(一)Scrapy库概述
1,安装:pip install scrapy失败;
运行D:PythonPython36python.exe -m pip install --upgrade pip命令升级pip命令失败;
修改Python36文件的权限:https://www.cnblogs.com/liaojiafa/p/5100550.html
安装:D:PythonPython36python.exe -m pip install wheel
安装:D:PythonPython36python.exe -m pip install scrapy
2,框架概述:


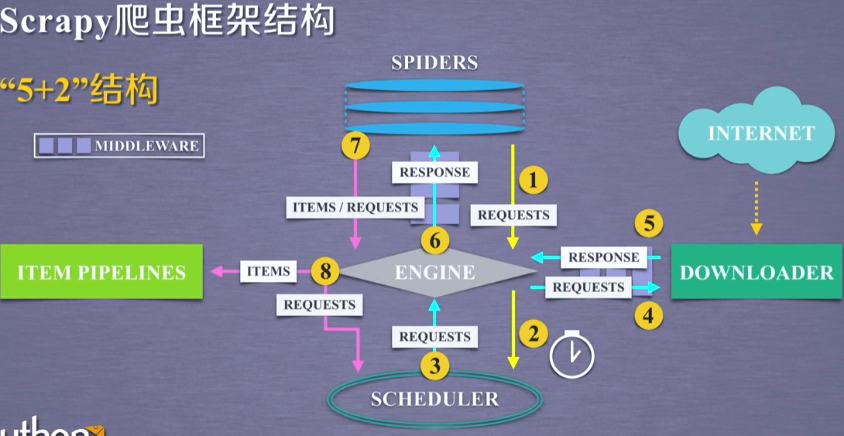
入口:SPIDERS;出口:ITEM PIPELINES;用户编写SPIDERS(URL),ITEM PIPELINES(对数据处理)
ENGINE:控制所有模块之间的数据流,根据条件触发事件,不允许用户修改,代码已实现
DOWNLOADER:根据请求下载网页,功能单一,不允许用户修改,代码已实现
SCHEDULER:对所有爬取请求进行调度管理,不允许用户修改,代码已实现
DOWNLOADER MIDDLEWARE:用户可以修改配置;中间件

SPIDERS:解析DOWNLOADER返回的响应(Response);产生爬取项(scraped item);产生额外的爬取请求(Request);需要用户编写的最核心代码
ITEM PIPELINES:以流水线方式处理Spider产生的爬取项;由一组操作顺序组成,每个操作是一个item pipelines类型;操作可包括:清理,检验,查重爬虫项中HTML数据
将数据存入数据库;由用户编写功能
SPIDER MIDDLEWARE:中间件

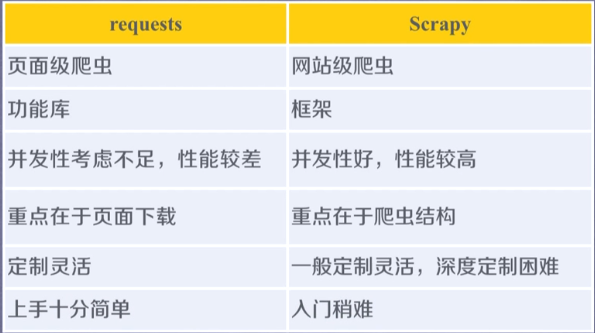
3,requests库和Scrapy库区别:


(二)Scrapy库的使用
1,Scrapy命令行:常用命令:创建过程,创建爬虫,运行爬虫为最常用命令

2,爬取某个HTML:
(1)建立过程: scrapy startproject python123demo

(2)建立爬虫demo:scrapy genspider demo python123.io;建立demo.py文件
#demo.py # -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' allowed_domains = ['python123.io'] #说明只能爬取这个文件下的URL start_urls = ['http://python123.io/'] def parse(self, response): #处理响应,解析内容形成字典,发现新的URL爬取请求 pass
(3),修改爬虫文件deom.py文件
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' # allowed_domains = ['python123.io'] #说明只能爬取这个文件下的URL start_urls = ['http://python123.io/ws/demo.html'] def parse(self, response): #处理响应,解析内容形成字典,发现新的URL爬取请求 fname=response.url.split("/")[-1] with open(fname,"wb") as f: f.write(response.body) self.log("保存文件:%s"%name)
(4),运行爬虫:scrapy crawl demo
2,yield:

例子:


3,相关类:
(1)request类:

(2)response类:

(3)Item类:类字典类型,可以按照字典类型操作;表示从HTML中提取的内容
4,CSS Selector:


5,高级使用:

(三)实例:
实例一:
1,功能:

2,实现难点:
3,准备工作:网站选取原则:

爬取链接:http://quote.eastmoney.com/stock_list.html#sh 东方财富股票综合排名
http://gu.qq.com/xxxxxx/gp 腾讯个股股票信息
先爬取股票综合排名:获取股票代码,放入搜狐股票的链接中转到个股信息
爬取股票综合排名网页发现:股票简略信息都在<tbody class="tbody_right" id="datalist"></tbody>中;一个行内是一支股票的信息;一行的第一列是代码,第二列 是股票名称
4,步骤:
(1),创建工程和爬虫 : 工程BaiduStock scrapy startproject BaiduStock 爬虫stocks scrapy genspider stocks www.xxx.com
(2),编写stocs.py文件:先从东方财富网获取所有股票代码 ,然后根据每个股票代码找到腾讯股票的个股信息,将个股信息封装到infoDict字典中,最后将爬取数据传入PIPELINES
(3),编写PIPELINES,配置pipelines.py文件:定义对爬取项的处理类;配置ITEM_PIPELINES选项
(4),运行爬虫:scrapy crawl stocks
#stocks.py文件 # -*- coding: utf-8 -*- import scrapy import re import requests from bs4 import BeautifulSoup import bs4 class StocksSpider(scrapy.Spider): name = 'stocks' start_urls = ['http://quote.eastmoney.com/stock_list.html#sh'] def parse(self, response): html=response.body soup=BeautifulSoup(html,"html.parser") hrefs=soup.find_all(name="a") for href in hrefs: #从东方财富网爬取所有的股票排行 try: href=href.attrs["href"] stock=re.findall(r"[s][hz]d{6}",href)[0] #获取代码 url="http://gu.qq.com/"+stock+"/gp" yield scrapy.Request(url,callback=self.parse_stock) except: continue def parse_stock(self,response): #从腾讯股票个股网页获取个股信息封装到字典infoDict中 infoDict={} for item in response.css('.title_bg'): stock_name= item.css('::text').extract()[0] stock_code=item.css('::text').extract()[1] html=response.body print(response.url) soup=BeautifulSoup(html,"html.parser") div=soup.find(name="div",attrs={"class":"content clear"}) span=div.find_all(name="span") dspan=span[1::2] ospan=span[::2] stock_price=ospan[0].string #股票价格 stock_change_point=ospan[1].string #股票变化点 infoDict.update({"股票名称":stock_name,"股票代码":stock_code,"股票价格":stock_price,"股票变化点":stock_change_point}) key=[] val=[] for i in ospan[2:15]: rE=r"[[a-z]{0,2}d{0,4}]" agei=re.sub(rE,"",i.string) agei="".join(agei.split()) key.append(agei) #key中存放股票汉字提示信息 for j in dspan[1:15]: #val中存放股票数据信息 val.append(j.string) key.insert(0,"涨跌幅") for i in range(len(key)): kv=key[i] va=val[i] infoDict[kv]=va #新增内容 #print(infoDict) yield infoDict #将字典内存的数据封装为Item类转入PIPELINES
#pipelines.py文件 # -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html class BaidustockPipeline(object): def process_item(self, item, spider): return item class BaidustockInfoPipeline(object): def open_spider(self,spider): #爬虫被调用时pipline启动的方法 self.f=open("StockInfo.txt","w") def close_spider(self,spider): #关闭方法 self.f.close() def process_item(self,item,spider): #对每一个pipeline项处理方法 try: line=str(dict(item))+' ' self.f.write(line) #将数据写入文件 except: pass return item
#settings.py文件修改部分 ITEM_PIPELINES = { 'BaiduStock.pipelines.BaidustockInfoPipeline': 300, }

5,Scrapy提供优化:需要修改,通过改变并发
