1、redis的数据删除与淘汰策略
- 删除数据
redis中的数据是内存级数据库,所有数据都是存放在内存中的,内存中的数据有三种情况:正数(数据在内存中还能存活的时间),-1(永久有效的数据),-2 (已经过期的数据或被删除的数据或未被定义的数据)
在redis中具有时效的数据的存储结构:过期的数据处理在redis的存储空间中存储以外,还开辟了一块独立的存储空间,是具有hash结构,存放的是过期数据的地址值与过期时间,field内存地址(指向的是数据的地址值),value是过期时间,当时间到期后通过地址找到该数据,进行相关操作
删除策略分为3中:
定时删除:创建一个定时器,当key设置过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作
优点:节约内存,到时就删除,快速释放掉不必要的内存占用
缺点:cpu压力大 拿时间获空间
惰性删除:数据到达过期时间,不做处理,等下次访问数据是判断,如果为过期,返回数据,如果过期,删除数据,返回不存在
优点:节约cpu性能,发现必须删除的时候才删除
缺点:内存压力大,出现长期占用内存的数据 拿空间换时间
定期删除:周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度,将16个数据库进行随机抽取,随机抽查数据库中的数据,当删除的过期数据超过抽查量的25%的时候在该数据库继续进行循环,当小于25%时,检查下一个数据库
特点:CPU性能占用设置有峰值,检测频度可自定义设置
内存压力不是很大,长期占用内存的冷数据会被持续清理
周期性抽查存储空间(随机抽查,重点抽查)
- 淘汰策略
淘汰策略针对的是内存不满足新加入数据的最低存储要求,redis要临时删除一些数据为当前指令清除存储空间
注意:逐出数据的工程不是100%能够清理出足够的可使用的内存空间,不成功则反复执行,当对所有数据尝试完完毕,如不能达到内存清理的要求,将出现错误
删除数据的策略 3类8种
第一类:检测易失数据
volatile-lru:挑选最近最少使用的数据淘汰
volatile-lfu:挑选最近使用次数最少的数据淘汰
volatile-ttl:挑选将要过期的数据淘汰
volatile-random:任意选择数据淘汰
第二类:检测全库数据
allkeys-lru:挑选最近最少使用的数据淘汰
allkeLyRs-lfu::挑选最近使用次数最少的数据淘汰
allkeys-random:任意选择数据淘汰,相当于随机
第三类:放弃数据驱逐
no-enviction(驱逐):禁止驱逐数据(redis4.0中默认策略),会引发OOM(Out Of Memory)
3、主从复制
为避免单点redis服务器故障,将数据赋值多个副本保存在不同的服务器上,连接在一起,并保证数据是同步的,实现redis的高可用,同时实现数据冗余备份
多台服务器连接方法
提供数据方:master 主服务器,主节点,主库主客户端
接收数据方:slave 从服务器,从节点,从库,从客户端
主从复制:将master中的数据即时,有效的复制到slave中
主从复制的作用:
读写分离:master负责写(可进行读)slave负责读(不可写)
负载均衡
故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
高可用基石:基于主从赋值,构建哨兵模式与集群,实现redis的高可用方案
- 主从复制工作流程
建立连接阶段(准备阶段)
- 设置master的地址和端口,保证master信息
- 建立socket连接
- 发送ping命令(定时器任务)
- 身份验证
- 发送slave端口信息
数据同步阶段
- 请求同步数据
- 创建rdb同步数据
- 恢复rdb同步数据
- 请求部分同步数据
- 恢复部分同步数据
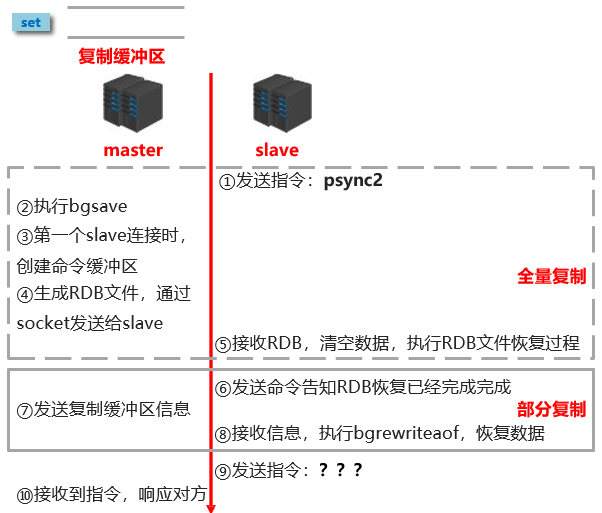
数据同步问题:1、如果数据量巨大,数据同步阶段应该避开流量高峰,避免造成master阻塞,影响正常业务
2、复制缓冲区大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态
3、master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执 行bgsave命令和创建复制缓冲区
命令传播阶段(反复同步)
当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播
命令传播阶段出现以下问题:
网络闪断闪连:忽略
短时间网络中断:部分复制
长时间网络中断:全量复制
部分复制的三个核心要素:
服务器的运行id(run id)
主服务器的复制积压缓冲区
复制缓冲区默认数据存储空间大小是1M,复制缓冲区,又名复制积压缓冲区,是一个先进先出(FIFO)的队列,用于存储服务器执行过的命令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区
作用:用于保存master收到的所有指令(仅影响数据变更的指令,例如set,select)
主从服务器的复制偏移量
描述复制缓冲区中的指令字节位置 master复制偏移量和 slave复制偏移量
作用:同步信息,比对master与slave的差异,当slave断线后,恢复数据使用

心跳机制:进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
周期:默认10s 作用:判断slave是否在线
心跳任务:作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令 作用2:判断master是否在线 当slave多数掉线,或延迟过高时,master为保障数据稳定性,将拒绝所有信息同步
4、哨兵
哨兵作用:
监控:监控master和slave不断的检查master和slave是否正常运行以及master存活检测、master与slave运行情况检测
通知:当被监控的服务器出现问题时,向其他(哨兵间,客户端)发送通知
自动故障转移:断开master与slave连接,选取一个slave作为master,将其他slave连接新的master,并告知客户端新的服务器地址
注意:哨兵也是一台redis服务器,只是不提供数据相关服务,通常哨兵的数量配置为单数