介绍
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果,并把获取的结果转为python对象。其中发sql到mysql服务器,从mysql服务器拿结果都是借助其他工具来完成的,例如pymysql.
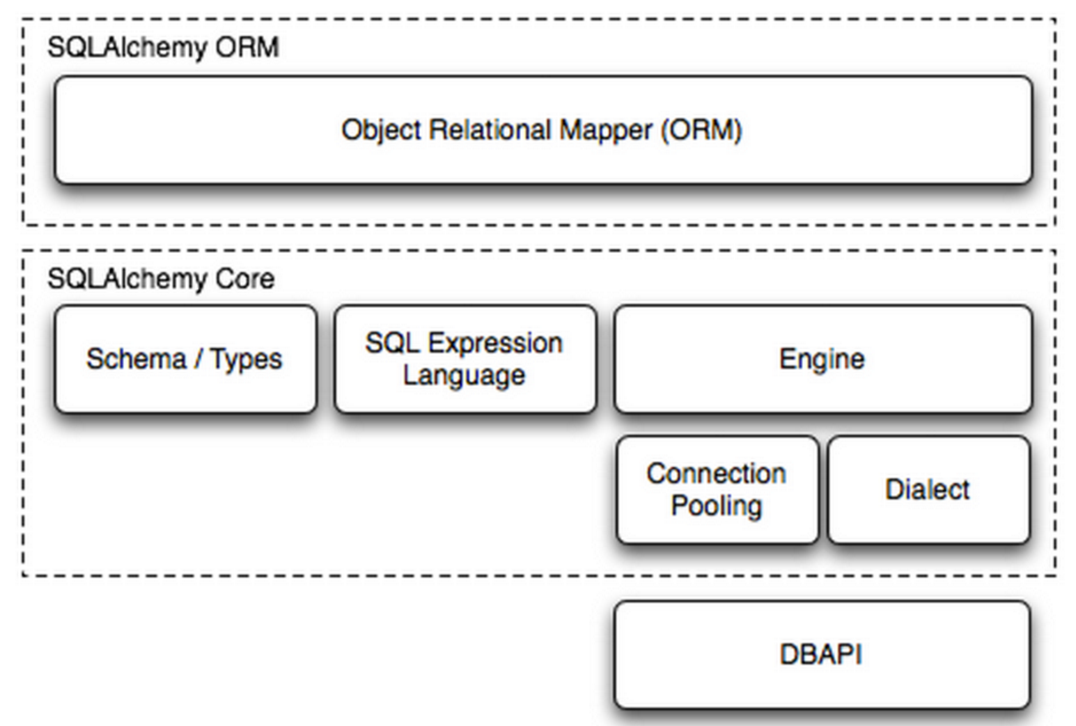
- Engine,框架的引擎
- Connection Pooling ,数据库连接池
- Dialect,选择连接数据库的DB API种类
- Schema/Types,架构和类型
- SQL Exprression Language,SQL表达式语言
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
单表
单表的创建
import datetime
import time
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy import Column
from sqlalchemy import Integer, String, Date
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8",
encoding='utf8',
max_overflow=0,
pool_size=5,
pool_timeout=20,
pool_recycle=-1
)
class User(Base):
# __tablename__ 字段必须有,否则会报错
__tablename__ = 'user'
# 不同于django model 会自动加主键,sqlalchemy需要手动加主键
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
# 时间类型的default的默认值需要使用datetime.date.today(), 但是使用flask-sqlalchemy的时候使用datetime.date.today
date = Column(Date, default=datetime.date.today())
def create_table():
# 创建所有的表,表如果存在也不会重复创建,只会创建新的表,而且sqlalchemy默认不支持修改表结构
# 要想和django orm一样能修改表结构并反映到数据库需要借助第三方组件
Base.metadata.create_all(engine)
def drop_table():
# 删除所有的表
Base.metadata.drop_all(engine)
单表的增删改查
# 增加
# user = User(name='jack')
# session.add(user)
# session.commit()
# session.close()
# # 增加多条
# user_list = [User(name='a'), User(name='b'), User(name='c')]
# session.add_all(user_list)
# session.commit()
# 查
# result 是一个列表,里面存放着对象
# result = session.query(User).all()
# for item in result:
# print(item.name)
# 查询最后加all() 得到的是一个存放对象的列表,不加all() 通过print 打印出的是sql语句
# 但是结果仍是一个可迭代的对象,只不过对象的__str__ 返回的是sql语句,迭代的时候里面的对象
# 是一个类元组的对象,可以使用下标取值,也可以通过对象的`.`方式取值
# result = session.query(User.name, User.date).filter(User.id>3)
# for item in result:
# print(item[0], item.date)
# 条件查询
from sqlalchemy import and_, or_,func
## 逻辑查询
r0 = session.query(User).filter(User.id.in_([1, 2]))
r1 = session.query(User).filter(~User.id.in_([1, 2]))
r2 = session.query(User).filter(User.name.startswith('j'), User.id>2)
r3 = session.query(User).filter(
or_(
User.id>3,
and_(User.name=='jack', User.id<2)
)
)
## 通配符
r4 = session.query(User).filter(User.name.like('%j'))
r5 = session.query(User).filter(~User.name.like('%j'))
## limit 和django orm 一样都是通过索引来限制
r6 = session.query(User)[0:4]
## 排序, 排序一般是倒数第二的位置,倒数第一是limit
r7 = session.query(User).order_by(User.id.desc())
## 分组和聚合
r8 = session.query(func.max(User.id)).group_by(User.name).all()
# 改, 得到的结果是收到影响的记录条数
# r9 = session.query(User).filter(User.id==2).update({'name': User.name + User.name.concat('hh')}, synchronize_session=False)
# 删除
session.query(User).delete()
## 子查询
session.query(User).filter(User.id.in_(session.query(User.id).filter(User.name.startswith('j'))))
session.commit()
# 这边的close并不是真实的关闭连接,而是完成终止事务和清除工作
session.close()
连表
两张表
创建表
import datetime
import time
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy import Column
from sqlalchemy import Integer, String, Date
from sqlalchemy import ForeignKey
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8",
encoding='utf8',
max_overflow=0,
pool_size=5,
pool_timeout=20,
pool_recycle=-1
)
class User(Base):
# __tablename__ 字段必须有,否则会报错
__tablename__ = 'user'
# 不同于django model 会自动加主键,sqlalchemy需要手动加主键
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
# 时间类型的default的默认值需要使用datetime.date.today(), 但是使用flask-sqlalchemy的时候使用datetime.date.today
date = Column(Date, default=datetime.date.today())
# 因为外键的sh设置更偏向于数据库底层,所以这里使用了表名,而不是类名
depart_id = Column(Integer, ForeignKey('department.id'))
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key=True)
# 默认的nullable 是True
title = Column(String(32), nullable=False)
查询
# 默认根据在类里面定义的外键进行on, 此时得到的结果是[(userobj, departmnetobj),()] 这种形式,默认是inner join
r1 = session.query(User, Department).join(Department).all()
r2 = session.query(User.name, Department.title).join(Department, Department.id==User.depart_id).all()
# 有了 isouter 参数,inner join 就变成 left join
r3 = session.query(User.name, Department.title).join(Department, Department.id==User.depart_id, isouter=True).all()
relationship
现在问题来了,想要查name是jack所属的部门名,两种方式
- 分两次sql查询
user = session.query(User).filter(User.name == 'jack').first()
title = session.query(Department.title).filter(Department.id == user.depart_id).first().title
- 一次连表查询
r1 = session.query(Department.title).join(User).filter(User.name == 'jack').first().title
print(r1)
这样的方式在python代码的级别貌似没有django的方便,django 的 orm 拿到一个对象obj, obj.deaprtment.title 就能拿到结果。sqlalchemy也有类似功能,通过relationship来实现。
# 注意,导入的是relationship,而不是relationships
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key=True)
# 默认的nullable 是True
title = Column(String(32), nullable=False)
# 如果backref 的那张表和这张表是一对一关系,加上一个uselist=False参数就行
user = relationship("User", backref='department')
class User(Base):
# __tablename__ 字段必须有,否则会报错
__tablename__ = 'user'
# 不同于django model 会自动加主键,sqlalchemy需要手动加主键
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
# 时间类型的default的默认值需要使用datetime.date.today(), 但是使用flask-sqlalchemy的时候使用datetime.date.today
date = Column(Date, default=datetime.date.today())
# 因为外键的sh设置更偏向于数据库底层,所以这里使用了表名,而不是类名
depart_id = Column(Integer, ForeignKey('department.id'))
# 神奇的一点是,SQLAlchemy会根据关系的对应情况自动给关系相关属性的类型
# 比如这里的Department下面的user自动是一个list类型,而User由于设定了外键的缘故
# 一个user最多只能应对一个用户,所以自动识别成一个非列表类型
# 这样写两个relationship比较麻烦,在设置了外键的一边使用relationship,并且加上backref参数
# department = relationship("Department")
session_factory = sessionmaker(engine)
session = session_factory()
user = session.query(User).first()
print(user.department)
department = session.query(Department).first()
print(department.user)
有了relationship,不仅查询方便,增加数据也更方便。
# 增加一个用户ppp,并新建这个用户的部门叫IT
## 方式一
# d = Department(title='IT')
# session.add(d)
# session.commit() # 只有commit之后才能取d的id
#
# session.add(User(name='ppp', depart_id=d.id))
# session.commit()
## 方式二
# session.add(User(name='ppp', department=Department(title='IT')))
# session.commit()
# 增加一个部门xx,并在部门里添加员工:aa/bb/cc
# session.add(Department(title='xx', users=[User(name='aa'), User(name='bb'),User(name='cc')]))
# session.commit()
三张表
创建表
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy import Column
from sqlalchemy import Integer, String, Date
from sqlalchemy import ForeignKey, UniqueConstraint, Index
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False)
course_list = relationship('Course', secondary='student2course', backref='student_list')
class Course(Base):
__tablename__ = 'course'
id = Column(Integer, primary_key=True)
title = Column(String(32), index=True, nullable=False)
class Student2Course(Base):
__tablename__ = 'student2course'
id = Column(Integer, primary_key=True, autoincrement=True)
student_id = Column(Integer, ForeignKey('student.id'))
course_id = Column(Integer, ForeignKey('course.id'))
__table_args__ = (
UniqueConstraint('student_id', 'course_id', name='uix_stu_cou'), # 联合唯一索引
# Index('student_id', 'course_id', name='stu_cou'), # 联合索引
)
查询
查询方式和只有两张表的情况类似,例如查询jack选择的所有课
# obj = session.query(Student).filter(Student.name=='jack').first()
# for item in obj.course_list:
# print(item.title)
创建一个课程,创建2学生,两个学生选新创建的课程
# obj = Course(title='英语')
# obj.student_list = [Student(name='haha'),Student(name='hehe')]
#
# session.add(obj)
# session.commit()
执行原生sql
方式一
# 查询
# cursor = session.execute('select * from users')
# 拿到的结果是一个ResultProxy对象,ResultProxy对象里套着类元组的对象,这些对象可以通过下标取值,也可以通过对象.属性的方式取值
# result = cursor.fetchall()
# 添加
cursor = session.execute('INSERT( INTO users(name) VALUES(:value)', params={"value": 'wupeiqi'})
session.commit()
print(cursor.lastrowid)
方式二
import pymysql
conn = engine.raw_connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(
"select * from user"
)
result = cursor.fetchall()
# 结果是一个列表,列表里面套着的对象就是原生的字典对象
print(result)
cursor.close()
conn.close()
多线程情况下的sqlalchemy
在每个线程内部创建session并关闭session
session_factory = sessionmaker(engine)
def task(i):
# 创建一个会话对象,没错仅仅是创建一个对象这么简单
session = session_factory()
# 执行query语句的时候才会真真去拿连接去执行sql语句,如果没有close那么没有空闲连接就会等待
result = session.execute('select * from user where id=14')
for i in result:
print(i.name)
time.sleep(1)
# 必须要close,这里的close可以理解为关闭会话,把链接放回连接池
# 如果注释掉这一句代码,程序会报错QueuePool limit of size 5 overflow 0 reached, connection timed out, timeout 20
session.close()
if __name__ == '__main__':
for i in range(10):
t = Thread(target=task, args=(i,))
t.start()
结果是每5个一起打印
在全局创建一个特殊的session,各个线程去使用这个特殊的session
from sqlalchemy.orm import scoped_session
session_factory = sessionmaker(engine)
session = scoped_session(session_factory)
def task(i):
result = session.execute('select * from user where id=14')
for i in result:
print(i.name)
time.sleep(1)
session.remove()
if __name__ == '__main__':
for i in range(10):
t = Thread(target=task, args=(i,))
t.start()
scoped_session 这个类还真是神奇,名字竟然还不是大写,而且原先的session有的,这个类实例化的对象也会有。我们第一反应是继承,其实它也不是继承。它的实现原理是这样的
执行导入语句的from sqlalchemy.orm import scoped_session的时候,点进去看源码发现执行了一个scoping.py的文件。


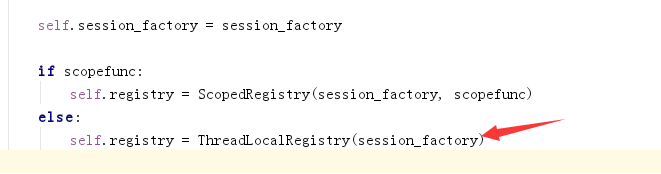

最终self.registry()就是session_factory() 对象,而且是线程隔离的,每个线程有自己的会话对象