一.排序目标
- 将暴光多的购买少的商品下沉
- 将高质量的商品尽量靠前
- 提高订单转化率等
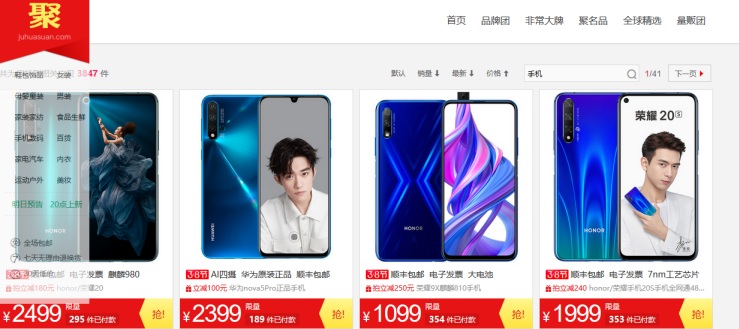
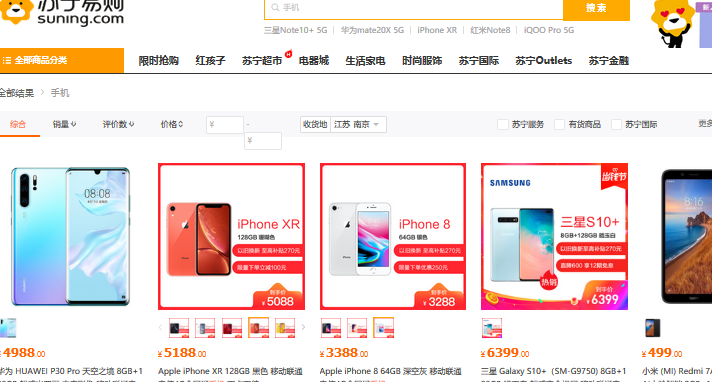
如下图电商中,在商品名栏中输入商品名,点击查询,系统将把最相关物品先前排。
二.排序的演变
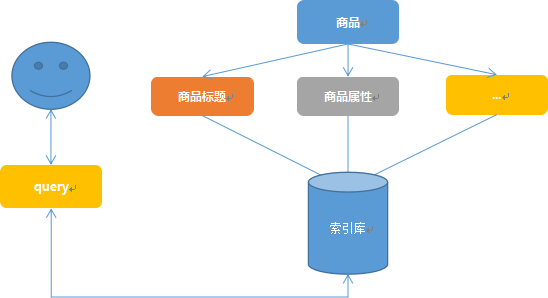
1.文本匹配阶段

2.人工加权阶段
打分公式:
w1*score1+w2*score2+w3*score3+... = total_score
3.机器学习阶段
机器学习可以持续的根据反馈的数据进行自我学习和迭代,不断地挖掘业务价值,对目标问题进行持续优化。
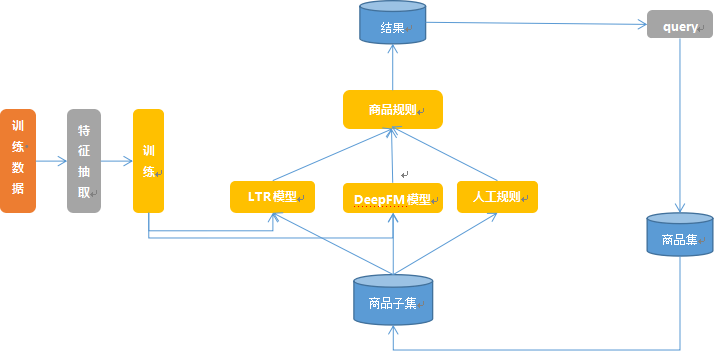
目前生产环境上机器排序学习的框架,包含两个部分:离线训练和在线应用。离线部分主要是根据近一个月的历史数据,训练和调试多个能够在线上使用的排序模型;模型在 推到线上之前会先在测试环境部署,测试人员会评估这个模型,确定没问题推到线上进行分流A/B测试。
(1) .排序整体结构
(2) .模型简要介绍
其实在排序前还有个召回阶段,召回是从成千上万个商品中粗选出几十到几百个商品作为排序的输入部分。排序模型有很多,比如常用的一些CTR模型、learning to rank模 型等。下面是其中两种排序模型。
A.LambdaMart
针对4种行为构建样本:
暴光:0
点击:1
收藏和加购:2
下单:3
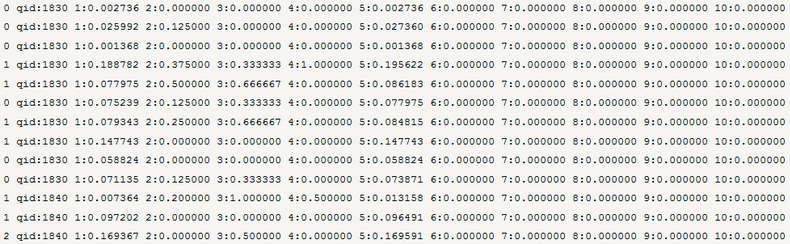
LambdaMART模型可以分成Lambda和MART两部分,底层模型训练用的是 MART(Multiple Additive Regression Tree),也叫GBDT(Gradient Boosting Decision Tree), 它的核心是每一棵树学习的是之前所有树结论和的残差, 这个残差+当前的预测值就能得到真实值。而Lambda是MART求解过程使用 的梯度,其物理含义是一个待排序的文档下 一次迭代应该排序的方向和强 度。
预测打分过程:
B.DeepFM
针对4种行为构建样本,构建成点击率预估模型:
暴光、点击:0
收藏、加购和下单:1
DeepFM主要包括两个部分,神经网络部分(一个前馈网络)和因子分解机部分,分别负责提取低阶特征和高阶特征。并且这两部分共享权重矩阵,即共享Embedding层。

预测得分:

C.评估指标
线下评估常用方法:ndcg、map、auc等
线上评估:订单转化率(有效订单数/访客数uv)、gmv(已付款订单和 未付款订单两者之和)等
D.使用的工具
原始数据 --> hive
数据处理和清洗 --> spark
样本的存储 --> hdfs
训练平台:spark ml;tensorflow;torch;keras;deeplearning4j 等