desc table_name
show create table
show index from table_name
cardinality列不重复值的个数 预估的值 通过采样的形式
select count(1)from table_name;
5.5 show create table 会触发采样 5.6 关闭掉 analyze table 触发采样
低选择性的不用创建索引 高选择性的创建索引
复合索引
select * from xxx where a=?会使用索引
select * from xxx where a=? and b=?会使用索引
(a,b)复合索引对a和ab排序
select * from xxx where b=?不会用到索引
selet *from xxx where a=? or b=?不会用到
如图1

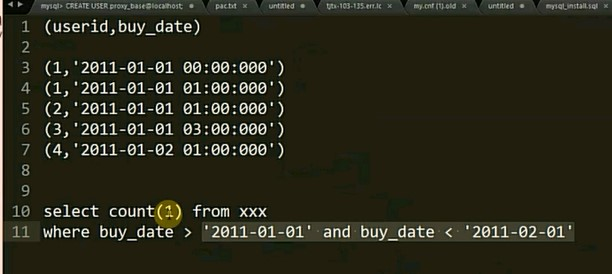
通过执行计划explain
select *from xxx where a=?(a,b,c)\c
select *from xxx where a=?and b=?(a,b,c)\c
select *from xxx where a=?and b=? and c=?(a,b,c)\c
select *from xxx where a=?and c=?(a,b,c)\c
a=?and c=?只有a排序 其他的都是过滤
b c也是不排序的
索引为什么可以快速定位数据,是因为索引是排序的,通过b+树查找是很快的
select * from limit 10;是随机取的10条数据
information_schema.key_column_usage数据字典
1 查看索引carinality存放的元数据表
2 查看线上数据库索引cardinality的值,判断索引创建是否合理,并写出这条sql语句
explain命令
显示sql语句的执行计划
5.6版本支持dml语句
5.6版本开始支持json格式的输出
log_queries_not_using_indexes参数
desc sql语句
show warnings
desc format=json sql语句
