可运用于 网页黑名单系统 垃圾邮件过滤系统 爬虫的网址判重系统等数据量很大的问题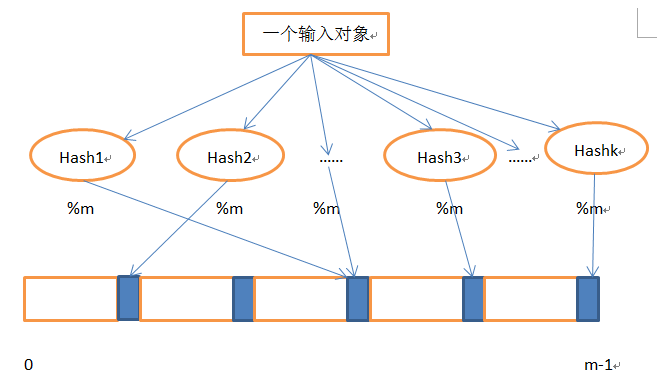
--好的哈希函数能将很多输入均匀地分布在bit array上,将所有值%m,可以分布到0~m-1上。处理过程如上图所示,一个对象经过k个哈希函数处理后,得到k个值,根据这k个值将对应的bit做标记。处理完所有输入之后,一个布隆过滤生成结束。
--检查阶段,对于一个输入a,如果,经过哈希处理后有一个bit没有被标记,那么该输入就不存在测试集合中,反之,则存在。
但是,如果测试集合很多,那么bit array 可能大部分被标记,即使某一个输入并不是测试集合中的记录,但是很有可能他所对应的bit都是标记过的。要排除这种情况,就要合理地设计bit array 的大小m,哈希函数的个数k,针对给定的失误率p,就有以下公式:
m = -(n*lnp)/(ln2)2
k = ln2 * (m/n) 其中n为测试集合中记录条数