摘要:郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
Q学习是一种技术,用于基于对使用非最优策略控制的系统的观察来计算受控马尔可夫链的最优策略。事实证明,它对于具有有限状态和动作空间的模型有效。本文建立了具有通用状态空间和通用动作空间的连续时间模型的Q学习与非线性控制之间的联系。主要贡献概述如下。
- 出发点是观察到Q学习算法中出现的"Q函数"是最小值原则中出现的Hamiltonian的扩展。基于此观察,我们引入了最速下降Q学习算法,以在规定的函数类中获得Hamiltonian的最优近似。
- 基于预解算子的伴随进行最优性公式的变换。这用于构造基于随机近似的一致算法,该算法仅需要对观察进行因果过滤。
- 给出了几个示例来说明这些技术的应用,包括对多智能体系统的分布式控制的应用。
I. INTRODUCTION
A. Background
Q学习和最小值原则有什么关系?Q学习是一种在不了解系统模型的情况下,基于对状态和输入的观察,计算最优策略及其相关价值函数的技术。Pontryagin's最小值原则是Hamilton-Jacobi-Bellman (HJB)方程的精化,该方程描述了最优价值函数。本文认为,非线性控制理论中出现的Hamiltonian与Q学习中感兴趣的Q函数在本质上是相同的。我们发现Q学习和微分动态规划之间也有着密切的联系[10]。通过这种方式,我们在RL和非线性控制研究领域之间架起了一座桥梁。在此过程中,我们介绍了确定性和随机模型的新算法。
在连续时间且通用状态空间的模型中,RL技术全面理论的出现因为几个障碍被放缓。在TD方法的情况下,可以在最近的工作[18]和[16]中找到对连续时间的推广。后者与最近文献[8]中针对扩散模型处理的近似动态规划的线性规划公式密切相关。众所周知,TD学习是收敛的,因为它可以解释为应用于有限维参数空间上凸优化问题的最速下降算法的随机近似实现[17], [3], [1], [12]。
在Q学习的情况下,障碍更为根本。Watkins在他的论文中介绍了这项技术,并在后面的[20]中给出了一个完整的收敛性证明。文献[2]中包含了一个基于相关"流体极限模型"的初步证明。不幸的是,这些结果是脆弱的,严重依赖于有限的状态空间和有限的动作空间。更重要的是,这些收敛证明需要一个完整的参数化,包括所有可能的马尔可夫模型,其状态空间具有给定的基数。这限制了这些方法的适用性,因为复杂性随着状态空间的大小而增加。文献[11]给出了有限维参数化对通用状态空间的一个推广,但收敛结果本质上是局部的。
对于特殊类别的模型,进展更为积极。对于具有二次成本的确定性线性系统(LQR问题),Q学习的一种变体与自适应策略迭代相结合是收敛的——离散时间的分析见[4],连续时间的类似方法见[19]。最近的工作[15]包含了一种专门为一类排队模型设计的参数化Q学习的变体。
在本文中,我们将重新审视该算法。我们提出了一个凸优化问题,它表征了给定类中Q函数的最优近似,并由此得到了在线计算的有效算法。
B. Q-learning and the Minimum Principle
为了简化本文中的讨论,我们将注意力集中在连续时间内的确定性模型上。包含在Sec. III中的是关于如何将本文介绍的概念和算法扩展到更通用的受控马尔可夫过程的讨论。




C. Contributions and overview
本文的贡献总结如下:
- 对Q学习,差分动态编程和最小值原则之间联系的认识使我们能够统一和扩展先前关于确定性非线性系统的自适应控制的结果。
- TD学习的中心思想是构造价值函数的因果表征,以促进因果在线算法的创建。在[12, Ch. 11]中,有人认为,这一步可以看作是在某个希尔伯特空间中伴随算子的应用。此处介绍的算法基于该想法到Q学习的扩展。
- 鉴于这种方法的部分理论支持,在多智能体系统的分布式控制中的应用非常成功(在Sec. IV-C的示例中进行了描述)。这些数值结果为未来的研究提供了许多途径。
在本文的其余部分安排如下。下一节将发展确定性系统的Q学习理论。最后的改进包含在Sec. II-D中,其中引入了Q函数的凸表征。对马尔可夫模型的扩展在Sec. III中讨论,Sec. IV中提供了几个示例,在Sec. V中最后给出了研究的结论和建议。
II. Q-LEARNING FOR DETERMINISTIC MODELS

A. Bellman error



B. A stationary environment for learning





C. Causal smoothing without bias

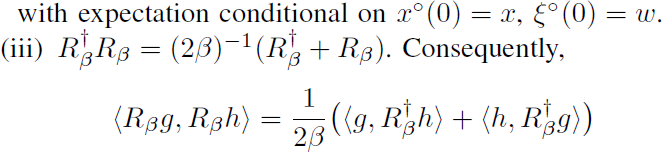


D. A convex characterization of the Q-function



E. Total cost criterion

III. EXTENSIONS TO MARKOV MODELS

A. Causal smoothing fails for Bellman error

B. Galerkin relaxation


IV. EXAMPLES
这里考虑的示例都是(22)的特例,其成本为u的二次方。
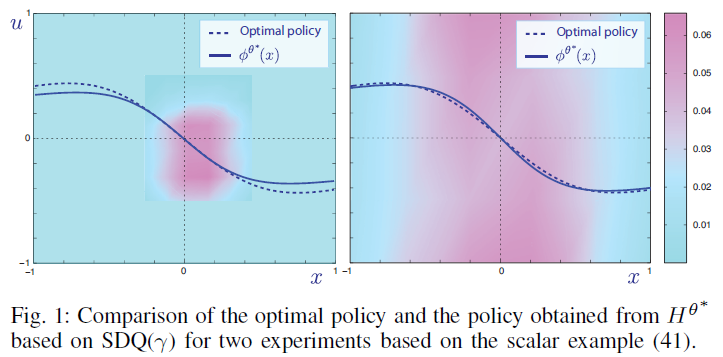
A. Local approximation for a nonlinear system
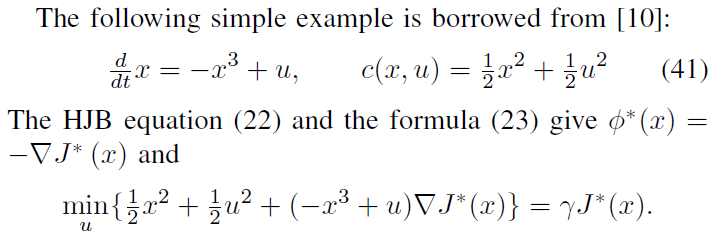

B. Linear systems


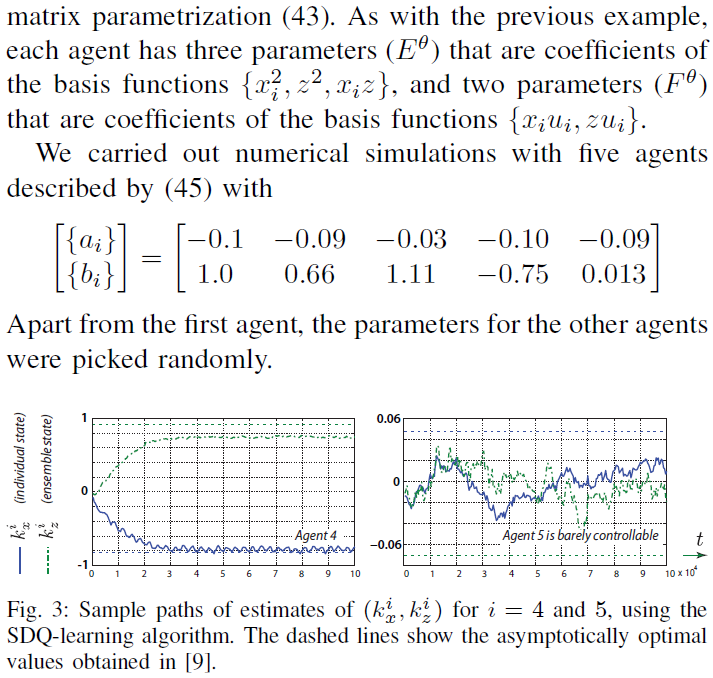
C. Distributed control of multi-agent systems


V. CONCLUSIONS
读者现在可能会问,Watkin的算法是否应该称为H-learning?还是D-Q学习?(回想起Q函数首先出现在Jacobson和Mayne的差分动态编程框架中[10])。我们将此决定留给算法的作者。
我们认为,遵循随机近似理论的标准论证,收敛证明将很简单。但是,有许多途径可供将来研究。我们在这里仅列出一些:
- 该算法可以通过多种方式进行完善。可以像LP方法[6]或TD学习[12]中那样引入状态加权。方差降低技术可用于马尔可夫模型[12]。
- 可以通过选择适当的基础来考虑分布式控制。举例来说,考录到Sec. IV-C中基于具有无限数量智能体的限制模型的结构(另请参见[5], [13], [7], [15], [12])。
- Q学习的有限维度参数化邀请扩展到POMDP模型和确定性模型的输出反馈情况。