摘要:通过简单例子,了解功能。以此作为基点,在工作中不断深入
1.设置需要显示的行列宽度(显示的最大列数和最大行数,其余部分用.....表示)


设置显示多少行多少列 import pandas as pd import numpy as np pd.set_option('max_columns',5,'max_rows',5) df = pd.read_csv('20190708.csv') print(df) ''' pd.set_option('max_columns',3,'max_rows',3) Unnamed: 0 ... circ_mv 0 0 ... 142940.1406 ... ... ... ... 3608 3608 ... 466813.2600 [3609 rows x 19 columns] pd.set_option('max_columns',5,'max_rows',5) Unnamed: 0 ts_code ... total_mv circ_mv 0 0 603639.SH ... 443175.0623 142940.1406 1 1 600130.SH ... 294144.0000 294144.0000 ... ... ... ... ... ... 3607 3607 600017.SH ... 947301.3975 947301.3975 3608 3608 601038.SH ... 774878.1000 466813.2600 [3609 rows x 19 columns] '''
2.提取df索引,并对索引操作
import pandas as pd import numpy as np pd.set_option('max_columns',5,'max_rows',5) df = pd.read_csv('20190708.csv') print(df) column_ = df.columns index_ = df.index data_ = df.values print(column_) print(index_) print(data_) print(type(column_)) ##<class 'pandas.core.indexes.base.Index'> print(type(column_.values)) ##class 'numpy.ndarray' print(type(column_.tolist()))##<class 'list'>
说明:
1.列索引提取出来的数据类型都是Index对象<class 'pandas.core.indexes.base.Index'>

通过column_.values获得## <class 'numpy.ndarray'>数组类
通过column_.tolist()获得##<class 'list'> 列表类
2.行索引与列索引类似

3.访问索引内的值
print(column_.values[1]) ##ts_code同数组取值一样
print(index_.tolist()[1]) ## 1 同list取值一样
4.重命名行列索引
df.index = index_list ##新的行名列表直接赋值
df.columns = column_list
说明:局部行改名,可以先提取行索引,转化成列表,更改对应名称,之后执行df.index = index_list操作。
也可以通过df.rename(index=idx_rename,columns=col_rename),其中idx_rename、col_rename是字典{“旧名”:新名}
3.df取值的方式之标签索引和位置索引
3.1基于标签(索引).loc
单个标签0(解释为标签)或‘a’,列表或数组标签['a','b','c'],带标签的切片‘a’:'f',布尔数组,一个callable带一个参数的函数

3.1基于标签(索引).loc的行列取值布尔数组及callable取值后续更新
3.2基于位置 (整数).iloc (从0到len-1,位置索引不能超过这个索引范围)
基于位置索引的取值方式,大体上与基于标签索引的取值方式一致。
import pandas as pd import numpy as np df = pd.read_csv('20190708.csv') ##取0行1列位置的值 print(df.iloc[0,1]) ##取指位置定行,返回一个series序列 print(df.iloc[0,:]) ##取指定位置列,返回一个series序列 print(df.iloc[:,1]) ##行位置切片 print(df.iloc[0:5,:]) ##列位置切片 print(df.iloc[:,0:5]) ##指定行位置(不连续)多个 print(df.iloc[[0,3,6],:]) ##指定列位置(不连续)多个 print(df.iloc[:,[0,2,4]]) ##指定行列位置多个 print(df.iloc[[0,3,6],[0,2,4]])
4.属性访问

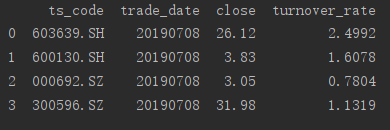
我们通过一个例子,来说明通过属性访问的实现过程
##获得一个序列 series_1 = dfa.ts_code print(series_1)
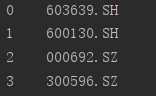
通过属性运算'.'的方式获取ts_code这一列的数据,返回一个series序列,这个是数字索引,怎么通过属性获取其中的值(目前不清楚),这里用索引取series_1中的值
print(series_1[1]) ##返回 600130.SH
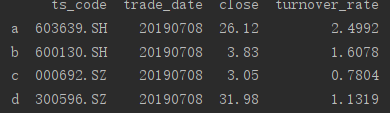
print(series_1) ##输出如下

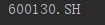
print(series_1.b)
import pandas as pd import numpy as np df = pd.read_csv('20190708.csv') dfa = df.iloc[[0,1,2,3],[1,2,3,4]] dfa.index = ['a','b','c','d'] print(dfa) ##获得一个序列 series_1 = dfa.ts_code print(series_1) print(series_1.b)
5.通过可调用选择(按条件选取)
.loc .iloc 及 []可以接受一个callable索引器。
import pandas as pd import numpy as np df = pd.read_csv('20190708.csv') dfa = df.iloc[[0,1,2,3],[1,2,3,4]] dfa.index = ['a','b','c','d'] print(dfa) ##显示满足条件的行(.iloc同理) print(dfa.loc[lambda df:dfa.close>4,:]) ##显示满足条件的列(.iloc同理) print(dfa.loc[:,lambda df:['close','ts_code']]) ##[]取 一列数据 print(dfa[lambda dfa:dfa.columns[0]])
ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 b 600130.SH 20190708 3.83 1.6078 c 000692.SZ 20190708 3.05 0.7804 d 300596.SZ 20190708 31.98 1.1319 ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 d 300596.SZ 20190708 31.98 1.1319 close ts_code a 26.12 603639.SH b 3.83 600130.SH c 3.05 000692.SZ d 31.98 300596.SZ a 603639.SH b 600130.SH c 000692.SZ d 300596.SZ Name: ts_code, dtype: object Process finished with exit code 0
6.布尔操作过滤数据
|(or) &(and) ~(not) ,使用时需用括号进行分组
import pandas as pd import numpy as np df = pd.read_csv('20190708.csv') dfa = df.iloc[[0,1,2,3],[1,2,3,4]] dfa.index = ['a','b','c','d'] ##对序列操作 series_2 = dfa.close print(series_2) ##显示序列中大于4的所有数据 print(series_2[series_2>4]) ##显示序列中大于4或者小于3.5的 print(series_2[(series_2>4)|(series_2<3.5)]) ##显示大于4且 小于30的 print(series_2[(series_2>4)&(series_2<30)]) ##显示不大于4的 print(series_2[~(series_2>4)]) ##对df操作 print(dfa[dfa['close']>4]) print(dfa[(dfa['close']>4)&(dfa['turnover_rate']>2)])
a 26.12 b 3.83 c 3.05 d 31.98 Name: close, dtype: float64 a 26.12 d 31.98 Name: close, dtype: float64 a 26.12 c 3.05 d 31.98 Name: close, dtype: float64 a 26.12 Name: close, dtype: float64 b 3.83 c 3.05 Name: close, dtype: float64 ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 d 300596.SZ 20190708 31.98 1.1319 ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 Process finished with exit code 0
import pandas as pd import numpy as np df = pd.read_csv('20190708.csv') dfa = df.iloc[[0,1,2,3],[1,2,3,4]] dfa.index = ['a','b','c','d'] print(dfa) ##使用map函数,判断指定列是否以‘6’开头 criterion = dfa['ts_code'].map(lambda x:x.startswith('6')) print(criterion) ##先产生布尔结果 print(dfa[criterion]) ##在筛选显示 ##使用三元表达式筛选 dfb = dfa[[x.startswith('6') for x in dfa['ts_code']]] print(dfb ) ##多条件筛选 dfc = dfa[criterion & (dfa['trade_date']==20190708)] print(dfc)
ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 b 600130.SH 20190708 3.83 1.6078 c 000692.SZ 20190708 3.05 0.7804 d 300596.SZ 20190708 31.98 1.1319 a True b True c False d False Name: ts_code, dtype: bool ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 b 600130.SH 20190708 3.83 1.6078 ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 b 600130.SH 20190708 3.83 1.6078 ts_code trade_date close turnover_rate a 603639.SH 20190708 26.12 2.4992 b 600130.SH 20190708 3.83 1.6078