第九章、I/O库函数
一、I/O库函数
定义:I/O库函数是一系列文件操作函数,既方便用户使用,又提高了整体效率。
二、I/O库函数与系统调用
系统调用函数:open()、read()、write()、lseek()、close();
I/O库函数:fopen()、fread()、fwrite()、fseek()、fclose()。
下面说明两者的相同点与不同点:
系统调用

I/O库函数
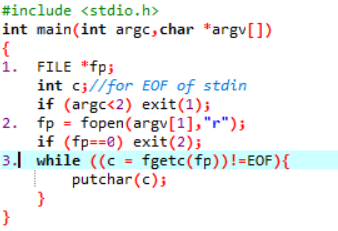
上面显示的是一个使用系统调用的程序,下面显示的是一个使用I/O库函数的类似程序。这两个程序都可将文件内容打印到显示屏上。两个程序看起来很相似,但二者有根本的区别。
第一行:在系统调用程序中,文件描述符fd是一个整数。在库I/O程序中,fp是一个文件流指针。
第二行:系统调用open()打开一个文件进行读取,并返回一个整数文件描述符fd,如果open()失败,则返回-1。I/O库函数fopen()返回一个FILE结构体指针,如果fopen()失败,则返回null。
第三行:系统调用程序使用while循环读取/写入文件内容。在每个迭代中,它发出read()系统调用,将最多4KB的字符读入buf[]。相反,I/O库程序仅仅使用fgetc(fp)从文件流中获取字符,通过putchar()输出字符,直至文件结束符。
三、I/O库函数的算法
1.fread算法
fread算法如下:
(1) 在第一次调用fread()时,FILE结构体的缓冲区是空的,fread()使用保存的文件描述符fd发出一个
n=read(fd,fbuffer,BLKSIZE);
系统调用,用数据块填充内部的fbuf[]。然后,它会初始化fbuf[]的指针、计数器和状态变量,以表明内部缓冲区中有一个数据块。
(2) 在随后的每次fread()调用中,它都尝试满足来自FILE结构体内部缓冲区的调用。当缓冲区变为空时,它就会发出read()系统调用来重新填充内部缓冲区。
- fwrite算法
fwrite()算法与fread()算法相似,只是数据传输方向不同。最开始,FILE结构体的内部缓冲区是空的。
- fclose算法
若文件以写的方式被打开,fclose()会先关闭文件流的局部缓冲区。然后,它会发出一个close(fd)系统调用来关闭FILE结构体中的文件描述符。最后,它会释放FILE结构体,并将FILE指针重置为NULL。
四、I/O库模式
fopen()中的模式参数可以指定为:”r”、”w”、”a”,分别代表读、写、追加
每个模式字符串中可包含一个+号,表示同时读写,或者在写入、追加情况下,如果文件不存在则创建文件。
“r+”:表示读/写,不会截断文件。
“w+”:表示读/写,但是会先截断文件;如果文件不存在,会创建文件。
“a+”:表示通过追加进行读/写;如果文件不存在,会创建文件。
1.字符模式I/0

注意,fgetc()返回的是整数,而不是字符。这是因为它必须在文件结束时返回文件结束符。文件结束符通常是一个整数-1,将它与文件流中的任何字符区别开。
对于fp=stdin或stdout,可能会使用c=getchar();putchar(c);来代替。
2.格式化I/O
格式化输入:(FMT=格式字符串)

格式化输出:

3.内存中的转换函数

注意,sscanf()和sprintf()并非I/O函数,而是内存中的数据转换函数。
- 其他I/O库函数
fseek()、ftell()、rewind():更改文件流中的读/写字节位置。
feof()、ferr()、fileno():测试文件流状态。
fdopen():用文件描述符打开文件流
freopen():以新名称重新打开现有的流
setbuf()、setvbuf():设置缓冲方案
popen():创建管道,复刻子进程来调用sh。
五、文件流缓冲
每个文件流都有一个FILE结构体,其中包含一个内部缓冲区。对文件流进行读写需要遍历FILE结构体的内部缓冲区。文件流可以使用三种缓冲方案中的一种。它们分别是无缓冲、行缓冲、全缓冲
通过fopen()创建文件流之后,在对其执行任何操作之前,用户均可发出一个
setvbuf(FILE *stream,char *buf, int node, int size)
调用来设置缓冲区(buf)、缓冲区大小(size)和缓冲方案(node),它们必须是下一个宏:
_IONBUF:无缓冲
_IOLBUF:行缓冲
_IOFBUF:全缓冲
此外,还有其他的setbuf()函数,是setvbuf()的变体。
六、变参函数
在I/O库函数中,printf()相当独特,因为多种不同类型的可变量参数可以调用它。
七、编程项目:类printf函数
- 项目规范
在Linux中,putchar(char c)可打印一个字符。只使用putchar()来实现函数
int myprintf(char *fmt,...)
用于格式化打印其他参数,其中fmt是格式字符串,包含:
%c:print char
%s:print string
%u:print unsigned integer
%d:print signed integer
%x:print unsigned integer in HEX
问题解决:
基本的文件操作有创建文件、写文件、读文件、重新定位文件、删除文件、截断文件
1.什么是文件?
文件是存储在外部介质上的以文件名标识的数据的集合。存储在磁盘上的文件称为磁盘文件,输出到打印机上就是一个打印机文件。与计算机相连的设备称为设备文件,因此广义地说,任何输入输出设备都是文件。
2.文件的分类:
根据数据性质,文件可分为:程序文件(可由计算机直接执行的程序)和数据文件(用来存放普通的数据,必须由程序来存取和管理)。
根据数据的编码方式,文件可分为:ASCLL文件(可用字处理软件建立和修改)和二进制文件(以二进制方式保存的文件,它不能用字处理软件编辑,占空间较小)。
根据数据的存取方式和结构,文件可分为:顺序访问文件、随机访问文件和二进制文件。
二进制文件转为文本文件的步骤:
(1)先使用iconv命令://IGNORE忽略那些翻译不了的
iconv -f GB2312 -t UTF-8//IGNORE {} -o $filename.text
(2)再使用grep 对 *.text 进行搜索想要查找的ASCII字符
文本文件转二进制文件:
#include <iostream>
#include <fstream>
#include <stdio.h>
#include <stdlib.h>
#include <string>
using namespace std;
#define NSIZE 8 // 每次读取字符数目为8
void main()
{
ifstream ifile;
ofstream ofile;
int i = 0, j = 0, iTemp = 0;
int ibina[NSIZE]; // 存放二进制字节流
char cRead; // 存储读文件流的数据
ifile.open("text.txt", ios::in | ios::binary);
ofile.open("bina.txt");
if (!ifile)
{
cout << "cannot open file/n";
return;
}
while(!ifile.eof())
{
ifile.read(&cRead, 1);
for(i = 1; i <= NSIZE; i++)
{
if((1 << NSIZE - i) & cRead)
{
ibina[i] = 1;
}
else
{
ibina[i] = 0;
}
ofile << ibina[i];
}
}
ifile.close();
ofile.close();
}
代码链接:https://blog.csdn.net/buyicn/article/details/4248045
数据结构以二进制形式在文件中读写:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
typedef struct
{
int Id;
int mathScore;
int chScore;
int enScore;
int aveScore;
char Name[32];
}STU;
int main()
{
STU stuInfo[2];
memset(stuInfo,0x00,sizeof(stuInfo));
int i;
int len = 0;
for(i=0; i<2; i++)
{
printf("Please input one student's id name mathScore chScore enScore ");
scanf("%d%d%d%d%s",&stuInfo[i].Id,&stuInfo[i].mathScore,&stuInfo[i].chScore,&stuInfo[i].enScore,&stuInfo[i].Name);
stuInfo[i].aveScore = (stuInfo[i].mathScore+stuInfo[i].chScore+stuInfo[i].enScore)/3;
}
char *file = "f2.txt";
int fd = open(file,O_CREAT|O_WRONLY|O_APPEND,S_IREAD|S_IWRITE);
for(i=0; i<2; i++)
{
if(len = write(fd,&stuInfo[i],sizeof(stuInfo[i])))
printf("write len = %d ",len);
}
//close(fd);
//fd = open(file,O_CREAT|O_RDONLY,S_IREAD);
len = lseek(fd,0,SEEK_SET);
printf("lseek len = %d ",len);
memset(stuInfo,0x00,sizeof(stuInfo));
for(i=0; i<2; i++)
{
if(len = read(fd,&stuInfo[i],sizeof(stuInfo[i])) < 0)
{
perror("read:");
//printf("error = %s ",error);
}
}
for(i=0; i<2; i++)
{
stuInfo[i].aveScore = (stuInfo[i].mathScore+stuInfo[i].chScore+stuInfo[i].enScore)/3;
printf("%d %s %d %d %d %d ",stuInfo[i].Id,stuInfo[i].Name,stuInfo[i].mathScore,stuInfo[i].chScore,stuInfo[i].enScore,stuInfo[i].aveScore);
}
return 0;
}
代码链接:https://blog.csdn.net/linyimian7539/article/details/74420696
数据结构如何读写?
1.读操作
#include<unistd.h>
int read(int fd,void *buf,int nbytes);
Read()将n个字节从打开的文件描述符读入用户空间中的buf[]。返回值是实际读取的字节数,如果read()失败,会返回-1,例如当fd无效时。注意,buf[]区必须有足够的空间来接收n个字节,并且返回值可能小于n个字节,例如文件小于n个字节,或者文件无更多需要读取的数据。还要注意,返回值是一个整数,而不是文件结束(EOF)符,因为文件中没有文件结束符。文件结束符是I/O库函数在文件流无更多数据时返回的一个特殊整数值(-1)。
2.写操作
#include<unistd.h>
Int write(int fd,void *buf,int nbytes);
write()将n个字节从用户空间中的buf[]写入文件描述符,必须打开该文件描述符进行 写、读写或追加。返回值是实际写入的字节数,通常等于n个字节,如果write()失败,则为-1,例如由于出现无效的fd或打开fd用于只读等。
以下代码段使用open()、read()、Iseek()、write()和close()系统调用。它将文件的第一个1KB字节复制到2048字节。
char buf[1024];
int fd=open("file",O_RDWR); // open file for READ-WRITE
read(fd, buf[ ],1024); // read first 1KB into buf[ ]
lseek(fd, 2048, SEEK_SET); // lseek to byte 2048
write(fd, buf,1024); // write 1024 bytes
close(fd); // close fd