一套机器学习的诊断方案
通过前面几章的学习,我们已经掌握了一部分的机器学习的算法,已经可以利用机器学习的知识去解决生活中的一些问题。但是我们作为初学者在利用机器学习的知识解决问题的时候不可避免地会遇到很多的问题,而面对这些问题,我们可能或多或少地能够想到一些解决方案。例如:
1.获取更多的数据用来训练。
2.减少数据中的特征数目。
3.增加数据中的特征数目。
4.增加多项式的项数。
5.减少正则化惩罚项。
6.增大正则化惩罚项。
而面对这些解决方案,我们或许不知道到底该如何选择,就有可能导致我们盲目地选择一个方法然后花了大量的时间和精力最后得到的效果却不尽如意。而这一章的目的就是告诉我们如何高效地从一堆解决方案中选择出我们这个模型最需要的方案,而不是随机选择然后浪费大量时间却收效甚微。
假设评估
在机器学习的过程之中,可能最常见的问题就是高偏差(high bias)和高方差问题(high variance),也就是我们通常所说的欠拟合和过拟合问题。而为了解决这一类问题,以前在特征数量较少的时候可以把假设函数画出来看看是否是有过拟合的问题,但是在通常情况下,假设函数一般是无法可视化的。所以我们需要一个更加有效的方式,那就是要把我们的数据分为训练数据和测试数据(一般是7:3),通过测试数据的准确性来判断是否出现了过拟合或者欠拟合的问题。
模型的选择,训练,验证和测试集
在这里我已多项式拟合为例子。
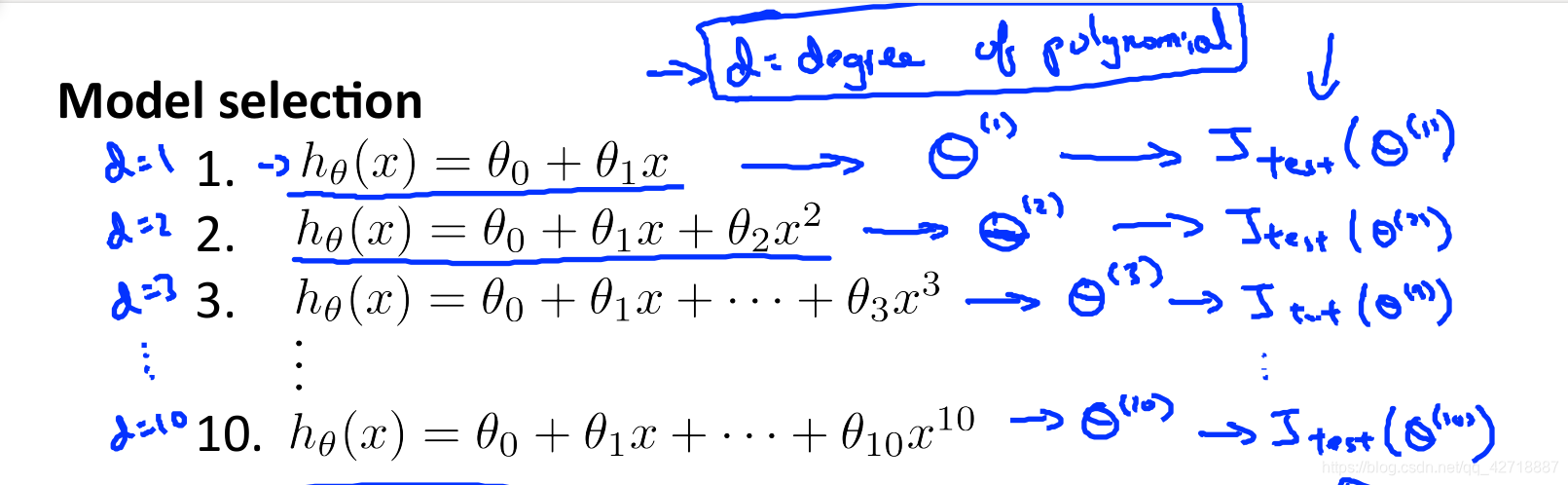 我们把多项式的项数d看做是一个变量,然后再取d=1-10进行训练,最后在测试集上面看不同的d的测试集误差就可以选择最好的d。但是这里同样也会遇到一个问题,如果仅仅是将数据分为训练集和测试集的话就会导致无法科学地评判模型的泛化能力。所以为了解决这个问题,我们最好的方式就是将数据分为训练集,交叉验证集和测试集(比例一般为6:2:2)。在交叉验证集里面测试误差,以评判模型的拟合问题,在测试集上评判模型的泛化能力。
我们把多项式的项数d看做是一个变量,然后再取d=1-10进行训练,最后在测试集上面看不同的d的测试集误差就可以选择最好的d。但是这里同样也会遇到一个问题,如果仅仅是将数据分为训练集和测试集的话就会导致无法科学地评判模型的泛化能力。所以为了解决这个问题,我们最好的方式就是将数据分为训练集,交叉验证集和测试集(比例一般为6:2:2)。在交叉验证集里面测试误差,以评判模型的拟合问题,在测试集上评判模型的泛化能力。
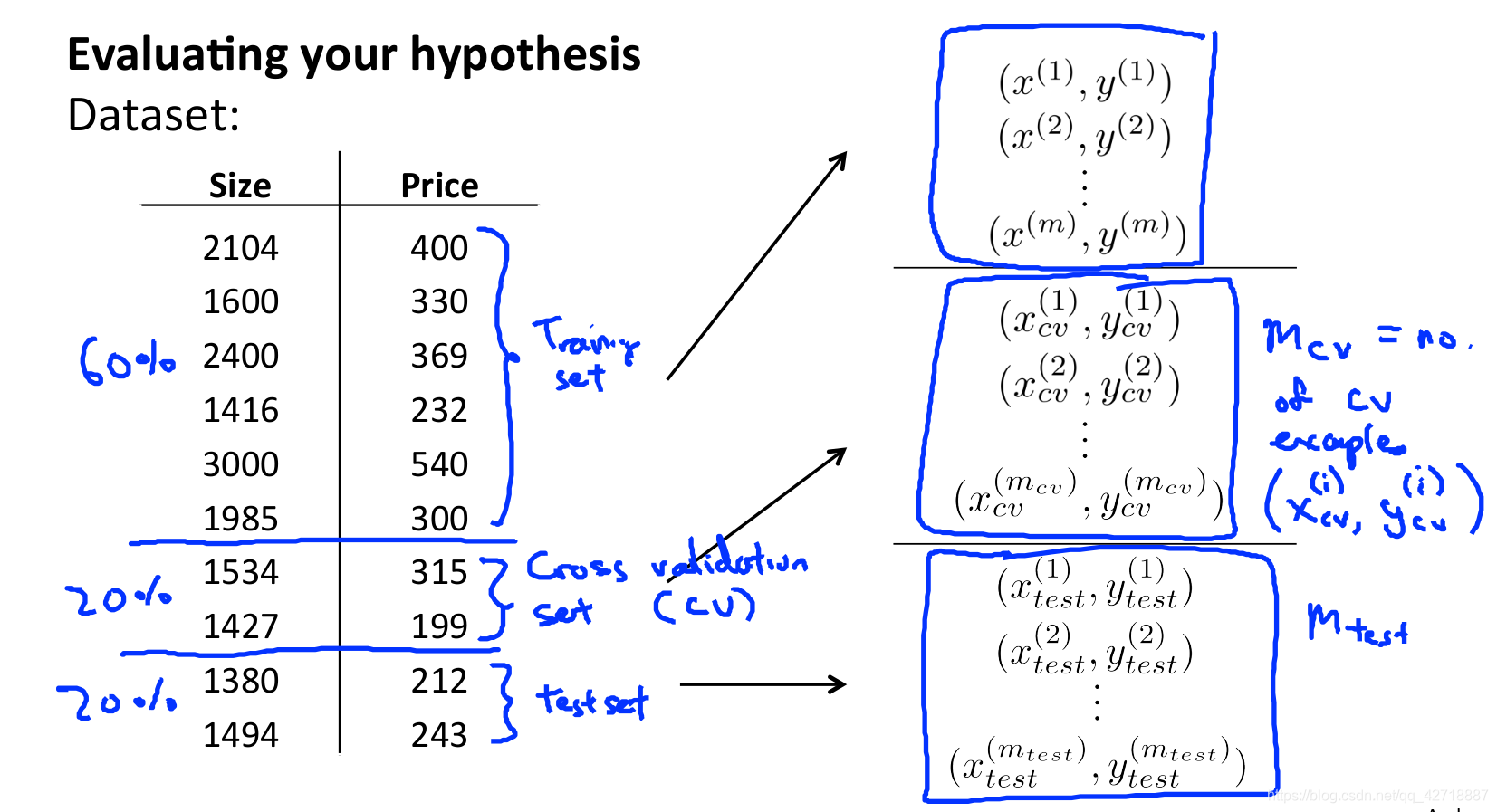 于是最终我们的数据就被分为了这三个部分。即通过交叉验证集的误差来选择模型的d到底为多少最好。而用测试集来评判模型的泛化能力。
于是最终我们的数据就被分为了这三个部分。即通过交叉验证集的误差来选择模型的d到底为多少最好。而用测试集来评判模型的泛化能力。
诊断偏差还是方差
除了用交叉集的误差来大致判断是否有拟合问题,我们还有一个更加直观有效的方式来判断模型是否存在拟合问题。
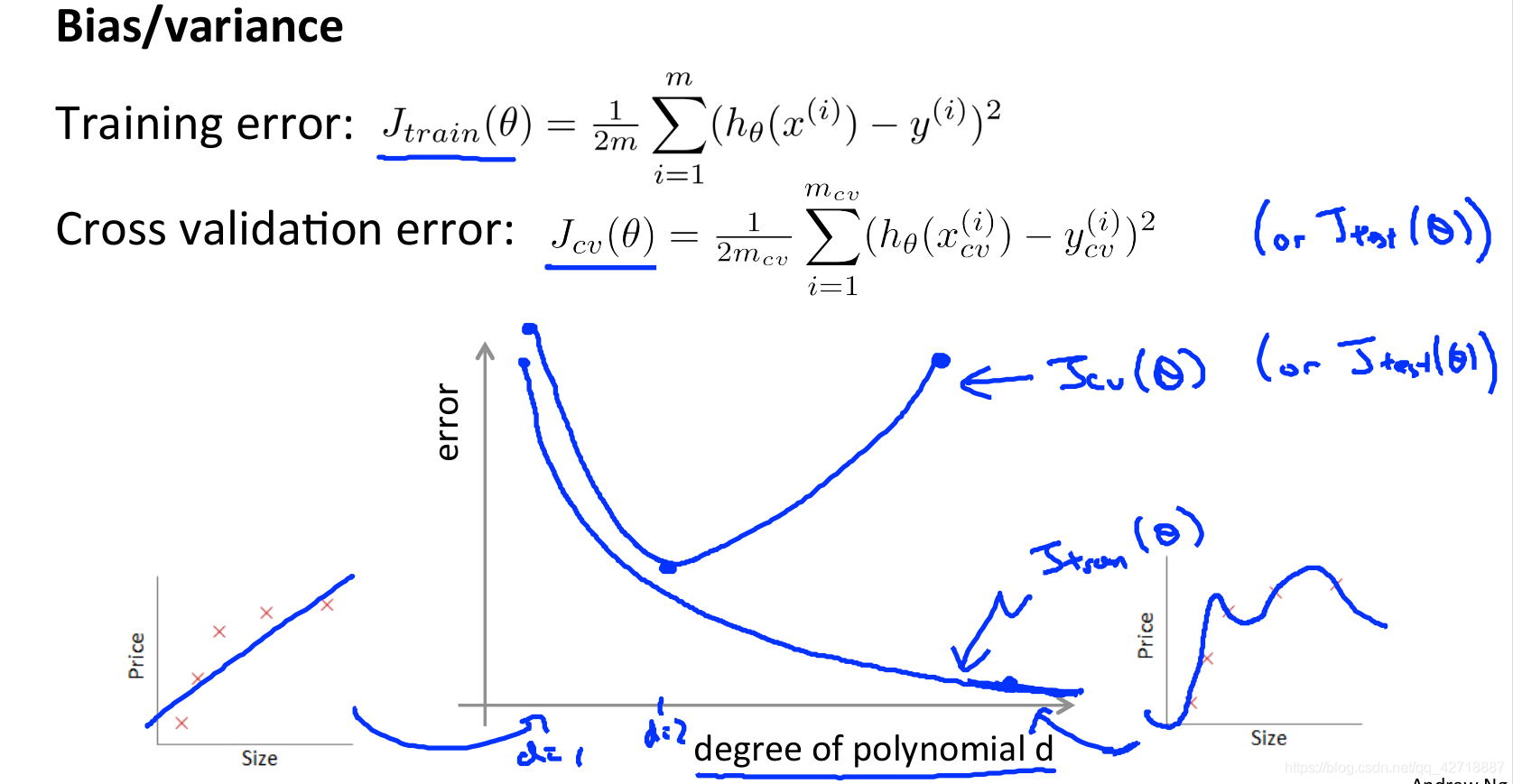 如上图所示,我们可以画出来在不同的d的训练误差和交叉验证集误差。可以看出来,随着d的增大训练误差越来越小,但是交叉验证的误差却是先减后增,很容易就看出来在那个极值点后就发生了过拟合的问题,而开始d较小的时候就是欠拟合了。
如上图所示,我们可以画出来在不同的d的训练误差和交叉验证集误差。可以看出来,随着d的增大训练误差越来越小,但是交叉验证的误差却是先减后增,很容易就看出来在那个极值点后就发生了过拟合的问题,而开始d较小的时候就是欠拟合了。
正则化惩罚项常数的选择
和上面一样,这里的目的就是确定lambda和确定d是一个道理
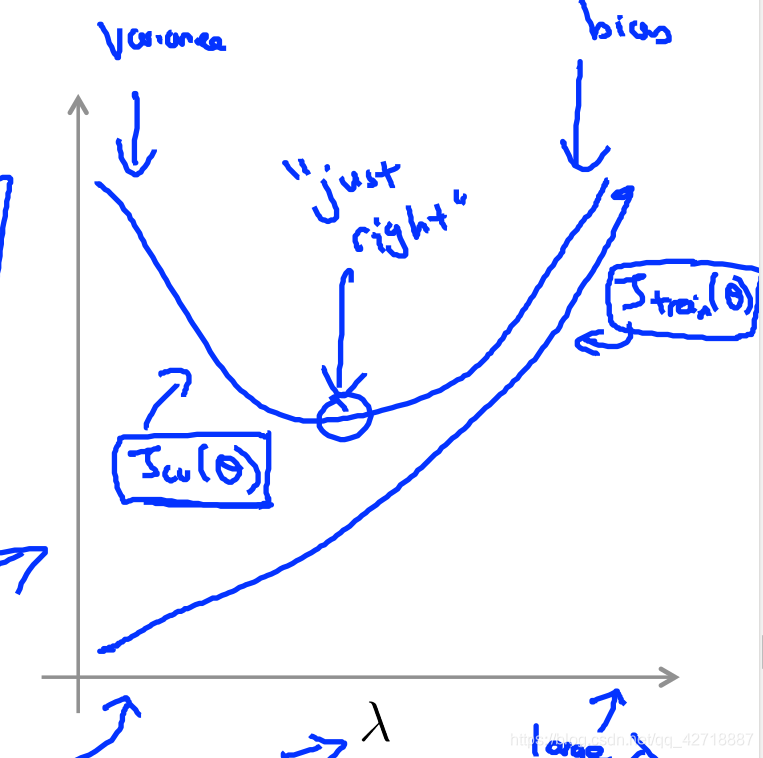 我们还是画出这个图像,就可以轻松确定lambda了。
我们还是画出这个图像,就可以轻松确定lambda了。
学习曲线
这个方法能够帮助我们很快地确定模型到底是出现了高方差还是高偏差问题。
 这是正常的学习曲线图,就是错误关于训练集大小的曲线。
这是正常的学习曲线图,就是错误关于训练集大小的曲线。

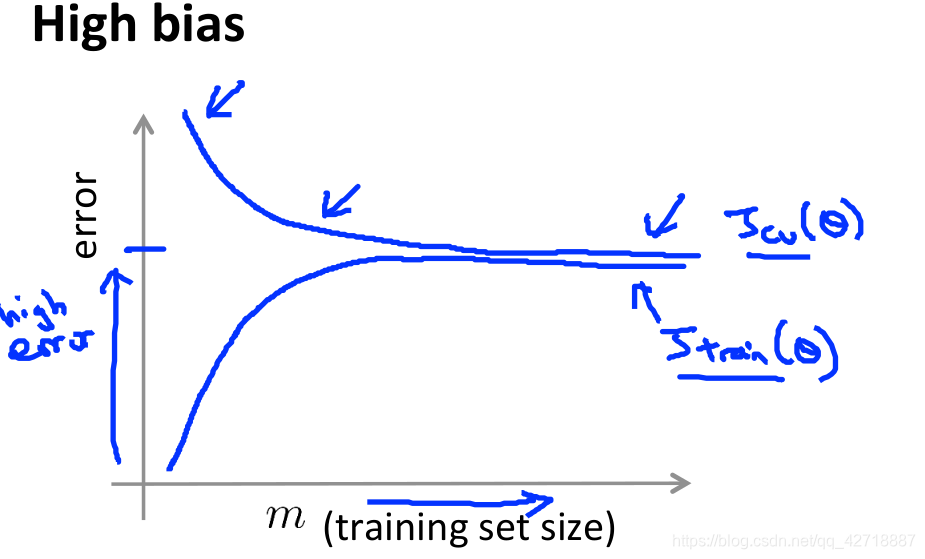 上面两张一个是过拟合一个是欠拟合,我们可以看出过拟合的曲线,到后面的时候两条曲线的间隔还是比较大,这是因为过拟合了交叉验证集下降的速度比较低,需要大量的数据才能解决过拟合的问题。而欠拟合的话,因为模型简单,所以交叉验证集和训练集靠拢的速度较快,并且一直保持着较高的误差值。
上面两张一个是过拟合一个是欠拟合,我们可以看出过拟合的曲线,到后面的时候两条曲线的间隔还是比较大,这是因为过拟合了交叉验证集下降的速度比较低,需要大量的数据才能解决过拟合的问题。而欠拟合的话,因为模型简单,所以交叉验证集和训练集靠拢的速度较快,并且一直保持着较高的误差值。
学习了这些系统诊断模型的方法,我们便可以很快地选择正确的模型,以及参数并且诊断出模型到底是遇到了什么问题。