最近发现一个网站www.unsplash.com ( 没有广告费哈,纯粹觉得不错 ),网页做得很美观,上面也都是一些免费的摄影照片,觉得很好看,就决定利用蹩脚的技能写个爬虫下载图片。
先随意感受一下这个网站:
接下来开始对网页进行解析:
在该网页检查元素,选择其中一张图片查看它的代码
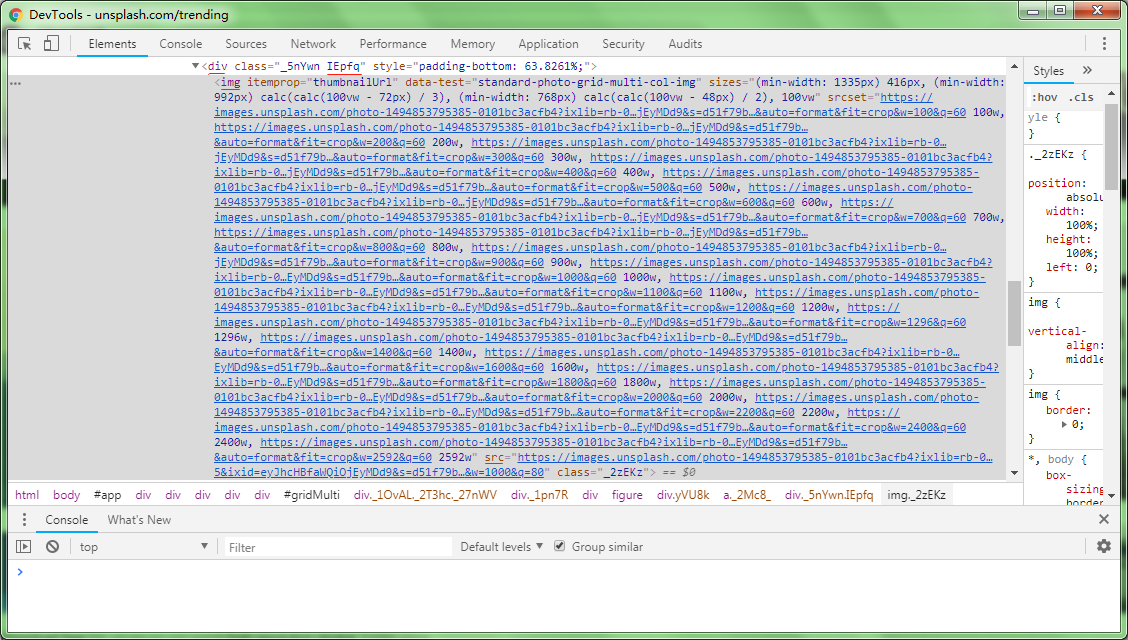
可以看到,图片 img 在一个 div 的 tag 里面,而且 class = ”IEpfq“,不过那么多内容,虽然有点乱,但其实看 src = ” “ 就行了。
但这只是一张图片的内容,得再看看其他的图片是不是一样。检查一下发现都是这样。这样子就算解析完成了。可以开始写代码了
1 #!/usr/bin/env python 2 # _*_ coding utf-8 _*_ 3 from bs4 import BeautifulSoup 4 import requests 5 6 i = 0 7 url = 'https://unsplash.com/' 8 html = requests.get(url) 9 soup = BeautifulSoup(html.text, 'lxml') 10 11 img_class = soup.find_all('div', {"class": "IEpfq"}) # 找到div里面有class = "IEpfq"的内容 12 13 for img_list in img_class: 14 imgs = img_list.find_all('img') # 接着往下找到 img 标签 15 for img in imgs: 16 src = img['src'] # 以"src"为 key,找到 value 17 r = requests.get(src, stream=True) 18 image_name = 'unsplash_' + str(i) + '.jpg' # 图片命名 19 i += 1 20 with open('./img/%s' % image_name, 'wb') as file: # 打开文件 21 for chunk in r.iter_content(chunk_size=1024): # 以chunk_size = 1024的长度进行遍历 22 file.write(chunk) 23 print('Saved %s' % image_name)
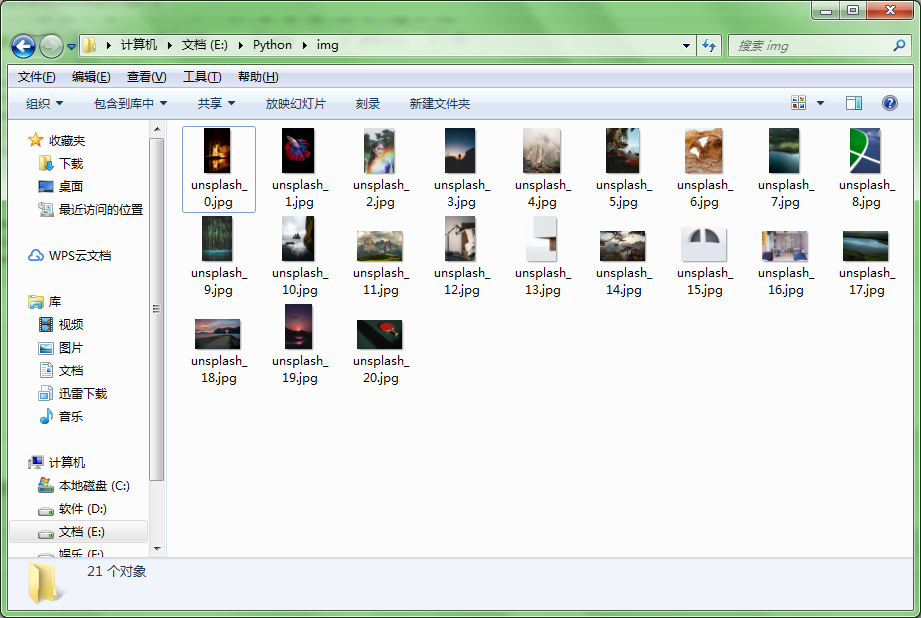
运行结果:
Saved unsplash_0.jpg
Saved unsplash_1.jpg
......
Saved unsplash_19.jpg
Saved unsplash_20.jpg