-
定义数据源 写一个配置文件,可命名为logstash.conf,输入以下内容:
-
input { file { path => "/data/web/logstash/logFile/*/*" start_position => "beginning" #从文件开始处读写 } # stdin {} #可以从标准输入读数据 }
2、数据的格式
-
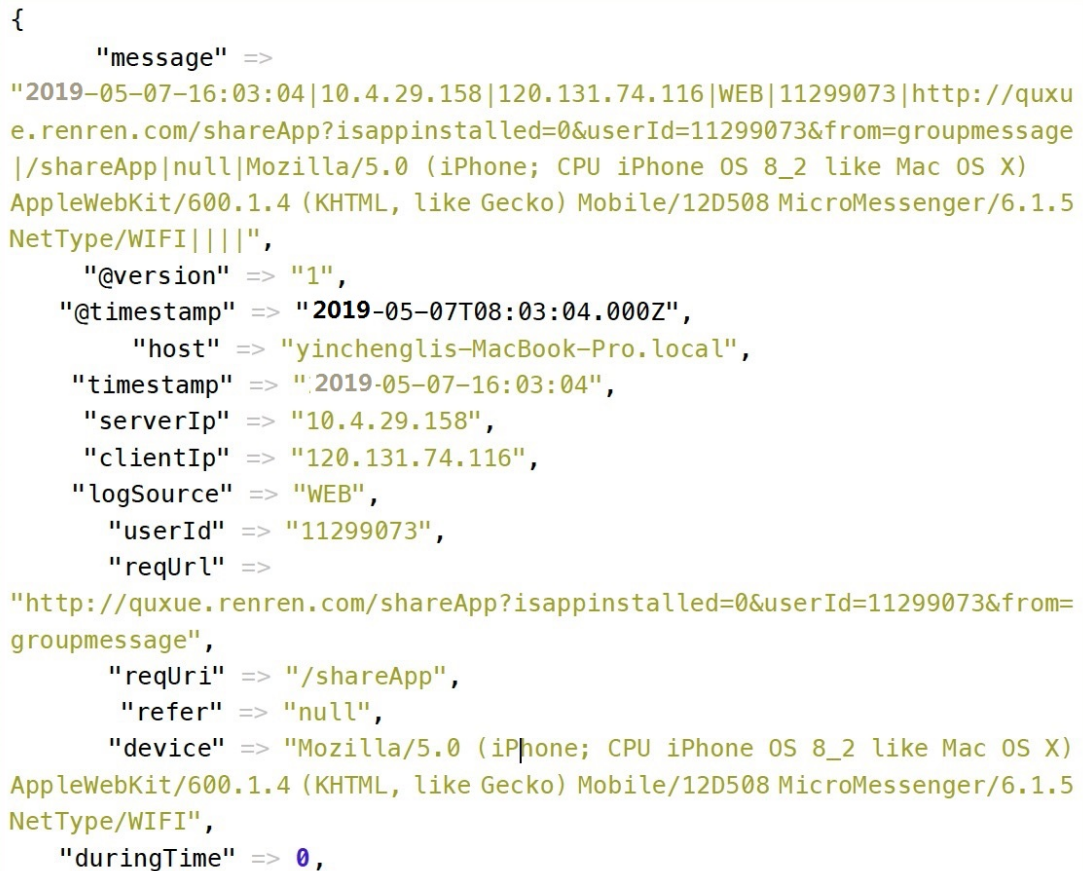
filter { #定义数据的格式 grok { match => { "message" => "%{DATA:timestamp}|%{IP:serverIp}|%{IP:clientIp}|%{DATA:logSource}|%{DATA:userId}|%{DATA:reqUrl}|%{DATA:reqUri}|%{DATA:refer}|%{DATA:device}|%{DATA:textDuring}|%{DATA:duringTime:int}||"} } }
由于打日志的格式是这样的:
2019-05-07-16:03:04|10.4.29.158|120.131.74.116|WEB|11299073|http://quxue.renren.com/shareApp?isappinstalled=0&userId=11299073&from=groupmessage|/shareApp|null|Mozilla/5.0
(iPhone; CPU iPhone OS 8_2 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Mobile/12D508 MicroMessenger/6.1.5 NetType/WIFI|duringTime|98||
如上面代码,依次定义字段,用一个正则表达式进行匹配,DATA是
filter { #定义数据的格式 grok {#同上... } #定义时间戳的格式 date { match => [ "timestamp", "yyyy-MM-dd-HH:mm:ss" ] locale => "cn" } }
在上面的字段里面需要跟logstash指出哪个是客户端IP,logstash会自动去抓取该IP的相关位置信息:
filter { #定义数据的格式 grok {#同上} #定义时间戳的格式 date {#同上} #定义客户端的IP是哪个字段(上面定义的数据格式) geoip { source => "clientIp" } }
同样地还有客户端的UA,由于UA的格式比较多,logstash也会自动去分析,提取操作系统等相关信息
#定义客户端设备是哪一个字段 useragent { source => "device" target => "userDevice" }
哪些字段是整型的,也需要告诉logstash,为了后面分析时可进行排序,使用的数据里面只有一个时间
#需要进行转换的字段,这里是将访问的时间转成int,再传给Elasticsearch mutate { convert => ["duringTime", "integer"] }
output { #将输出保存到elasticsearch,如果没有匹配到时间就不保存,因为日志里的网址参数有些带有换行 if [timestamp] =~ /^d{4}-d{2}-d{2}/ { elasticsearch { host => localhost } } #输出到stdout # stdout { codec => rubydebug } #定义访问数据的用户名和密码 # user => webService # password => 1q2w3e4r }
案例5:使用logstash收集指定文件中的数据,将结果输出到控制台上;且输出到kafka消息队列中。 核心配置文件:logstash2kafka.properties input { file { # 将path参数对应的值:可以是具体的文件,也可以是目录(若是目录,需要指定目录下的文件,或者以通配符的形式指定) path => "/home/root/data/access_log" # 每间隔5秒钟从文件中采集一次数据 discover_interval => 5 # 默认是end,以追加的形式在文件中添加新数据,只会采集新增的数据;若源文件中数据条数没有发生变化,即使数据内容发生了变更,也感知不到,不会触发采集操作 # 若指定beginning,每次都从头开始采集数据。若源文件中数据发生了变化(内容或是条数),都会感知到,都会触发采集操作 start_position => "beginning" } } output { kafka { topic_id => "accesslogs" # 用于定制输出的格式,如:对消息格式化,指定字符集等等 codec => plain { format => "%{message}" charset => "UTF-8" } bootstrap_servers => "JANSON01:9092,JANSON02:9092,JANSON03:9092" } stdout{} } 注意: 0,前提: 创建主题: [root@JANSON03 ~]# kafka-topics.sh --create --topic accesslogs --zookeeper JANSON01:2181 --partitions 3 --replication-factor 3 Created topic "accesslogs". [root@JANSON02 soft]# kafka-topics.sh --list --zookeeper JANSON01:2181 Hbase Spark __consumer_offsets accesslogs bbs gamelogs gamelogs-rt hadoop hive spark test test2 ①在真实项目中,logstash三大组件通过配置文件进行组装。不是直接通过-e参数书写在其后。 ./logstash -f 配置文件名 以后台进程的方式启动: nohup ./logstash -f 配置文件名 > /dev/null 2>&1 & ②需要将指定目录下所有子目录中的所有文件都采集到(后缀是.log) path => "/home/mike/data/*/*.log"
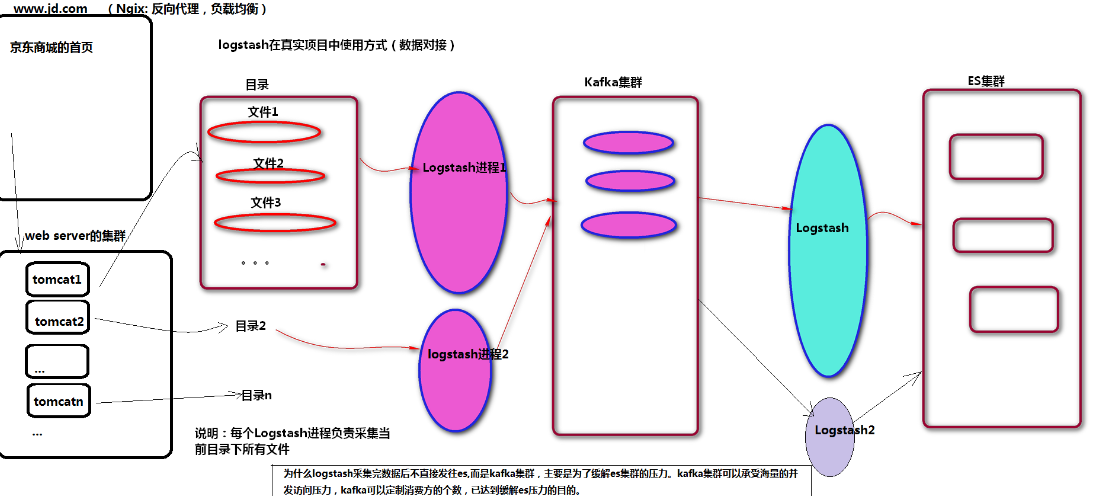
案例6:真实项目中logstash进行数据对接的过程 步骤: 1,使用logstash对指定目录下的日志信息进行采集,采集到之后,直接输出到kafka消息队列中。 原因:若目录下的文件是海量的,将数据采集后,直接发送给es的话,es因为承载不了压力可能会宕机。 通用的解决方案是: 先将日志信息采集到kafka消息队列中,然后,再使用logstash从kafka消息队列中读取出消息,发送给es 2, 使用logstash从kafka消息队列中采集数据,发送给es. 实施: 步骤1:游戏日志目录中所有子目录下所有的file使用logstash采集到kafka消息队列 (dir2kafka.properties) input { file { codec => plain { charset => "GB2312" } path => "/home/mike/data/basedir/*/*.txt" discover_interval => 5 start_position => "beginning" } } output { kafka { topic_id => "gamelogs" codec => plain { format => "%{message}" charset => "GB2312" } bootstrap_servers => "JANSON01:9092,JANSON02:9092,JANSON03:9092" } } 步骤2:使用logstash从kafka消息队列中采集数据,输出到es集群中 (kafka2es.properties) earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 __ input { kafka { client_id => "logstash-1-1" type => "accesslogs" codec => "plain" auto_offset_reset => "earliest" group_id => "elas1" topics => "accesslogs" -- 旧版本的logstash需要使用参数:topic_id bootstrap_servers => "JANSON01:9092,JANSON02:9092,JANSON03:9092" -- 旧版本的logstash需要使用参数:zk_connect=>"JANSON01:2181,xx" } kafka { client_id => "logstash-1-2" type => "gamelogs" auto_offset_reset => "earliest" codec => "plain" group_id => "elas2" topics => "gamelogs" bootstrap_servers => "JANSON01:9092,JANSON02:9092,JANSON03:9092" } } filter { if [type] == "accesslogs" { json { source => "message" remove_field => [ "message" ] target => "access" } } if [type] == "gamelogs" { mutate { split => { "message" => " " } add_field => { "event_type" => "%{message[3]}" "current_map" => "%{message[4]}" "current_X" => "%{message[5]}" "current_y" => "%{message[6]}" "user" => "%{message[7]}" "item" => "%{message[8]}" "item_id" => "%{message[9]}" "current_time" => "%{message[12]}" } remove_field => [ "message" ] } } } output { if [type] == "accesslogs" { elasticsearch { index => "accesslogs" codec => "json" hosts => ["JANSON01:9200", "JANSON02:9200", "JANSON03:9200"] } } if [type] == "gamelogs" { elasticsearch { index => "gamelogs" codec => plain { charset => "UTF-16BE" } hosts => ["JANSON01:9200", "JANSON02:9200", "JANSON03:9200"] } } } 以后台进程的方式启动: 注意点: 1, 以后台的方式启动Logstash进程: [mike@JANSON01 logstash]$ nohup ./bin/logstash -f config/dir2kafka.properties > /dev/null 2>&1 & [mike@JANSON01 logstash]$ nohup ./bin/logstash -f config/kafka2es.properties > /dev/null 2>&1 & 2, LogStash 错误:Logstash could not be started because there is already another instance usin... [mike@JANSON01 data]$ ls -alh total 4.0K drwxr-xr-x 5 mike mike 84 Mar 21 19:31 . drwxrwxr-x 13 mike mike 267 Mar 21 16:32 .. drwxrwxr-x 2 mike mike 6 Mar 21 16:32 dead_letter_queue -rw-rw-r-- 1 mike mike 0 Mar 21 19:31 .lock drwxrwxr-x 3 mike mike 20 Mar 21 17:45 plugins drwxrwxr-x 2 mike mike 6 Mar 21 16:32 queue -rw-rw-r-- 1 mike mike 36 Mar 21 16:32 uuid 删除隐藏的文件:rm .lock 3, logstash消费Kafka消息,报错:javax.management.InstanceAlreadyExistsException: kafka.consumer:type=app-info,id=logstash-0 当input里面有多个kafka输入源时,client_id => "logstash-1-1",必须添加且需要不同 如: kafka { client_id => "logstash-1-2" type => "gamelogs" auto_offset_reset => "earliest" codec => "plain" group_id => "elas2" topics => "gamelogs" bootstrap_servers => "JANSON01:9092,JANSON02:9092,JANSON03:9092" } 4, 将游戏日志文件中的数据变化一下,就可以被logstash感知到,进而采集数据。
常用两个配置:
1. 将日志采集到kafka :
input { file { codec => plain { charset => "UTF-8" } path => "/root/logserver/gamelog.txt" //tmp/log/* 路径下所有 discover_interval => 5 start_position => "beginning" } } output { kafka { topic_id => "gamelogs" codec => plain { format => "%{message}" charset => "UTF-8" } bootstrap_servers => "node01:9092,node02:9092,node03:9092" } }
2.将kafka 的日志保存es :
input { kafka { type => "accesslogs" codec => "plain" auto_offset_reset => "smallest" group_id => "elas1" topics => "accesslogs" bootstrap_servers => "node01:9092,node02:9092,node03:9092" } kafka {
client_id => "logstash-1-2"
type => "gamelogs"
auto_offset_reset => "earliest"
codec => "plain"
group_id => "elas2"
topics => "gamelogs"
bootstrap_servers => ["192.168.18.129:9092"]
} } filter { if [type] == "accesslogs" { json { source => "message" remove_field => [ "message" ] target => "access" } } if [type] == "gamelogs" { mutate { split => { "message" => "|" } add_field => { "event_type" => "%{message[0]}" "current_time" => "%{message[1]}" "user_ip" => "%{message[2]}" "user" => "%{message[3]}" } remove_field => [ "message" ] } } } output { if [type] == "accesslogs" { elasticsearch { index => "accesslogs" codec => "json" hosts => ["node01:9200", "node02:9200", "node03:9200"] } } if [type] == "gamelogs" { elasticsearch { index => "gamelogs" codec => plain { charset => "UTF-16BE" } hosts => ["node01:9200", "node02:9200", "node03:9200"] } } }