一、概述
我们之前介绍过Tahoe版本中,无论是快速重传还是RTO超时重传,都会触发乘法减小,将cwnd置为1,然后重新开始慢启动过程。在reno版本中引入快速回复,当发生快速重传的时候,就会触发快速恢复过程,但是reno中的快速恢复过程在收到partial ACK的时候就会退出。在new reno中对快速恢复进行了改进,只有当收到的ack number越过recovery point的时候,才会退出快速恢复过程,而对于partial ACK,new reno则会立即进行一个快速重传。
RFC2582给出了new reno算法,即在没有SACK功能的情况下的快速恢复,我简单描述一下,详细的请参考RFC2582。
当TCP收到3个dup ACK触发快速重传的时候,先设置ssthresh = max (FlightSize / 2, 2*MSS),然后重传丢失的报文,设置cwnd=ssthresh+3*MSS,这个协议称为inflate,这个反映了有三个数据包离开中间网络到达了对端。
对于随后每个dup ACK,进行inflate操作:cwnd=cwnd+MSS,反映有一个数据包到达对端,如果cwnd和awnd允许,那么此时可以传输新的TCP数据
在收到partial ACK的时候,立即重传ack number对应的数据包,假设这个partial ACK的ack number确认了n*MSS的数据,那么更新cwnd=cwnd-n*MSS,这个协议称呼为deflate,接着更新cwnd=cwnd+1。
当收到的ACK报文使TCP越过Recovery point的时候,退出快速恢复,更新cwnd=min (ssthresh, FlightSize + MSS),或者直接更新cwnd=ssthresh,但是采用后一种更新方式的时候要避免cwnd的突然增大,而造成burst业务,影响网络稳定性。
二、Linux中的实现
Linux中的reno拥塞控制算法并不仅仅是BSD原始的reno拥塞控制算法,可以看成是BSD原始reno拥塞控制算法的扩展。在linux中设置reno拥塞控制算法的时候,也会进行快速恢复的过程,但是这个快速恢复的过程并不是reno拥塞控制算法实现的。下面我们介绍一下SACK关闭时候Linux中的快速恢复算法。
Linux中TCP连接初始建立的时候处于Open状态,当收到dup ACK的时候会立即进入Disorder状态,当连续收到的dup ACK总数达到dupthresh门限的时候,TCP会进入Recovery状态,然后触发快速重传,进入快速恢复过程。当收到的ack number越过recovery point的时候就会从Recovery状态切换到正常的Open状态。
Open状态下慢启动和拥塞避免对于cwnd的更新我们前面已经有介绍了,而Disorder状态下因为dup ACK的ack number并没有确认新的数据(这里指SACK关闭的场景下的dup ACK),因此cwnd并不会更新,下面我们则要介绍一下Recovery状态下cwnd的更新。下面这个流程不仅仅是关闭SACK的时候会用到,后面我们会介绍SACK和FACK下的快速恢复,同样也会使用到这个cwnd更新流程,所以说这个很重要啊。
Linux从Disorder状态进入Recovery状态的时候,会初始化prior_ssthresh=max(ssthresh,3/4*cwnd) , ssthresh=max(cwnd/2,2), prior_cwnd=cwnd, prr_delivered=0, prr_out=0。接着会进行下面的cwnd更新流程,在随后的Recovery状态下收到dup ACK或者partial ACK的时候都会执行下面的cwnd更新流程。相关新增的变量我已经在里面注释说明了。linux中并不会按照RFC2582来inflate或者deflate拥塞窗口,而是使用sacked_out这个状态变量来达到和协议中inflate和deflate相同的效果。
//进入Recovery状态时候 初始化prr_delivered、prr_out为0//newly_acked_sacked:表示收到的这个ACK报文的ack number和sack确认了多少个数据包,对于关闭SACK的情况下,dup ACK也算是新确认了一个报文//newly_acked_sacked的值实际上就是收到这个ACK报文前(packets_out-sacked_out)和收到这个报文后(packets_out-sacked_out)的差值if (newly_acked_sacked <= 0 )return;delta = ssthresh - in_flight;prr_delivered += newly_acked_sacked;if (delta < 0) {//注意下面的除法要向下取整sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out} else if (ack number新确认了之前重传的数据且RACK没有标记重传报文丢失) {sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1);} else {sndcnt = min(delta, newly_acked_sacked);}//fast_rexmit:当前dup ACK是否已经达到了dupthresh门限而需要快速重传,仅在初始进入Recovery状态触发快速重传的时候置位sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0));cwnd = in_flight + sndcnt;//然后根据拥塞窗口大小可能会进行数据重传或者新数据的发送 并更新prr_out
可以看到linux实现中在进入快速恢复的时候cwnd并不是按照cwnd=ssthresh+3*MSS来初始化的,实际上这个linux中的这个cwnd更新流程是参考RFC6973实现的,称呼为PRR算法,一定要记住这个PRR更新算法,后面各种Recovery状态和CWR状态下cwnd的更新都会用到,后面介绍FACK的时候我们会简单介绍一下PRR的背景。
当TCP从Recovery状态切换回到Open状态的时候cwnd如何更新呢?下一篇文章我们会进行介绍。
三、wireshark示例
同样在执行示例前如下设置TCP参数,这里设置ssthresh=10,initcwnd=12,这也意味着server端在建立连接后直接进入拥塞避免阶段。并不是所有的TCP连接一开始都处于慢启动阶段的。1990年最初的BSD中的reno版本的tcp是没有SACK功能的,我们先来看一下非SACK下,linux TCP的处理,因此设置tcp_sack=0。
******@Inspiron:~$ sudo ip route add local 127.0.0.2 dev lo congctl reno initcwnd 12 ssthresh lock 10 #参考本系列destination metric文章******@Inspiron:~$ sudo ethtool -K lo tso off gso off #关闭tso gso以方便观察cwnd变化
1、SACK关闭场景下的快速重传和快速恢复
在介绍下面的示例前我们在介绍两个linux内核中的状态变量,第一个是high_seq,这个状态变量表示重传的recovery point的系列号,关于recovery point的信息请参考前面重传相关的文章,high_seq会在TCP进入Disorder状态或Recovery状态的时候更新为SND.NXT(当然进入loss状态也会更新)。另外一个是retransmit_high,在关闭sack选项的情况下,这个变量表示当前TCP重传报文的时候能最大的重传系列号,也就是TCP认为已经丢失需要进行重传的最大系列号。
业务场景:server端建立连接后,休眠1000ms,然后应用层连续write30次,每次写入50bytes,写入间隔为3ms。client与server端建立连接后,立即发送一个请求报文,另外server端第4、5、11次write写入的数据(分别对应下图中的No9、No10和No16报文)在传输的过程中丢失。client端对收到的每个报文都会回复一个ACK确认包,client与server端的时延为50ms。
No1-No3:client与server端通过三次握手建立连接,client端的mss为62bytes,扣除掉12bytes的TSopt选项后,server端每次只能发送50bytes数据。为了简洁,TSopt选项的信息设置没有在Info列显示。另外可以看到server端的No2数据包中并没有SACK_PERM选项。server端初始化cwnd=12, ssthresh=10, packets_out、 sacked_out、 lost_out、 retrans_out、 cwnd_cnt等变量此时也为0,如果对这些状态变量的含义不清楚,请翻看前面相关的文章。同样high_seq和retransmit_high初始值也为0。另外tcp拥塞控制状态机初始处于Open态。
No4-No5:client发送一段请求报文,server端立即回复了No5确认包。
No6-No17:server端连续发出12数据包后,受限于cwnd,不能在额外发出新的数据。发出No17后可以看到in_flight列值正好为600bytes。此时packets_out=12与之对应。
No18-No19:拥塞避免过程,reno更新cwnd_cnt=cwnd_cnt+1=1。
No20-No21、No22-No23:这两组数据与No18、No19类似,同样是拥塞避免过程。收到No12后 cwnd_cnt=3。
No24-No25:No22的ack number确认了No8报文,因为No9和No10这两个数据包丢失,因此client在接收到No11数据包的时候回复No24这个dup ACK。server端在收到这个dup ACK后,拥塞状态机从Open切换到Disorder状态,更新high_seq=snd_nxt=751(相对系列号)。之前我们说过在打开SACK功能的时候,sacked_out表示通过SACK确认的数据包的个数,在关闭SACK的时候,sacked_out表示收到的dup ACK的个数。我们在测试这个示例前设置tcp_sack=0,因此收到No24后,server端更新sacked_out=sacked_out+1=1。此时linux计算的in_flight = packets_out - ( sacked_out + lost_out) + retrans_out =12-(1+0)+0=11(可以看到linux内部维护的in_flight此时已经和wireshrk中的in_flight列不一致了),而这个时候cwnd=12,server端仍然可以发出一个新的数据包,即对应No25,更新packets_out=packets_out+1=13。因为这个dup ACK的ack number并没有确认新的数据包,因此reno并不会更新cwnd。
No26-No27:这组数据与No24-No25类似,这里不再重复叙述。发出No27后,packets_out=14,sacked_out=2。因为拥塞控制状态仍然为Disorder,因此high_seq仍然为751。
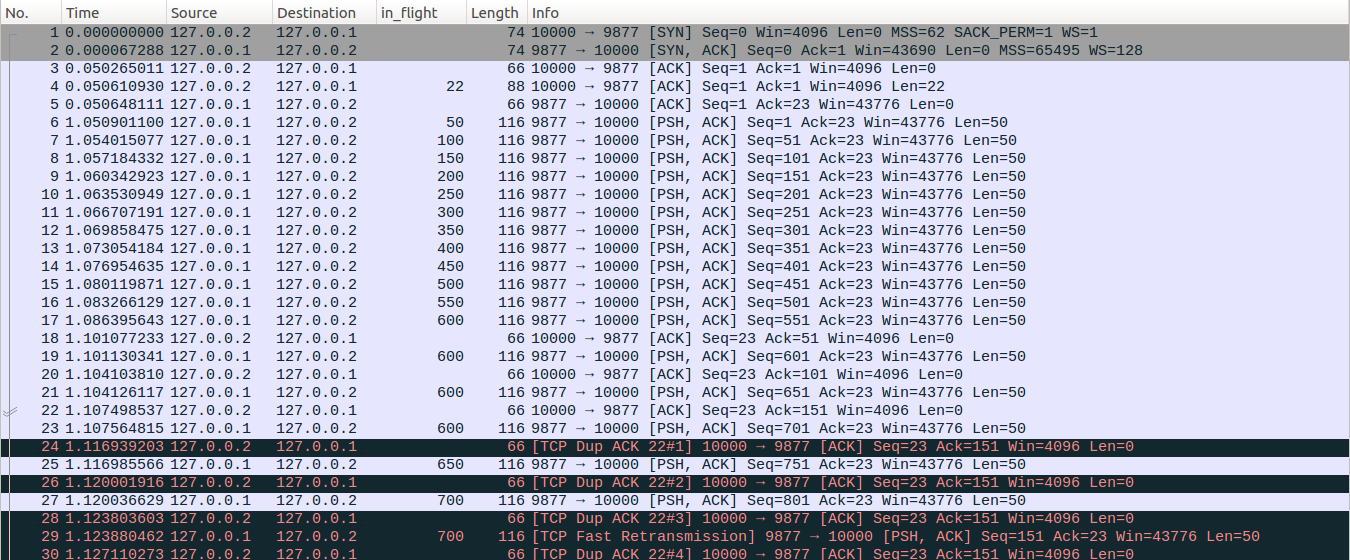
No28-No29:server端收到No28报文后,发现当前dup ACK的个数已经满足快速重传门限,即sacked_out=3 >= dupthresh=3,server端判断TCP传输已经发生了丢包,在没有SACK的前提下,linux收到三个dup ACK只能认为丢失了一个数据包,因此更新lost_out=1,retransmit_high=201(相对系列号),并置位fast_rexmit=1表示当前需要进行快速重传。此时server端拥塞控制状态机进入Recovery状态,初始进入Recovery状态的时候,会更新high_seq=snd_nxt=851,重置cwnd_cnt=0,prr_delivered=0,prr_out=0,prior_cwnd=cwnd=12,使用reno算法的回调接口(ssthresh)初始化ssthresh=max(cwnd/2,2)=6。接着更新newly_acked_sacked=1,prr_delivered = prr_delivered +1 = 1,此时in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 14-(3+1)+0=10,delta=ssthresh-in_flight=-4<0,接着sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out = (6*1+11)/12-0=1,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,1)=1,因此最终更新cwnd = in_flight + sndcnt = 10+1=11。
最后进行快速重传,发出No29数据包,更新retrans_out=1,prr_out=prr_out+1=1,in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 14-(3+1)+1=11,与此时的拥塞窗口cwnd相同。受限于拥塞控制linux此时不能在重传其他的数据或者发送新数据了。
No30:server端收到No30这个dup ACK的时候,更新sacked_out=sacked_out+1=4,newly_acked_sacked=1,prr_delivered = prr_delivered +1 = 2,fast_rexmit=0,此时in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 14-(4+1)+1=10,delta=ssthresh-in_flight=-4<0,接着sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out =(6*2+11)/12-1=0,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(0,0)=0,因此最终更新cwnd = in_flight + sndcnt = 10+0=10。可以看到收到No30数据包后拥塞窗口cwnd减小了1。所以虽然No30这个dup ACK代表对端有乱序包到达,linux内部维护的in_flight也减小了1,但是此时in_flight已经与cwnd相同,因此不能在额外重传或者发送新的数据。
No31-No32:server端收到No31这个dup ACK的时候,更新sacked_out=sacked_out+1=5,newly_acked_sacked=1,prr_delivered = prr_delivered +1 = 3,fast_rexmit=0,此时in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 14-(5+1)+1=9,delta=ssthresh-in_flight=-3<0,接着sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out =(6*3+11)/12-1=1,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,0)=1,因此最终更新cwnd = in_flight + sndcnt = 9+1=10。可以看到cwnd实在in_flight的基础上加了1,因此此时允许额外在重传一个数据包或者发出一个新的数据包。接着TCP进入重传流程尝试重传No10报文,但是No10报文的Seq=201,而retransmit_high也为201,不满足Seq<retransmit_high条件,也就是linux认为No10报文当前还没有丢失,因此放弃重传。接着尝试发送新的未发送的数据包并发送成功,即对应No32数据包,更新packets_out=packets_out+1=15、prr_out=prr_out+1=2。
No33-No35:与No30-No32处理过程类似。No35后sacked_out=7、packets_out=16、prr_delivered=5、prr_out=3、cwnd=9、in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 16-(7+1)+1=9。
No36-No38:与No30-No32处理过程类似。No38后sacked_out=9、packets_out=17、prr_delivered=7、prr_out=4、cwnd=8、in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 17-(9+1)+1=8。
No39-No40:可以看到这里linux收到了两个dup ACK后并没有像上面一样发出新的数据包,那是什么原因呢?我们继续分析一下,server端收到No40后sacked_out=11、 packets_out=17、 prr_delivered=9、 prr_out=4、 newly_acked_sacked=1、 in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 17-(11+1)+1=6。此时delta=ssthresh-in_flight=0,已经不满足之前那种delta<0的cwnd更新情况了,因为No40的ack number并没有确认之前重传的No29数据包,因此更新sndcnt = min(delta, newly_acked_sacked)=0,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(0,0)=0,因此更新cwnd = in_flight + sndcnt=6+0=6。可以看到这个时候,cwnd和in_flight相同,因此受限于拥塞控制,此时不能发出新的数据包了。
No41-No43:client收到No29的重传包的时候,回复了一个ACK,即对应No41,server端在收到No41的时候,发现Ack=201<high_seq=851,因此这个ACK报文被认定为partial ACK。在Recovery状态下,server端收到partial ACK的时候会立即把之前发出的Seq=201的No10报文标记为丢失,并更新retransmit_high=251。此时sacked_out=11、 packets_out=16、 prr_delivered=10、 prr_out=4、 newly_acked_sacked=1、 retrans_out=0、 lost_out=1(虽然No9这个lost的报文被ack number确认了,但是linux又新认定No10报文丢失,因此lost_out仍然为1)、 in_flight = packets_out - ( sacked_out + lost_out) + retrans_out =16-(11+1)+0=4。此时delta=ssthresh-in_flight=6-4=2,此时满足ack number新确认了之前重传的数据且没有RACK重传丢失标记,因此更新 sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1) = min(2,max(10-4,1)+1) =2,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0)) = max(2,0)=2,cwnd = in_flight + sndcnt=4+2=6。因此最终允许发出两个数据包。接着TCP进入快速重传流程,把刚刚标记为丢失的No10报文进行重传,即对应No42,然后更新retrans_out=retrans_out+1=1,prr_out=prr_out+1=5。 继续尝试重传No11报文的时候发现No11报文Seq=251,已经达到了retransmit_high,因此退出重传流程。接着server端尝试发送新的TCP数据,发出一个报文No43报文后,更新packets_out=packets_out+1=17,prr_out=prr_out+1=6 。
No44-No45:server端收到No44这个dup ACK后,更新sacked_out=sacked_out+1=12, prr_delivered=prr_delivered+1=11, in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 17-(12+1)+1=5,delta=ssthresh-in_flight=6-5=1,因此更新sndcnt = min(delta, newly_acked_sacked)=min(1,1)=1, 接着sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0)) = max(1,0)=1, cwnd = in_flight + sndcnt = 6,因此此时拥塞控制允许TCP额外多发送一个数据包。接着server端tcp进入快速重传流程,尝试重传No11报文的时候,发现No11的Seq=251,已经与retransmit_high相同,因此退出快速重传流程,接着tcp尝试发送新数据,最终发出No45数据包。然后更新packets_out=packets_out+1=18,prr_out=prr_out+1=7。
No46-No47:这两个数据包的处理流程与No44-No45一致,因此最终sacked_out=sacked_out+1=13、 prr_delivered=prr_delivered+1=12、 packets_out=packets_out+1=19、prr_out=prr_out+1=8 、cwnd = 6。
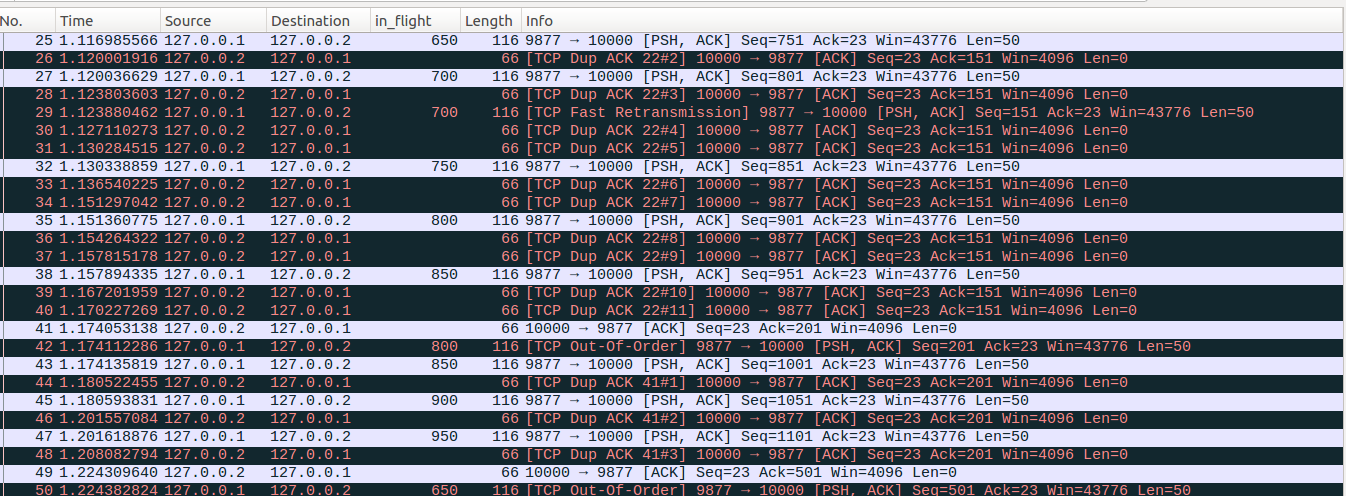
No48:server端在收到No48这个dup ACK后,更新sacked_out=sacked_out+1=14、 prr_delivered=prr_delivered+1=13、 in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 19-(14+1)+1=5,cwnd = 6,此时拥塞窗口允许发送新的数据包,但是可以看到No48之后server端并没有发出新的数据包。原因是server端应用层在write写入数据的时候达到了发送端缓存的上限,因此write操作进入休眠状态,等待收到新的ack number后,释放之前占用的缓存,然后继续写入数据。所以此时虽然server端的拥塞窗口允许发送新的数据,但是目前server端内核中并没有缓存的待发送的TCP新数据了,因此并没有发出新的数据。对于缓存的更新相对比较复杂,不再做精确的数值分析,这里只要宏观了解是缓存受限就行了,在下一篇文章中我们会进一步通过实例验证这个原因。另外从下面后续报文的分析也可以看到server端的应用层在write的时候发生了休眠。
No49-No51:client收到server端的No42重传包后,回复No49这个ACK报文,server端收到No49的时候,high_seq=851,No49的Ack=501<high_seq,因此No49依然是一个partial ACK,server端更新retrans_out = 0,No49的Ack number为501相比之前No48的201多确认了6个数据包,因此更新packets_out = packets_out - 6 =13,但是这六个数据包中起始系列号为201的数据包被标记为lost,因此更新lost_out = lost_out - 1 = 0、接着更新sacked_out = sacked_out - 5 = 9, ,这里在没有打开SACK功能的前提下,sacked_out统计的是dup ACK的个数,表示丢失的数据包后面乱序到达的数据包的个数,是不包含丢失的这个数据包的,一定要理解这块sacked_out更新的背后依据。接着server根据partial ACK把Seq为501(对应No16)的数据包标记为lost,更新lost_out=lost_out+1=1,retransmit_high = 551,。newly_acked_sacked表示收到No49这个数据包之前和之后(packets_out - sacked_out)差值,收到No49之前,(packets_out - sacked_out) = 19-14=5,收到No49更新packets_out和sacked_out后,(packets_out - sacked_out) = 13 - 9 =4,因此newly_acked_sacked = 5-4=1,prr_delivered=prr_delivered+newly_acked_sacked=14、 in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 13 - (9+1) + 0=3,delta = ssthresh - in_flight = 3>0,因为No49的ack number确认了新的数据包且没有RACK重传丢失标记,因此sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1) = min(3,max(14-8)+1)=3,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0)) = max(3,0)=3,最终更新cwnd = in_flight + sndcnt = 3+3=6。可以看到此时允许发出三个数据包,接着server端进入快速重传流程后重传No16数据包,即对应No51数据包,然后更新prr_out =prr_out +1 =9,retrans_out = retrans_out + 1 =1。接着server端的tcp尝试发送新的未发送的数据包,在上面我们说了server端应用层write操作受发送缓存限制进入休眠,目前缓存中没有新的数据包了,因此尝试发送新的数据包失败。但是server端接着发现No49新确认了6个数据包,这6个数据包占用的缓存被释放后,发送缓存中已经有一定量的空闲空间接收应用层write写入的数据了,因此server会唤醒write操作,write操作被唤醒后,写入Seq=1151的数据包,最终发出对应No51数据包。发出No51后,更新packets_out = packets_out+1 =14,prr_out =prr_out +1 = 10。此时in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 14 - (9+1)+1 = 5,而此时cwnd=6,拥塞控制还允许继续发送一个数据包,但是server端在No51后并没有发出新的数据包,原因是write操作被唤醒后,写入50bytes成功后返回到server端应用层,休眠3ms后,应用层才会继续下一次write操作。从这里进一步验证了之前write操作发生了休眠。
No52-No53:可以看到No53和No52两个数据包的时间差大约为3ms,因此明显No53并不是No52这个ACK报文触发的。server端在收到No52的时候,更新sacked_out=sacked_out+1=10、 prr_delivered=prr_delivered+1=15、 in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 14-(10+1)+1=4,delta = ssthresh - in_flight = 2>0,No52的ack number并没有确认新的数据,因此sndcnt = min(delta, newly_acked_sacked) = min(2,1)=1, sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0)) = max(1,0) = 1, 最终cwnd = in_flight + sndcnt = 5,注意此时ssthresh=6,这里在Recovey状态下,cwnd已经降低到ssthresh的下面了。你会在网上看到一些说在Recovery状态下cwnd只会降低到原来的一般,然后就停止减小,可见这个论断不是所有场景都正确的。接着server端进入快速重传流程,但是受到retransmit_high限制而不能进行重传因此退出快速重传,然后server端尝试发送新的未发送的数据包,但是此时server端内核tcp发送缓存还是空的,因此尝试发送新的数据包失败,最终No52处理完毕。接着server端的应用层在休眠3ms后醒来,write写入新的数据包,并以No53发出去。然后应用层write操作返回,继续休眠3ms。此时packets_out = 1 =15,prr_out =1 = 11,in_flight=15-(10+1)+1=5,in_flight正好与cwnd相同。
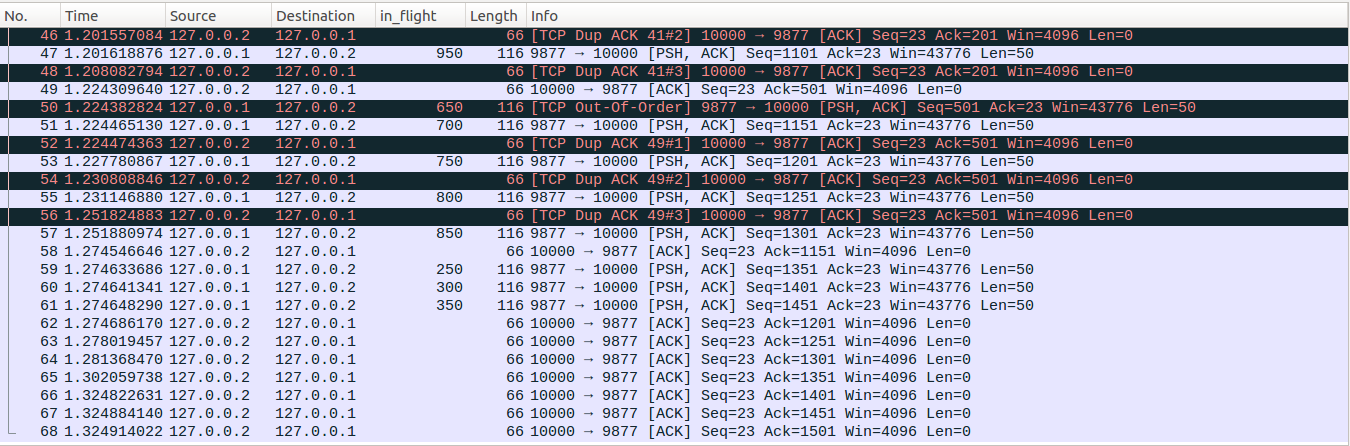
No54-No55:这组数据包与No52-No53类似,不再仔细分析,发出No55后,packets_out=16, sacked_out=11, lost_out=1, retrans_out=1, prr_delivered=16, prr_out=12, in_flight = cwnd =5。
No56-No57:这组数据包的处理与No52-No53略有差异,可以看到No56与No55之间的时间差大约为20ms,server端的应用层在write写入No55后,只剩下4次write操作,write操作的间隔为3ms,因此最终在收到No56这个ack报文之前,server端的应用层已经把全部的1500bytes数据写入完毕了。server端在收到No56这个dup ACK更新完相关的状态变量后,尝试快速重传,但是重传受到retransmit_high限制而退出重传流程,接着尝试发出新的数据包,此时缓存中有四个待发送的数据包,最终发出No57。发出No57后,packets_out=17, sacked_out=12, lost_out=1, retrans_out=1, prr_delivered=17, prr_out=13, in_flight = cwnd =5。
No58-No61:client在收到No50这个重传包的时候,之前No16丢包形成的hole得以修复,回复No58确认包。No58的Ack=1151,相比No56的Ack=501,新确认了13个数据包,因此更新packets_out = packets_out-13=4,sacked_out = sacked_out - 12 =0(这里减12的原因与上面partial ACK相同,新确认的13个数据包里面有个被标记为lost了),lost_out=0,retrans_out=0,此时snd_una=1201, 而此时high_seq=851,snd_una>high_seq,TCP已经越过Recovery point,因此TCP拥塞控制状态更新为Open,重置sacked_out=0(实际上sacked_out已经为0了),更新cwnd=ssthresh=6(Recovery状态切换到Open状态时候cwnd的更新参考下篇文章)。SACK关闭的情况下,Open状态下,sacked_out大于等于dupthreah的时候才会进入快速重传流程,因此这时候server端并不会去尝试快速重传。接着server端进入reno的拥塞避免过程,因为No56的ack number新确认了13个数据包,因此更新cwnd_cnt=13,cwnd_cnt/cwnd向下取整后为2,因此更新cwnd_cnt = cwnd_cnt - 2*6=1,更新cwnd = 6+2=8。接着tcp进入尝试发送新数据的流程,此时显然缓存中的三个数据包都可以发出去了,分别对应No59-No61。这三个数据包发送完后,packets_out=7,sacked_out=0, lost_out=0, retrans_out=0,cwnd = 8。
No62:server端收到No62后,更新packets_out = 6,接着进入reno的拥塞避免过程,但是此时server端的业务处于application-limited状态,因此并不会更新cwnd_cnt。
No63-No68:这些数据包的处理与No62类似,最终packets_out=0,sacked_out=0, lost_out=0, retrans_out=0,cwnd = 8,ssthresh=6, cwnd_cnt=1。
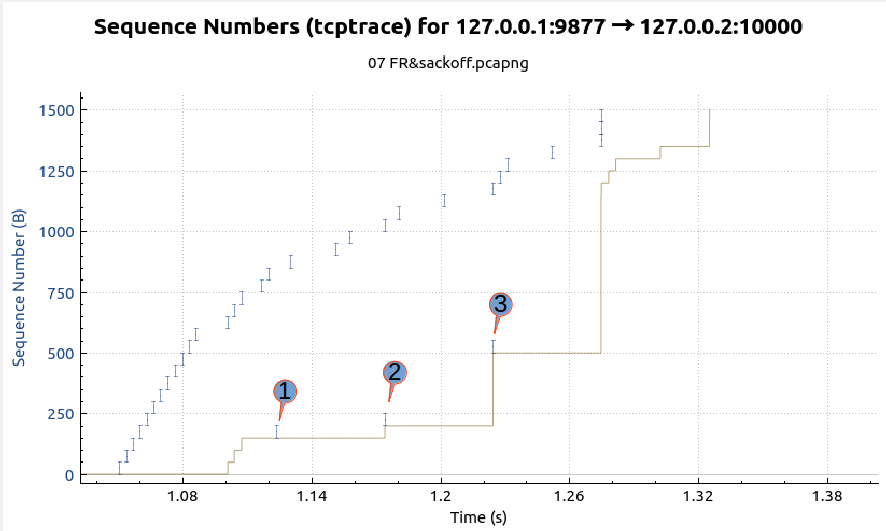
最后给出示例的seq-time图,如下图所示,其中X轴为时间,Y轴为系列号,I字形的蓝色短数线表示server端发出数据包的系列号,下半部的灰色线表示server端收到的Ack number,从下图可以明显的看到server端进行了三次快速重传,下图中标示1、2、3的点分别对应No29、No42、No50三个数据包。
补充说明:
1、server端应用层write写入数据受发送端缓存sndbuf限制而休眠等待释放内存代码点sk_stream_memory_free、 sk_stream_wait_memory、 sk_stream_write_space
2、关闭SACK的情况,sacked_out的更新点tcp_remove_reno_sacks、tcp_add_reno_sack
3、从Recovery恢复为Open状态时刻更新cwnd代码点tcp_try_undo_recovery、tcp_end_cwnd_reduction,上面示例中在tcp_end_cwnd_reduction中更新
4、Recovery状态下,cwnd更新点tcp_cwnd_reduction。
5、因为原始的BSD上的reno版本的TCP没有sack的功能,因此在SACK关闭的情况下,linux认为这是reno版本的TCP:tcp_is_reno。但是我们这里为了避免linux下的reno拥塞控制算法混淆,本篇文章标题称呼为SACK关闭的快速恢复。前文我们介绍过reno的这个词的几个不同意义,一定要注意区分。