朴素贝叶斯算法是机械学习中比较简单中的算法,采用贝叶斯算法可以实现简单的分类技术。
文章中采用的数据训练库为 THUOCL:清华大学开放中文词库
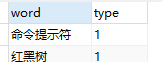
数据格式为 : word , type (单词、类型)
如图所示:
算法执行步骤
1.数据训练集
2.格式化数据满足算法输入要求
3.分析数据训练算法
4.测试算法效果
5.算法应用
代码简单实现:
训练代码实 1 public ArrayList<ArrayList<String>> fetch_traindata(){ 2 ArrayList<ArrayList<String>> dataSet = new ArrayList<ArrayList<String>>(); 3 4 Connection conn;
5 String driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"; 6 String url = "jdbc:sqlserver://localhost:1433; DatabaseName=Bayes"; //指向要访问的数据库!注意后面跟的是数据库名称 7 String user = "sa"; //用户名 8 String password = "*****"; //密码 9 try{ 10 Class.forName(driver); //用class加载动态链接库——驱动程序 11 conn = DriverManager.getConnection(url,user,password); //利用信息链接数据库 12 if(!conn.isClosed()) 13 System.out.println("Succeeded connecting to the Database!"); 14 15 Statement statement = conn.createStatement(); //用statement 来执行sql语句 16 String sql = "select * from THUOCL_it"; 17 ResultSet rs = statement.executeQuery(sql); //用于返回结果 18 19 String str = null; 20 while(rs.next()){ //一直读到最后一条表 21 ArrayList<String> s= new ArrayList<String>(); 22 str = rs.getString("word"); //分别读取相应栏位的信息加入到可变长数组中 23 s.add(str); 24 str = rs.getString("type");
s.add(str); 25 26 dataSet.add(s); //加入dataSet 27 //System.out.println(s); 输出中间结果调试 28 } 29 rs.close(); 30 conn.close(); 31 }catch(ClassNotFoundException e){ //catch不同的错误信息,并报错 32 System.out.println("连接失败!"); 33 e.printStackTrace(); 34 }catch(SQLException e){ 35 e.printStackTrace(); 36 }catch (Exception e) { 37 e.printStackTrace(); 38 }finally{ 39 System.out.println("数据库训练数据读取成功!"); 40 } 41 return dataSet; 42 } 43 44 45 public ArrayList<String> read_testdata(String str) throws IOException //将用户输入的一整行字符串分割解析成可变长数组 46 { 47 ArrayList<String> testdata=new ArrayList<String>(); //待返回 48 StringTokenizer tokenizer = new StringTokenizer(str); 49 while (tokenizer.hasMoreTokens()) { 50 testdata.add(tokenizer.nextToken()); 51 } 52 return testdata; 53 }
贝叶斯算法实现
public Map<String,ArrayList<ArrayList<String>>> classify(ArrayList<ArrayList<String>> dataSet){ Map<String,ArrayList<ArrayList<String>>> map = new HashMap<String, ArrayList<ArrayList<String>>>(); //待返回的Map int num=dataSet.size(); for(int i=0;i<num;i++) //遍历所有数据项 { ArrayList<String> Y = dataSet.get(i); //将第i个训练样本的信息取出 String Class = Y.get(Y.size()-1).toString(); //约定将类别信息放在最后一个字符串 if(map.containsKey(Class)){ //判断map中是否已经有这个类了 map.get(Class).add(Y); }else{ //若没有这个类就新建一个可变长数组记录并加入map ArrayList<ArrayList<String>> nlist = new ArrayList<ArrayList<String>>(); nlist.add(Y); map.put(Class,nlist); } } return map; } //计算分类后每个类对应的样本中某个特征出现的概率 //输入:某一类别对应的数据(classdata) 目标值(value) 相应的列值(index) //输出:该类数据中相应列上的值等于目标值得频率 public double CalPro_yj_c(ArrayList<ArrayList<String>> classdata, String value, int index){ int sum = 0; //sum用于记录相同特征出现的频数 int num = classdata.size(); for(int i=0;i<num;i++) { ArrayList<String> Y = classdata.get(i); if(Y.get(index).equals(value)) sum++; //相同则计数 } return (double)sum/num; //返回频率,以频率带概率 } //贝叶斯分类器主函数 //输入:训练集(可变长数组);待分类集 //输出:概率最大的类别 public String bys_Main(ArrayList<ArrayList<String>> dataSet, ArrayList<String> testSet){ Map<String, ArrayList<ArrayList<String>>> doc = this.classify(dataSet); //用本class中的分类函数构造映射 Object classes[] = doc.keySet().toArray(); //把map中所有的key取出来(即所有类别) ,借鉴学习了object的使用(待深入了解) double Max_Value=0.0; //最大的概率 int Max_Class=-1; //用于记录最大类的编号 for(int i=0;i<doc.size();i++) //对每一个类分别计算,本程序只有两个类 { String c = classes[i].toString(); //将类提取出 ArrayList<ArrayList<String>> y = doc.get(c); //提取该类对应的数据列表 double prob = (double)y.size()/dataSet.size(); //计算比例 System.out.println(c+" : "+prob); //输出该类的样本占总样本个数的比例! for(int j=0;j<testSet.size();j++) //对每个属性计算先验概率 { double P_yj_c = CalPro_yj_c(y,testSet.get(j),j); //输出中间结果以便测试System.out.println("now in bys_Main!!"+P_yj_c); prob = prob*P_yj_c; } System.out.printf("P(%s | testcase) * P(testcase) = %f ",c,prob); //输出分子的概率大小 if(prob>Max_Value) //更新分子最大概率 { Max_Value=prob; Max_Class=i; } } return classes[Max_Class].toString(); }
主函数
FetchData Fdata = new FetchData(); Bayes bys = new Bayes(); ArrayList<ArrayList<String>> dataSet = null; //训练数据列表 ArrayList<String> testSet = null; //测试数据 try{ System.out.println("从数据库读入训练数据:"); dataSet = Fdata.fetch_traindata(); //读取训练数据集合 System.out.println("请输入测试数据:"); Scanner cin = new Scanner(new BufferedInputStream(System.in)); while(cin.hasNext()) //多条测试数据读取 { String str = cin.nextLine(); //先读入一行 testSet = Fdata.read_testdata(str);//将这一行进行字符串分隔解析后返回可变长数组类型 // System.out.println(testSet+" "); //System.out.println(testSet); //输出中间结果 String ans = bys.bys_Main(dataSet, testSet); //调用贝叶斯分类器 if(ans.equals("1")) System.out.println("IT"); //输出结果 else if(ans.equals("2")) System.out.println("饮食"); else System.out.println("其他"); } cin.close(); }catch (IOException e) { //处理异常 e.printStackTrace(); }
测试结果:
