第二次写关于MSDNet方面的学习笔记,终于是弄懂了大致的全部代码,也熟悉了其处理过程,先将第二阶段的学习成果做一下介绍。
想看上一篇学习笔记(主要是翻译大致内容)的可以看这个链接:https://www.cnblogs.com/liuyangcode/p/13700393.html
关于MSDNet的源代码链接在上一篇学习笔记里已经贴出,本篇笔记主要是关于代码中dynamic方式如何实现的一个详细介绍,也就是所谓的budgeted batch classification
具体完整的代码和注释可以看这个链接:https://github.com/Liuyang829/testMSDNet/blob/main/adaptive_inference.py
文中所描述两种评估方法:budgeted batch,anytime
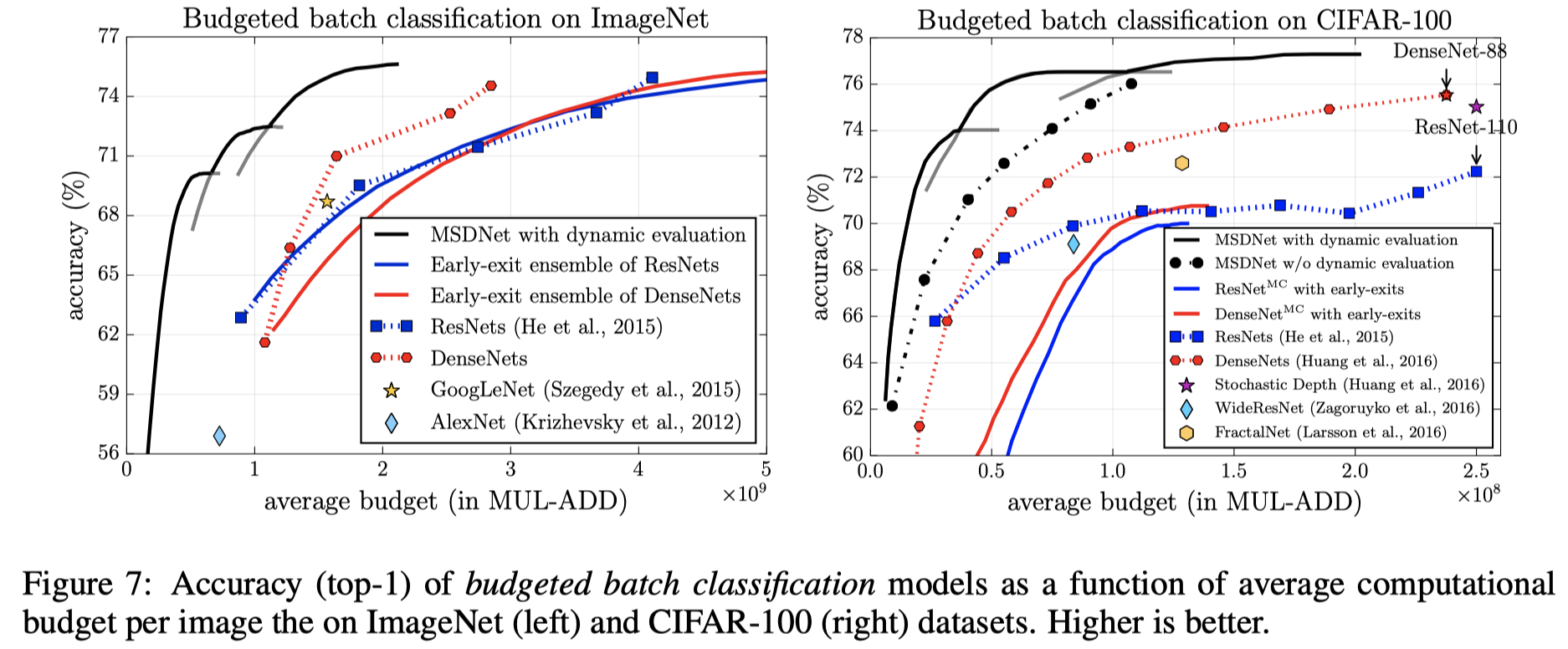
文中所描述的budgeted batch是对于一个batch中的众多样本来说,共用一个固定的资源限制,可以自适应的在这一个batch中让简单样本使用少一些的资源,让复杂样本使用多一些的资源。例如对于大型公司所需要处理的大量数据来说,如果能再简单样本上节省一点点的时间 对于之后的总体计算花费来说都是划算的。在这样的一个batch中,如果计算资源总限制为B,这个batch中包含M个样本数据,简单样本所分的资源应该小于B/M,复杂样本应该大于B/M。但所描述的相对来说比较抽象,代码上的实现远比所描述的复杂,而且从下面的图像上看,也可以看出这样一条曲线需要多组测试数据与测试结果。
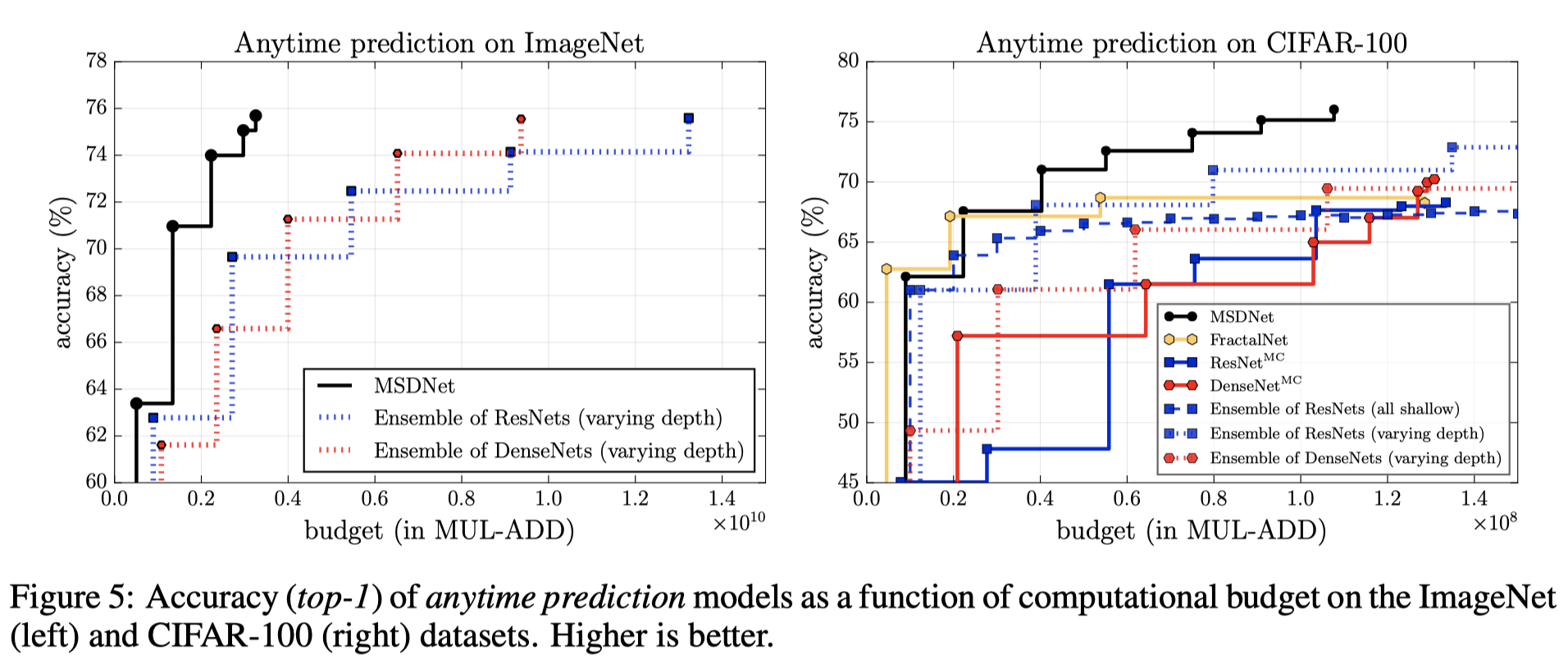
相比来说 ,文中所说的anytime prediction 指的是可以使网络在任何给定的时间内给出预测结果。在代码上的实现相对来说较为简单,原文中的测试结果图如下所示,横坐标表示flops,纵坐标表示acc,至于flops是如何计算而来的,主要是看网络结构。MSDNet的一个重要特点就是有多个分类器,样本在测试时如果从浅层分类器输出自然其flops会比较小,所以在模型结构确定下来后对于模型flops的计算主要取决于有多少个分类器,在逐层计算flops与prams的过程中,如果遇到Liner层,就会输出一次结果。也就意味着整个网络模型根据classifer位置的不同来确定flops的大小。对于anytime的测试过程,就是所有的数据在每个分类器都输出一次结果,所以在下图中有几个点就代表有几个分类器,也就是几个blocks,代表在该分类器所有样本全部退出所得到的正确率。
代码实现 budgeted batch
该模块代码上的实现一直困惑着我,终究怎么样才能达到在不同分类器输出的动态推理,重点就在adapative_inference.py
总体来说动态退出实现思路在于,对于每一个分类器都找到一个退出的阈值,在执行测试的过程中,如果样本在某一分类器的置信度超过了该分类器的阈值,则代表该样本找到了属于他的出口,所以核心在于每个分类器都要找到一个合适的阈值,这样就可以对所有输出的样本进行判断
首先在动态处理的主函数中对于所有的验证集与测试集都放入calc_logit()函数来计算一次所有的输出置信度,验证集进行计算的目的用于计算阈值,测试集就是为了根据置信度和阈值判断最后在哪输出和最终结果。设立了一个40次的for循环的意义就在于生成了40组分类器的权重数据,代表了每个分类器要输出百分之多少的数据样本量,然后再根据这个限制去测试结果。
1 def dynamic_evaluate(model, test_loader, val_loader, args): 2 tester = Tester(model, args) 3 if os.path.exists(os.path.join(args.save, 'logits_single.pth')): 4 val_pred, val_target, test_pred, test_target = 5 torch.load(os.path.join(args.save, 'logits_single.pth')) 6 else: 7 # 这里对于验证集与测试集分别计算每个分类器对于每一个样本的一个预测结果置信度 8 val_pred, val_target = tester.calc_logit(val_loader) 9 test_pred, test_target = tester.calc_logit(test_loader) 10 torch.save((val_pred, val_target, test_pred, test_target), 11 os.path.join(args.save, 'logits_single.pth')) 12 13 flops = torch.load(os.path.join(args.save, 'flops.pth')) 14 15 with open(os.path.join(args.save, 'dynamic.txt'), 'w') as fout: 16 for p in range(1, 40): 17 print("*********************") 18 # 在这个for循环中生成一个0.05-1.95,以生成40组不同分类器的权重 19 _p = torch.FloatTensor(1).fill_(p * 1.0 / 20) 20 # 通过一个对数生成一个nBlocks维的tensor,就是不同分类器所需要处理的数据比例 21 probs = torch.exp(torch.log(_p) * torch.range(1, args.nBlocks)) 22 probs /= probs.sum() 23 # 利用验证集去找阈值 24 acc_val, _, T = tester.dynamic_eval_find_threshold( 25 val_pred, val_target, probs, flops) 26 # 利用阈值给测试集安排出口与分类结果 27 acc_test, exp_flops = tester.dynamic_eval_with_threshold( 28 test_pred, test_target, flops, T) 29 print('valid acc: {:.3f}, test acc: {:.3f}, test flops: {:.2f}M'.format(acc_val, acc_test, exp_flops / 1e6)) 30 fout.write('{} {} '.format(acc_test, exp_flops.item()))
在calc_logit函数中,主要目的就是对两个数据集合进行置信度的计算,我们都知道对于一般的神经网络来说,分类器最后的输出结果都是一个classes维的向量,代表了对于该样本各个类别的置信度结果,向量中的最大的那个值所对应的下标也就是所对应的分类结果。
下面的代码中可以看到,假设m个blocks,n个数据样本,c个类别,首先生成空的m维的列表logits用来装计算结果。将数据放进模型中输出output,这个output[0]就代表着第1个分类器输出的预测结果,以此类推,这里将预测结果再用softmax使数据分布更为明显,放进logits中。对于这个输出结果,可以判断这是一个三阶的矩阵,它的size大小为(m,n,c)。
至于为什么是这个size,m代表了m个分类器的输出结果,所以首先是m,对于logits[0],size为(n,c),n个c维向量所组成的矩阵,代表着每个样本数据进入模型的预测结果,所以共n行c列
1 def calc_logit(self, dataloader): 2 self.model.eval() 3 n_stage = self.args.nBlocks 4 logits = [[] for _ in range(n_stage)] 5 targets = [] 6 for i, (input, target) in enumerate(dataloader): 7 targets.append(target) 8 with torch.no_grad(): 9 input_var = torch.autograd.Variable(input) 10 # 模型生成每个分类器的预测结果 11 output = self.model(input_var) 12 if not isinstance(output, list): 13 output = [output] 14 # softmax相当于将值映射到0-1直接并且和为1 15 for b in range(n_stage): 16 _t = self.softmax(output[b]) 17 logits[b].append(_t) 18 19 if i % self.args.print_freq == 0: 20 print('Generate Logit: [{0}/{1}]'.format(i, len(dataloader))) 21 for b in range(n_stage): 22 logits[b] = torch.cat(logits[b], dim=0) 23 # logits相当于每个block输出的结果,首先是nBlocks维, 24 # 因为有多个分类器输出,logits[0]~logits[nBlocks-1] 25 # 对于每个输出结果,肯定是输入的数量num*classes类别置信度向量 然后根据size变成张量 26 size = (n_stage, logits[0].size(0), logits[0].size(1)) 27 ts_logits = torch.Tensor().resize_(size).zero_() 28 for b in range(n_stage): 29 ts_logits[b].copy_(logits[b]) 30 # 将targets也变成张量 31 targets = torch.cat(targets, dim=0) 32 ts_targets = torch.Tensor().resize_(size[1]).copy_(targets) 33 return ts_logits, ts_targets
计算出了置信度也组成了合适的数据结构,下一步就是最重要的核心操作,在不同的分类器权重组合中去找这40种threshold组合。这段代码中用到很多pytorch的基本函数如max(dim,) sort(dim,) ge() type_as()等,具体用法在代码注释中都有写。现在我来阐述一下这个的思路。
根据这一部分数据样本的预测结果,首先将每一个样本分类的置信度结果的最大值和下标都取出来,也就相当于是正常的分类结果。对于输出的结果为一个m行n列的矩阵,每一行代表每一个分类器,每一列代表每个数据样本,矩阵的数值表示在该分类器下预测结果最大的那个置信度,同时有一个相同size的矩阵并记录其下标。对于生成的这个矩阵,在行的维度上进行一次排序,就意味着每一行的置信度向量都是从高到低排列的,每个分类器对于自己所分出来的最有自信的结果放在了最前面,同时也记录了排序后对应的原下标。在之前已经设定好了每一个分类器的一个权重,根据权重可以分配每个分类器输出的样本数量,所以就从高到低对于每一个分类器输出的结果进行分类,假设第一个分类器可以分出200个数据,那从高到低排在第200的那个置信度的值就是这个分类器的阈值,这里新开了一个n维的list用来记录每一个样本有没有从网络中输出,样本从前一个分类器出去之后自然后续不用再进行考虑,用作标志位,最后一个分类器的阈值设定为无穷小因为所有剩余的样本都要在这个分类器出来。这样大致就计算出了每个分类器的阈值。
1 def dynamic_eval_find_threshold(self, logits, targets, p, flops): 2 """ 3 logits: m * n * c 4 m: Stages-nblocks 5 n: Samples 6 c: Classes 7 """ 8 n_stage, n_sample, c = logits.size() 9 print(logits.size()) 10 # dim=2返回的max_preds是每一行的最大值,这个最大值也就是预测出来最大置信度的那个置信度 11 # argmax_greds就是这个最大预测值的下标,代表是第几个 12 # 所以max_preds的维度是nblocks行,samples列,代表每个分类器出来的每个样本的最大置信度预测结果 13 # 例如7行10列 就表示7个分类器有10个样本进去输出的预测结果置信度,arg代表的就是原来的下标代表第几个 14 max_preds, argmax_preds = logits.max(dim=2, keepdim=False) 15 16 # 这里对max_preds在行上进行排序,_为排序后的结果,sort_id就是对应原来矩阵中的下标 17 _, sorted_idx = max_preds.sort(dim=1, descending=True) 18 # 样本个数个 19 filtered = torch.zeros(n_sample) 20 # 用来装阈值的 21 T = torch.Tensor(n_stage).fill_(1e8) 22 # p是每个分类器的权重 23 # 对一个中间分类器而言,已经设定好了从这个分类其中分出去的数量, 24 # 那就把这个分类器出来的所有结果排序后前n个当作这个分类器可以退出的, 25 # 那么第n个分出去的那个预测结果的置信度就是阈值 26 for k in range(n_stage - 1): 27 acc, count = 0.0, 0 28 # 计划每个分类器按照权重分出去的个数 29 out_n = math.floor(n_sample * p[k]) 30 for i in range(n_sample): 31 # ori_idx表示 32 ori_idx = sorted_idx[k][i] 33 # filter记录着每个样本是否已经退出 只有还没有退出的才能作为计算 起标记作用 34 if filtered[ori_idx] == 0: 35 count += 1 36 # 到了预计的退出数量就记下来那个阈值 37 if count == out_n: 38 T[k] = max_preds[k][ori_idx] 39 break 40 # ge判断张量内每一个数值大小的函数 type_as为了该表数据类型后才能用ge进行比较 add_为加的操作 41 # ge的比较结果在于在本层分类器中有多少个样本已经退出,得出来的理想结果应该是[1,1,1,1,1...0,0,0,...] 42 # filter本来为一个sample维的0向量,加上比较的结果后就说明标记好了已经退出去的样本。 43 44 filtered.add_(max_preds[k].ge(T[k]).type_as(filtered)) 45 46 T[n_stage -1] = -1e8 # accept all of the samples at the last stage 47 48 # 计算正确率 49 acc_rec, exp = torch.zeros(n_stage), torch.zeros(n_stage) 50 acc, expected_flops = 0, 0 51 for i in range(n_sample): 52 gold_label = targets[i] 53 for k in range(n_stage): 54 if max_preds[k][i].item() >= T[k]: # force the sample to exit at k 55 if int(gold_label.item()) == int(argmax_preds[k][i].item()): 56 acc += 1 57 acc_rec[k] += 1 58 exp[k] += 1 59 break 60 acc_all = 0 61 # 根据比例计算flops 62 for k in range(n_stage): 63 _t = 1.0 * exp[k] / n_sample 64 expected_flops += _t * flops[k] 65 acc_all += acc_rec[k] 66 67 return acc * 100.0 / n_sample, expected_flops, T
得到了阈值就很方便后续的计算了,同样对于置信度最大值的矩阵进行排序,从大到小输入网络中依次进行判断,如果置信度大于设定的阈值就输出,同时计算出每一个分类器所输出的样本个数,根据不同分类器所对应的flops的不同计算出实际所用的flops。同时,根据每一个分类器所分对的样本数量计算出了一个总的正确分类个数,计算出了测试正确率。
1 def dynamic_eval_with_threshold(self, logits, targets, flops, T): 2 # 和上面类似 接下来是一个比较的过程 3 n_stage, n_sample, _ = logits.size() 4 max_preds, argmax_preds = logits.max(dim=2, keepdim=False) # take the max logits as confidence 5 # acc为总的正确个数 acc_rec为每一个分类器的正确个数 6 acc_rec, exp = torch.zeros(n_stage), torch.zeros(n_stage) 7 acc, expected_flops = 0, 0 8 for i in range(n_sample): 9 gold_label = targets[i] 10 for k in range(n_stage): 11 if max_preds[k][i].item() >= T[k]: # force to exit at k 12 _g = int(gold_label.item()) 13 _pred = int(argmax_preds[k][i].item()) 14 if _g == _pred: 15 acc += 1 16 acc_rec[k] += 1 17 exp[k] += 1 18 break 19 # 根据每个分类器退出数量计算出flops,flops计算的时候本身就是一个分类器一个flops 20 acc_all, sample_all = 0, 0 21 for k in range(n_stage): 22 _t = exp[k] * 1.0 / n_sample 23 sample_all += exp[k] 24 expected_flops += _t * flops[k] 25 acc_all += acc_rec[k] 26 return acc * 100.0 / n_sample, expected_flops
这里基本上完整叙述了动态推理的过程,到此才真正理解了什么是所谓的动态推理。但其实我在思考问题在于真正实际使用时,是在测试的时候实现动态推理,这里是在训练集中提前分了一部分数据出来作为验证集来计算这个threshold,那如果真正使用中是不是应该把这一部分放在训练部分比较更为合适些,这样才能实现真正的动态推理测试。
以上均为个人理解,如果还有任何对于本文的疑问,欢迎留言讨论