zoukankan
html css js c++ java
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 344: invalid start byte报错解决方案
一、问题描述
使用python爬虫爬取某网页的内容时,代码中因为这行代码报错:cont = rep.read().decode()
二、出现原因
你请求获取到的内容不是utf-8编码,如果是utf-8编码可以在decode()中不写,默认utf-8
三、解决方案
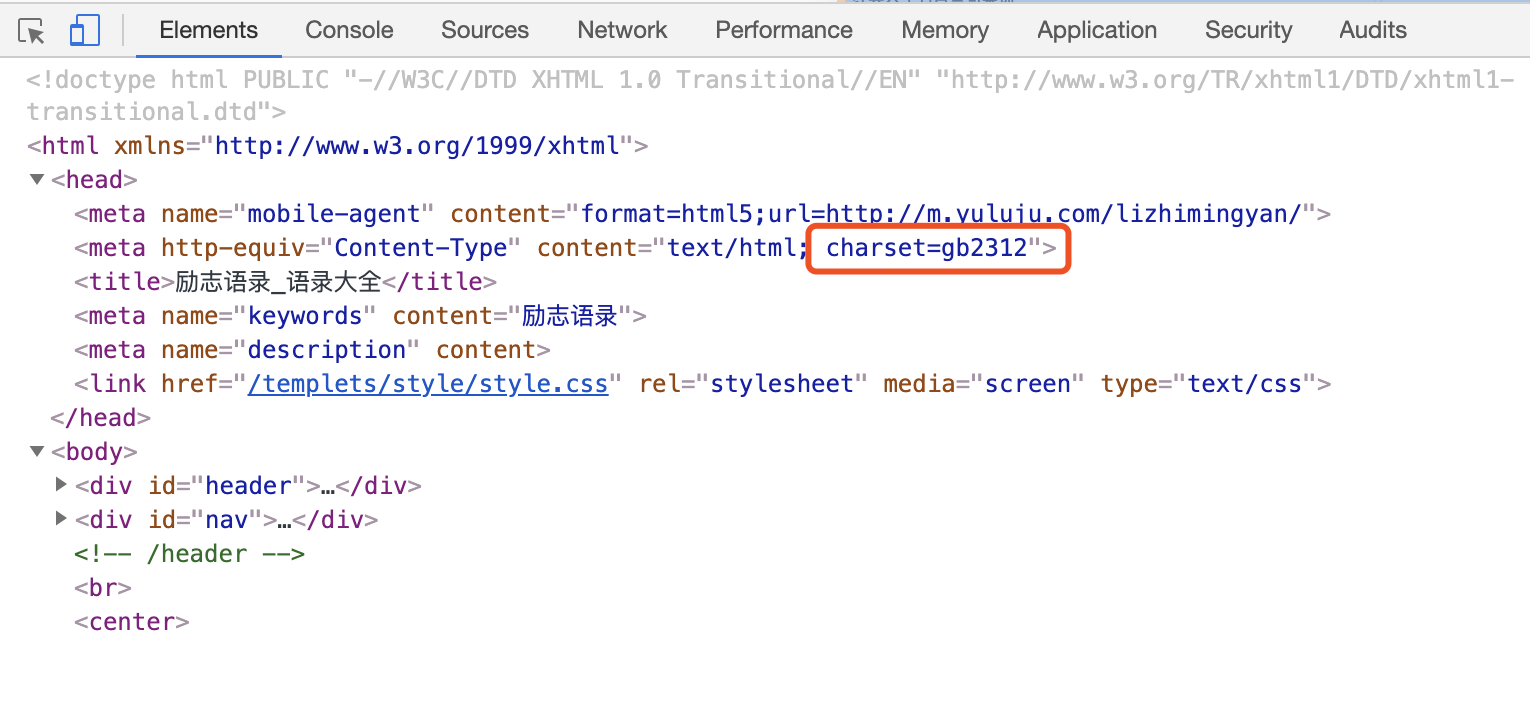
1、首先查看你要爬取网页的内容的编码格式,如下图
2、如果非utf-8编码,就需要在decode()函数中标明,比如我应该写为:cont = rep.read().decode('gb2312'),问题解决。
查看全文
相关阅读:
C#常用功能和通用模块开发资料
常用工具&网址
Web前端开发、常见问题及解决方法
MQTT专题(Spring boot + maven整合MQTT、EMQ搭建MQTT服务器和客户端模拟工具)
Spring常用注解
ActiveMQ专题(服务器搭建、配置和项目应用)
HTTP RESTful服务开发 spring boot+Maven +Swagger
设计模式-命令模式
设计模式-责任链模式
设计模式—建造者模式(Builder)
原文地址:https://www.cnblogs.com/lxmtx/p/12651922.html
最新文章
Qt 地址薄 (一) 界面设计
<The Art of Readable Code> 笔记二 (上)
<The Art of Readable Code> 笔记一
Verilog 基础回顾 (一)
Qt 之 数字钟
Qt 之 饼图
Qt 之 入门例程
C++ 之 基础回顾(一)
Spring——AOP原理及源码四【系列完】
Spring——AOP原理及源码三【系列完】
热门文章
Spring——AOP原理及源码二【系列完】
Spring——AOP原理及源码一【系列完】
Spring——自动装配(@Autowired/@Profile/底层组件)
Spring——管理Bean的生命周期
Spring——组件注册方法总结
Flink安装及实例演示
旅行商问题分析(分支限界法)
Java常用功能开发资料
基于RabbitMQ的Rpc框架
【转】C#异步转同步
Copyright © 2011-2022 走看看