1、有一批路由日志,需要提取MAC地址和时间,删除其他内容。
日志内容格式如下:
Apr 15 10:04:42 hostapd: wlan0: STA 14:7D:C5:9E:84 Apr 15 10:04:43 hostapd: wlan0: STA 14:7D:C5:9E:85 Apr 15 10:04:44 hostapd: wlan0: STA 14:7D:C5:9E:86 Apr 15 10:04:45 hostapd: wlan0: STA 14:7D:C5:9E:87 Apr 15 10:04:46 hostapd: wlan0: STA 14:7D:C5:9E:88 Apr 15 10:04:47 hostapd: wlan0: STA 14:7D:C5:9E:89 Apr 15 10:04:48 hostapd: wlan0: STA 14:7D:C5:9E:14 Apr 15 10:04:49 hostapd: wlan0: STA 14:7D:C5:9E:24 Apr 15 10:04:52 hostapd: wlan0: STA 14:7D:C5:9E:34 Apr 15 10:04:32 hostapd: wlan0: STA 14:7D:C5:9E:44 Apr 15 10:04:22 hostapd: wlan0: STA 14:7D:C5:9E:54
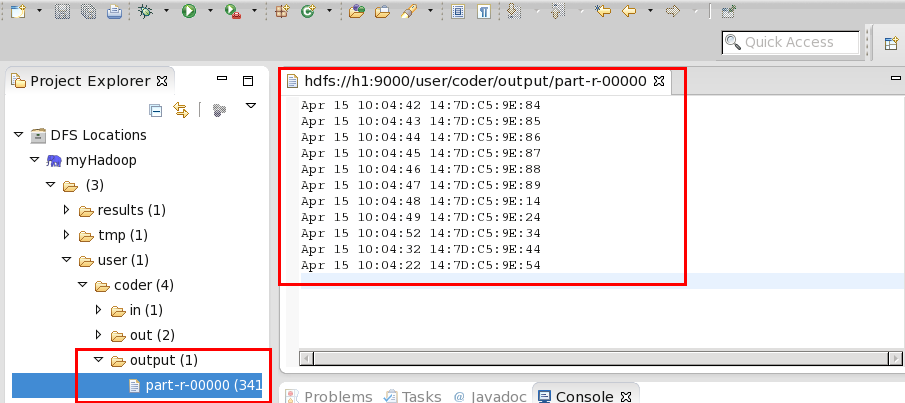
筛选后的内容格式为:
Apr 15 10:04:42 14:7D:C5:9E:84 Apr 15 10:04:43 14:7D:C5:9E:85 Apr 15 10:04:44 14:7D:C5:9E:86 Apr 15 10:04:45 14:7D:C5:9E:87 Apr 15 10:04:46 14:7D:C5:9E:88 Apr 15 10:04:47 14:7D:C5:9E:89 Apr 15 10:04:48 14:7D:C5:9E:14 Apr 15 10:04:49 14:7D:C5:9E:24 Apr 15 10:04:52 14:7D:C5:9E:34 Apr 15 10:04:32 14:7D:C5:9E:44 Apr 15 10:04:22 14:7D:C5:9E:54
2、算法思路
源文件——》Mapper(分割原始数据、输出所需数据、处理异常数据)——》输出到HDFS
3、编写程序
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class App_1 extends Configured implements Tool{ enum Counter{ LINESKIP,//记录出错的行 } /** *Mapper<LongWritable,Text,NullWritable,Text> *LongWritable,Text 是输入数据的key和value 如:路由日志的每一行的首字符的偏移量作为key,整一行的内容作为value *NullWritable,Text 是输出数据的key和value * */ public static class RouterMapper extends Mapper<LongWritable,Text,NullWritable,Text>{ //map(LongWritable key,Text value,Context context) //LongWritable key,Text value,和RouterMapper类的输入数据的key、value对应 //Context 上下文环境 public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{ String line = value.toString(); try{ String[] lineSplit = line.split(" ");//分割原始数据 String month = lineSplit[0];//获取月份 String day = lineSplit[1];//获取日期 String time = lineSplit[2];//获取时间 String mac = lineSplit[6];//获取网卡地址 //转换成hadoop能读取的输出格式,要和RouterMapper类的输出数据格式一致 Text out = new Text(month+" "+day+" "+time+" "+mac); //输出 context.write(NullWritable.get(), out); }catch(ArrayIndexOutOfBoundsException e) { //对异常数据进行处理,出现异常,令计数器+1 context.getCounter(Counter.LINESKIP).increment(1); return; } } } @Override public int run(String[] arg0) throws Exception { Configuration conf = getConf(); Job job = new Job(conf,"App_1");//指定任务名称 job.setJarByClass(App_1.class);//指定Class FileInputFormat.addInputPath(job, new Path(arg0[0]));//输入路径 FileOutputFormat.setOutputPath(job, new Path(arg0[1]));//输出路径 job.setMapperClass(RouterMapper.class);//调用RouterMapper类作为Mapper的任务代码 job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(NullWritable.class);//指定输出的key格式,要和RouterMapper的输出数据格式一致 job.setOutputValueClass(Text.class);//指定输出的value格式,要和RouterMapper的输出数据格式一致 job.waitForCompletion(true); return job.isSuccessful()?0:1; } //测试用的main方法 //main方法运行的时候需要指定输入路径和输出路径 public static void main(String[] args) throws Exception{ int res = ToolRunner.run(new Configuration(), new App_1(), args); System.exit(res); } }
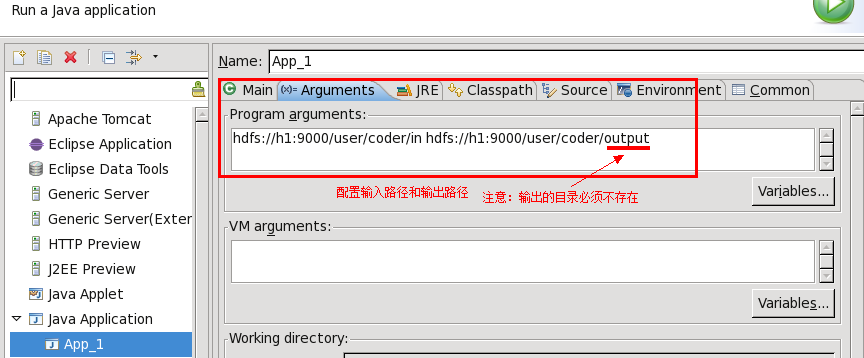
要分析的路由日志文件已上传到HDFS的hdfs://h1:9000/user/coder/in目录中,h1是我的namenode主机名。 运行前配置参数,注意输出路径的存放目录必须不存在。
4、运行结束后,可在eclipse中直接查看结果