1.pandas基本函数

2.pandas 描述统计函数
在进行统计描述时,pandas对三个数据对象的轴参数规定如下:
Series: 没有轴参数
DataFrame: “index” (axis=0, default), “columns” (axis=1)
Panel: “items” (axis=0), “major” (axis=1, default), “minor” (axis=2)
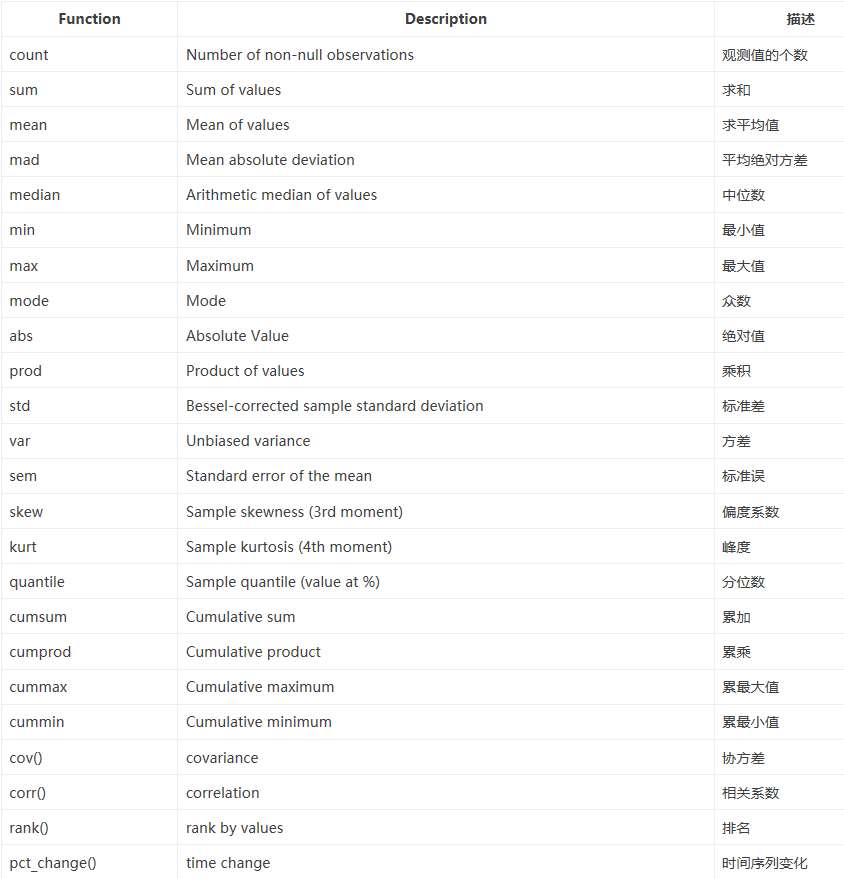
统计描述参数如下:
3.pandas 数据框增、删、改、查、去重、抽样基本操作
pandas的索引函数主要有三种:
loc 标签索引,行和列的名称
iloc 整型索引(绝对位置索引),绝对意义上的几行几列,起始索引为0
ix 是 iloc 和 loc的合体 
(1)行操作
选择某一行

选择多行

条件筛选
普通条件筛选

另外条件筛选还可以集逻辑运算符 | for or, & for and, and ~for not

isin
非索引列使用isin

索引列使用isin

结合any()/all()在多列索引时

where

DataFrame.where() differs from numpy.where()的区别

当series对象使用where()时,则返回一个序列

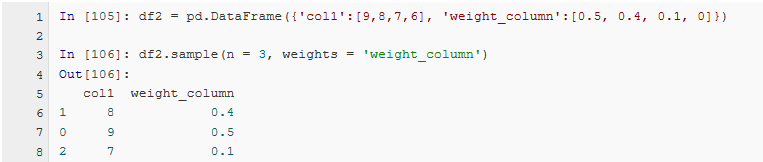
抽样筛选
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
当在有权重筛选时,未赋值的列权重为0,如果权重和不为1,则将会将每个权重除以总和。random_state可以设置抽样的种子(seed)。axis可是设置列随机抽样。
增加行

插入行
pandas里并没有直接指定索引的插入行的方法,所以要自己设置
line = pd.DataFrame({df.columns[0]:"--",df.columns[1]:"--",df.columns[2]:"--"},index=[1])
df = pd.concat([df.loc[:0],line,df.loc[1:]]).reset_index(drop=True)#df.loc[:0]这里不能写成df.loc[0],因为df.loc[0]返回的是series
a b c
0 1.0 a A
1 -- -- --
2 2.0 b B
3 3.0 c C
4 4.0 4 4
交换行
删除行

注意在以时间作为索引的数据框中,索引是以整形的方式来的。
dfl = pd.DataFrame(np.random.randn(5,4), columns=list('ABCD'), index=pd.date_range('20130101',periods=5))
print df1


(2)列操作
选择某一列

选择多列

增加列,如果是已有列,那就是赋值

交换两列的值

删除列
1)直接del DF[‘column-name’]
2)采用drop方法,有下面三种等价的表达式:
DF= DF.drop(‘column_name’, 1);
DF.drop(‘column_name’,axis=1, inplace=True)
DF.drop([DF.columns[[0,1,]]], axis=1,inplace=True)

还有一些其他的功能:
切片df.loc[::,::]
选择随机抽样df.sample()
去重.duplicated()
查询.lookup