久化.
appendfsync everysec 每秒持久化一次 略低于rdb模式
appendfsync no 自己不主动持久化(被动:由操作系统解决)
3.4.5 redis中如何选择持久化方式
思路: 如果允许数据少量的丢失,则首选RDB.(快),如果不允许数据丢失则使用AOF模式.
3.4.6 情景题
小张在双11前夜误操作将Redis服务器执行了flushAll命令. 问项目经理应该如何解决??
A: 痛批一顿 ,让其提交离职申请.
B: 批评教育, 让其深刻反省,并且请主管 捏脚.
C:项目经理快速解决.并且通知全部门注意.
解决方案:
修改aof文件中的命令.删除flushAll之后重启redis即可.
3.5 Redis内存优化策略
3.5.1 修改Redis内存

修改内存大小:

3.5.2 场景说明
Redis运行的空间是内存.内存的资源比较紧缺.所以应该维护redis内存数据,将改让redis保留热点数据.
3.5.3 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度: 自上一次使用的时间T
最为理想的内存置换算法.
3.5.3 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
least frequently used (LFU) page-replacement algorithm
即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 引用次数
3.5.4 RANDOM算法
随机算法
3.5.3 内存策略优化
- volatile-lru 在设定了超时时间的数据, 采用lru算法进行删除.
2.allkeys-lru 所有数据采用lru算法
3.volatile-lfu 在设定了超时时间的数据, 采用LFU算法进行删除.
4.allkeys-lfu 所有数据采用LFU算法
5.volatile-random 设定超时时间数据采用随机算法
6.allkeys-random 所有数据采用随机算法
7.volatile-ttl 设定了超时时间的数据 根据ttl规则删除. 将剩余时间少的提前删除
8.noeviction 内存满了 不做任何操作.报错返回.
