以下内容全是在项目中的体验,个人理解心得
起源
2017年7月开始接触.NetCore,当时还是因为Idr4的原因,之前的项目都是用的Idr3做,后面接触到Idr4后,决定以后所有项目都使用.NetCore来搭建项目架构,随后我开始研究Idr4的相关使用,后面又接触到了Ocelot、Cap、Consul、Skywalking、AspectCore、MediatR等优秀库,从此我决定搭建微服务项目,从此就走上了一条不归路,接下来我阐述下我在在架构思想上的心得。
项目介绍
项目是一个学生体检体检项目,整体分为了认证中心、用户服务、体检服务三个部分
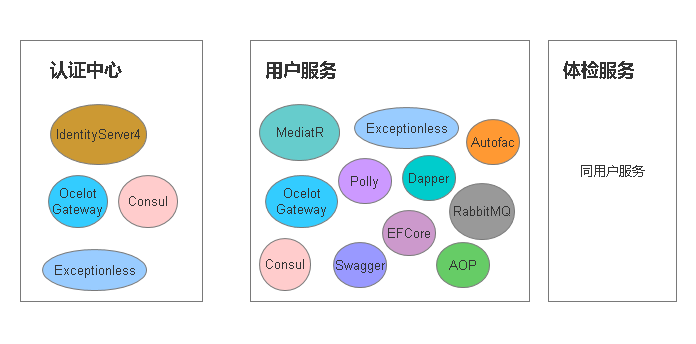
我建立了三个服务,这里各自的项目人员开发自己的项目功能模块,分布开发,多个项目组同时协作,用户服务,体检服务分别建立2个数据库,当然这里业务会存在服务调用服务的情况,前面的文章我也有说过,如果只是查询,其实在UI端访问2个不同服务接口就行了,但是如果存在内部业务需要调用另外一个服务的情况,这里保证数据库最终数据一致就行了,采用了消息队列RabbitMQ来处理,接口调用接口会出现的网络原因我也结合了Polly重试来处理,并记录操作日志,操作日志采用面向切面是来实现(AOP),结合Exceptionless保存日志信息,记录参数详细信息
接下来就看是搭建项目结构基础了,大体上我想的是下面这个结构,把所有的配置单独出来,Domain层添加领域实体,这里参见了eshopscontainer
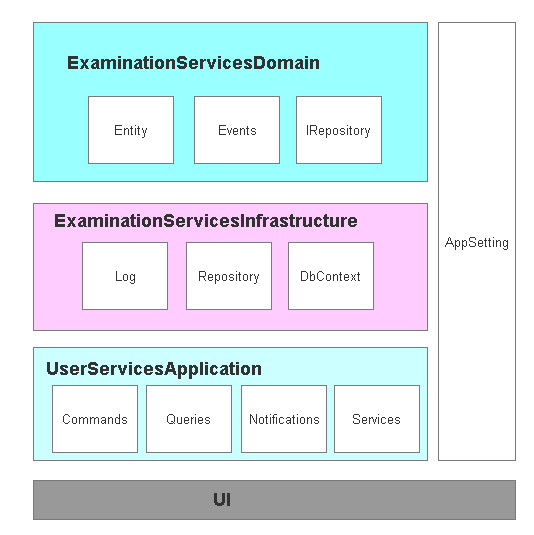
领域层
大体结构已经建立好了后,根据业务添加好领域模型,确定了领取模型中领域职责事件,这是我对DDD的个人理解,这里涉及到 聚合根(AggregateRoot)、值对象(ValueObject)等一些东西,为什么要要说聚合根以及值对象,这可能涉及到一个认知改变,就是把EFCore模型中建立的关系型思想转化为领域对象的认知思维,在以前的项目中记得经常有一个Model层一样的东东,经常被用来承载数据,穿梭在各个结构层之间,这里要说的Model在思想上可以认为是一个领域或者子领域,我个人是这么理解 领域对象模型:定义或描述一个领域对象自身属性(模型)、附属关系(边界)及领域行为(事件)的对象。
聚合根其实个人觉得跟EF中的上下文对象DbContext类似,打个比方:在DbContext中有很多 DbSet<T> 的对象,其实也可认为这个就是 DbContext下的边界,而DbContext本生看作一个聚合根,所有的访问都是DbContext下的 DbSet<T>实现对不同实体操作,定义这个边界就是为了不让从外部访问它,需要通过在聚合根中的定义的边界访问,在实际的使用的过程中根据业务定义,这里我在代码中为了不让这个关系呈现在我的数据中,所以基本上我的每个领域模型我都是聚合根,这样是我不想 因为聚合根中的边界的依赖关系产生生成数据库关联关系成强主外键关系,所以在这个项目中我 聚合根及值对象基本就被忽略了,从而我更加关注领域模型本生及领域模型中行为。
基础层
基础层我封装了Exceptionless日志处理,使用EFCore生产数据库的Mapper配置及业务实现处理,以及上下问对象处理,这里需要说的领域中的界限上下文,这里我一个领域所以我只有一个上下文,这个根据业务划分存在多个领域上下文对象,没有划分核心领域,子领域,一般一个领域(或子领域)对应有一个界限上下文,在服务上我已经分开了用户服务于体检服务,实际每个服务都是一个子领域,在结构上已经区分开了。在基础层做了对IRepositry的仓储以及MediatR的扩展从而实现消费领域事件。
应用层
应用层相对比较容易了,采用MediatR实现了命令式处理,在这中间我使用AOP封装了操作日志记录操作信息,查询使用了Dapper实现了读写分离查询,在MySql上做了一个主从,这里特别害怕数据同步延迟,所以这里的查询我只用了那些只单单是查询的方法,如果跟业务相关的查询还是使用了EFCore,比如要根据查询某一条结果然后某一条数据,使用MediatR 中的 INotification 去消费领域事件,另外我还在引用层添加了AggregateServices聚合服务相关处理,关于文件存储这块使用了AliyunOSS,目前关于缓存使用Redis做简单的权限信息缓存。
WebAPI
采用Autofac处理了接管了.NetCore的 DI,封装了相关注入方式简化了代码,另外对验证做了扩展操作,采用Swagger构建API接口说明文档,处理了WebAPI的版本信息以及采用RabbitMQ发布订阅消息,处理来之服务之间相互调用的问题
GateWay网关
采用了Ocelot来做网关相关处理,具体在前面博客中都有介绍了
分布式目标
做了上面的架构后以实现下面的部署结构
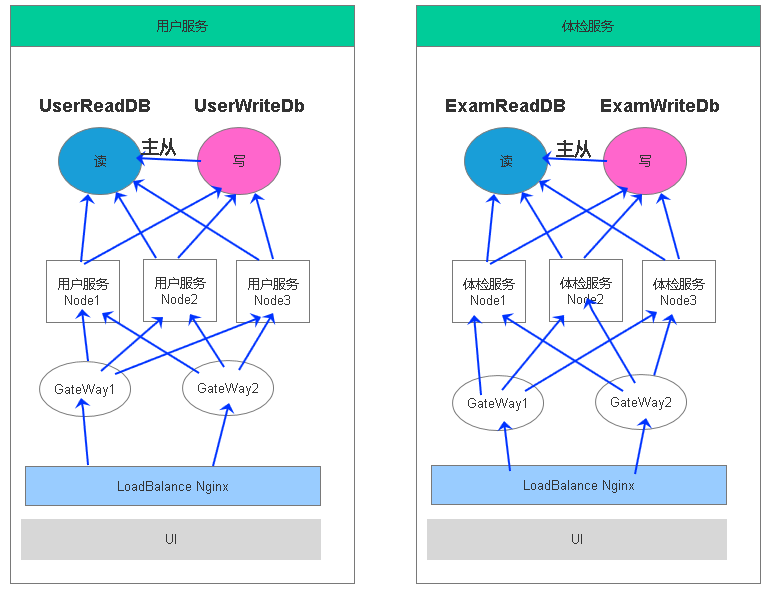
但是我发现现在最难做的一些事情反而出现在了 数据库这块,数据的一致性,容灾、目前只是一个主从而已,如果数据量一大,并发高,前面服务的压力可以通过多个Node来处理算是通过硬件扩展,如果要把服务分的足够小,在实际业务中复杂度会上升,我想得是一主多从,或者多主多从的情况。
主从数据库集群
通过程序业务处理做读写分离CQRS,在一主一从任然不能满足我们实际业务需要的时候,我们又该怎么来做呢,这引起了我的思考,一般情况下读的次数比写的多,开始考虑一主多从,或者多主多从的情况,这块就设计了数据库的高可用负载均衡集群,下面就是数据库的变化 ,从这样的结构上来缓解压力,实际上在业务上我们在数据库上已经有了拆分,现在无论是垂直或者水平都已经处理,在结构上看起来好像还不错,但是实际技术细节处理还是非常多的
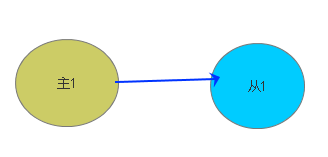
单独一个数据库
主从数据库
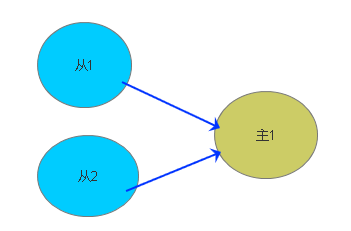
一主多从
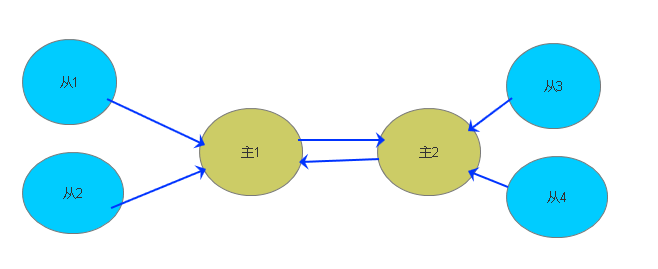
多主多从
有了这些结构,其实还不够,在一些大型系统中都存在一些报表统计,这些统计来之不同的服务不同的数据库,这些数据需要聚合查询,前期设计可以通过分析需求业务制定好统计这一块的数据冗余,比如最基本的用户信息等,此外我们还可以通过数据库同步服务将来自不同业务服务的数据同步到一个库中单独做报表查询,但是这些数据非常多,统计速度会存在问题,其实可以发现就算前面通过数据多主多从的情况下,如果数据量够大一样查询会出现问题,这种结构只分摊降低了每台数据库服务的查询次数,但对于每个从库中的数据依然还是非常巨大,除了我们需要在代码中写高效率的查询语句,建立索引等,我们还需要做什么呢?
对于数据库统计报表而言,对一个单独的统计读库操作各种聚合查询还是非常慢,其实这在业务上也是细节处理,可以分离聚合点,先统计一定时间内的生成一个统计数据,最后在聚合多个时间段....统计段位可以按照数据量去设计,比如每天、每月、每年、统计一次,举个例子最后处理这个月的报表,聚合的就只有30条左右数据
对于读库中的数据大表采用分表操作,按照指定的算法来处理分表,试想一个表中有10亿条数据,查询语句已经没有了优化空间,这个时候按照一定的规则拆分好表不失为一种好的处理方式,如果这些都做完了,我们就需要在硬件上升级处理了
当然还有一部分高并发通过先写到Redis中,然后在写到数据库中的这种
好了,就说这么多了