写在前面的话:
该系列博文是我学习《 Hive源码解析与开发实战》视频课程的一个笔记,或者说总结,暂时没有对视频中的操作去做验证,只是纯粹的学习记录。
有兴趣看该视频的博友可以留言,我会共享出来,相互交流学习 ^.^。
*********************************************************************************************************
一、Hive数据导出:
1.1、导出的方式:
1.1.1、hadoop命令的方式:
因为hive执行的结果数据是保存在hdfs上面的,所以可以直接用hadoop命令将数据导出。主要包括get和text。
演示:

于是在相应目录下就多了一个newdata的文件,其中/*的星号表示获取该目录下所有文件的所有内容,然后追加到newdata文件中去。注意第一个路径是hdfs上的路径,第二个路径是获得的数据要存放到本地那个位置。
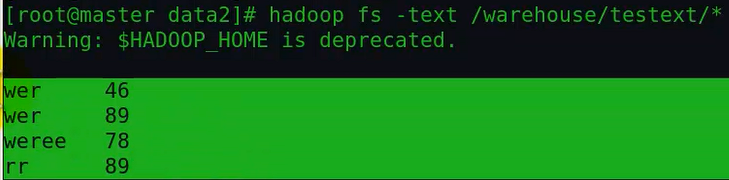
上面这个命令把/warehouse/testext/目录下所有文件的所有内容打印到控制台,当然如果想保存到本地某个文件可以用linux重定向写到一个文件中(当然也可以用>>来追加):

使用 hadoop fs -text 命令可以对多种数据格式文件进行操作,也就是说适合多种文件格式的数据导出。
1.1.2、通过INSERT ...DIRECTORY方式:

把查询的结果保存到本地的一个目录或者hadoop的hdfs上。其中第二行的row format表示保存的数据以什么样的分隔符保存,这种只在本地保存的情况才支持,hdfs上保存不支持这种写法。
演示:
这种方式需要在hive客户的执行。

最终会在data3这个目录下生产一个文件,这个文件包含了查询结果的数据:

查看该文件内容:
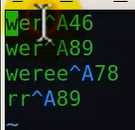
这里由于我们在insert的时候没有指定分隔符,所以在这里采用hive默认的分割符。我们指定下分隔符:

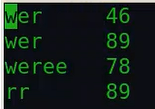
由于这里我设置一' '作为分割符,所以结果为:
另外还可以将数据保存到hdfs上去,但这样就不能够使用row format,否则会报错,所以输入下面的命令:

执行完上述命令后会在hdfs相应的目录下产生结果。
查看结果如下:
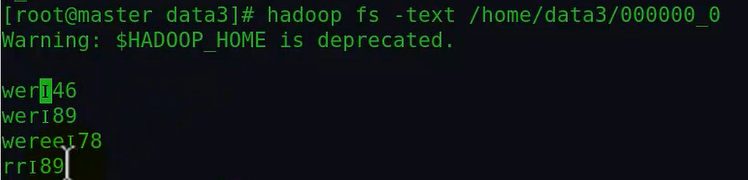
由于这种方式无法指定分隔符,所以采用了系统默认的分隔符I,这可以说是Hive的缺陷,因为hdfs上不允许再指定分隔符了。这样的话不如写到本地目录,还可以指定分割符。
1.1.3、Shell命令加管道:
hive -f/e | sed/grep/awk >file

1.1.4、第三方工具:
比如sqoop,把非关系型数据库和关系型数据库互相导入。
二、动态分区:
注意:下面动态分区的两个参数应该为nonstrict和strict而不是nonstrick;下面可能写错了。

使用动态分区之前,需要设定一些参数:

一个表一天产生的分区数最多不要超过1000个分区,否则的话,Mysql会出问题。
使用动态分区,上面配置的前两个必须设置,后面的设置是可选的。当然这些设置是直接在hive终端中设置,仅对当前hive终端有效。
演示:
①首先创建一个分区表:
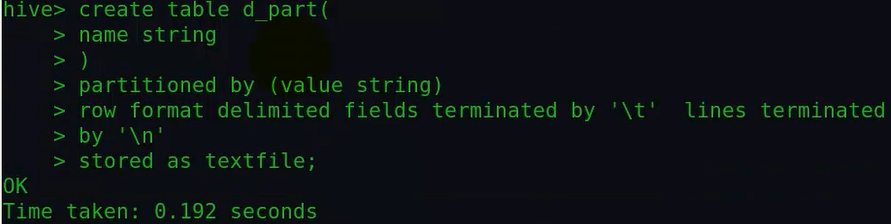
虽然这个时候指明了分区字段,但此时还没有分区,同时也没有数据。
然后我们考虑通过查询向其中插入数据:
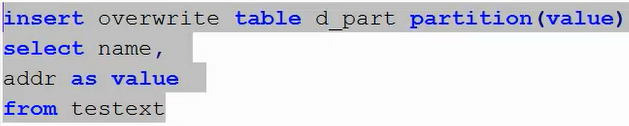
首先对比之前往指定分区插入数据的区别:
①之前,在往指定分区中插入数据的时候,指定分区是需要些分区字段值的,比如:partition(vale='34'),但是在这里没有;
②之前,只需要select查询出要插入的字段值,不用查询并指定分区字段值,也就是这里多了:addr as value;
上面这条插入语句的意思是:从testext中查询name和addr字段的值,其中name字段的值直接插入到d_part相应字段,addr字段指定为分区字段;最后按照这样的方式
插入d_part表中;这就是动态分区。
演示一个分区的情况下的动态分区:

这里报错,因为hive默认是strict设置,即:静态分区,因此我们需要进行设置hive为nonstrict,并且同时还要开启动态分区:
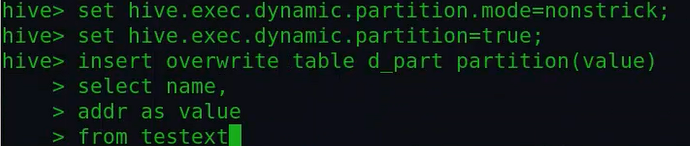
然后我们可以看下该表是否有数据了,以及有哪些分区:
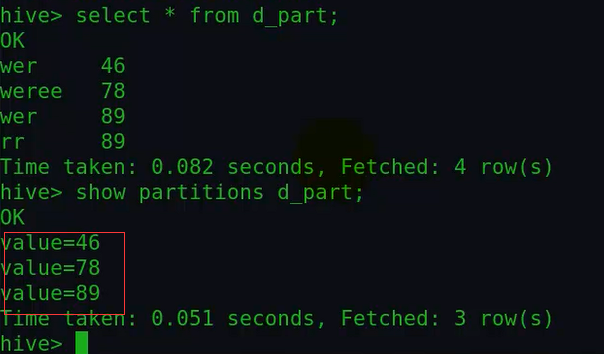
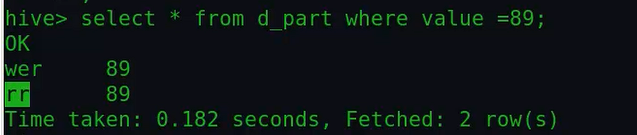
可以看到这里的几个分区是动态根据查询另外一个表动态生成的。我们可以按照下面的方式查看下,89分区下面的值:
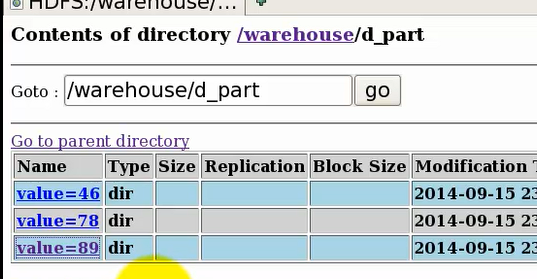
查看下hdfs上该表的目录结构,发现确实产生了三个分区:
演示有两个分区情况下的动态分区:
①首先创建分区表:
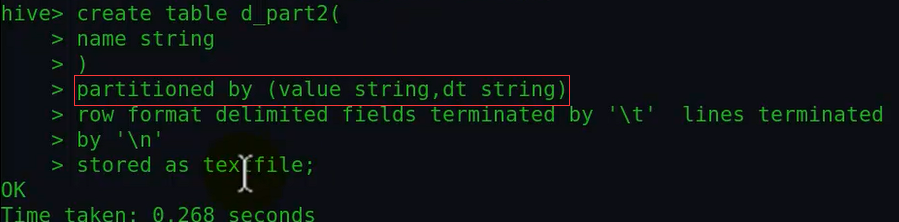
②然后查询插入数据,在hive终端输入下面的语句:
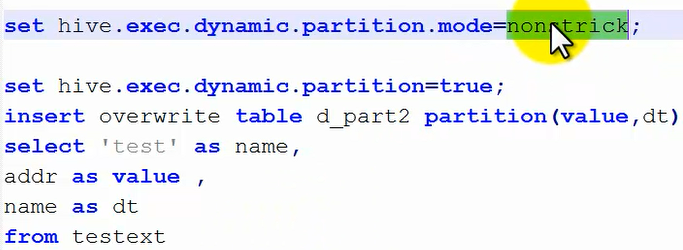
另外查看属性值,用"set 属性名 " 的方式。
执行完插入之后,我们可以查看下分区:
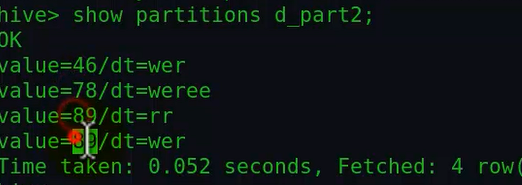
注意前面的value是以及分区目录,后面dt为二级分区。
另外如果是静态分区的话,那么第一个分区必须是静态分区,也就是在插入的时候,partition(...)中的第一个值必须进行赋值,当然也可以有多个静态分区,但静态分区必须放在前面,比如:

最后注意:partition(。。)括号中字段顺序必须和创建表的时候指定的分区顺序一致,同时和后面select查询插入字段的顺序一致。