1)spark通常把shuffle操作定义为划分stage的边界,其实stage的边界有两种:ShuffleMapTask和ResultTask。ResultTask就是输出结果,输出结果的称为ResultTask,都为引起stage的划分,比如以下代码:
rdd.parallize(1 to 10).foreach(println)
每个stage内部,一定有一个ShuffleMapTask或者是ResultTask,因为这两者是划分stage的依据,是stage之间的边界。一个stage中的所有task最后会以taskSet的形式提交给TaskScheduler去执行,Spark实现了三种不同的TaskScheduler,包括LocalSheduler、ClusterScheduler和MesosScheduler。
2)actions(动作)会生成一个job,触发job的提交,所以我们从客户端提交的一个作业可能会被划分为多个job。但是,如果一个action后没有其他操作,也就是这个action是最后一个操作的话,这个action就独立为一个stage,而非提交一个job。(参考0)
3)task分为ShuffleMapTask和ResultTask(参考1)。
4)广播变量应该广播RDD对应的值,也就是广播RDD.collect()而不是RDD本身,可以使用spark-shell测试。(参考2)
5)使用mapPartitions以分区为单位处理RDD时,定义的函数返回值必须是Iterator类型,同样的,mapPartitionsWithIndex,也必须返回Iterator类型。mapPartitions(iter:Iterator[])有一个Iterator类型的参数,使用以下方式使用mapPartitions:
1 val rdd1=.... 2 val rdd2=rdd1.mapPartitions(processPartitions)//如果我们定义的函数除了Iterator之外,没有别的参数,就可以以这种方式来使用mapPartitions 3 4 val rdd3=rdd1.mapPartitions((x,y)=>processPartitions2(x,y))//其中x是Iterator类型,y是broad 5 6 //定义processPartitions 7 .mapPartitions只有一个Iterator参数,所以我们自定义的函数也必须包含这个参数 8 def processPartitions(iter:Iterator[Int]){//假设分区中每个元素类型是Int 9 ... 10 11 } 12 13 def processPartitions2(iter:Iterator[Int],broad:Array[Double]){//假设分区中每个元素类型是Int 14 ... 15 16 }
mapPartitionsIndex的使用与mapPartitions类似,只是mapPartitionsIndex(Idx:Int,iter:Iterator[U])多了一个参数Idx,Idx就是分区的编号。参考3
6)使用rdd1.zipPartitions(rdd2)(substractTwoPatitionsValue),在iter.hasNext之前,不能使用调用iter变量做任何的操作,这会导致iter变为空,等到使用iter.hasNext时取不到值,错误代码如下:
def substractTwoPatitionsValue(iter1:Iterator[(Int,Array[Double])],iter2:Iterator[(Int,Array[Double])]): Iterator[(Int,Array[Double])] ={ val matRows=iter1.length//这里在hasNext之前使用Iter1,可以得到正确值 println("matRows:"+matRows)//522 println("iter1 length:"+iter1.length)//第二次使用iter就不能取到值了,结果是0 //println("iter2 length:"+iter2.length) val resMatrixColumns=21025//21025 val u=Array.ofDim[Double](matRows,resMatrixColumns) val keyIndexArray=new Array[Int](matRows)//分区中的key值 var keyCounter=(-1) //var keyIndex=0 var Value=new Array[Double](resMatrixColumns) var cur:(Int,Array[Double])=(0,new Array[Double](resMatrixColumns)) println("before iter1") while(iter1.hasNext){ keyCounter+=1 println("in iter1") cur=iter1.next() keyIndexArray(keyCounter)=cur._1//这里每个分区里的key/value是按照key逆序排列 Value=cur._2 for(k<-0 until resMatrixColumns){//right matrix cols u(keyCounter)(k)=Value(k)//将顺序读取到的分区里的值,存储到u中 } //println(cur._2(1)) } /************************以上就完成了读取第1个rdd中1个分区的数据的任务*************************************************************/ /************************接下来读取第2个rdd中1个分区的数据,并根据key和第1个rdd中分区值相加************************************************************/ //var cc:(Int,Array[Double])=(0,new Array[Double](resMatrixColumns)) var keyIndex=0 var positionInMatrixu=0 println("before iter2") while(iter2.hasNext){ println("in iter2") cur=iter2.next() keyIndex=cur._1 Value=cur._2 positionInMatrixu=keyIndexArray.indexOf(keyIndex)//存储数据时,keyIndexArray和u的索引值通过keyCounter一样对应 for(k<-0 until resMatrixColumns){//right matrix cols u(positionInMatrixu)(k)-=Value(k)//完成两个分区值的相加 } } val newIter=keyIndexArray.zip(u).iterator //结果是有序的,不像SRdd中key是无序的 newIter /* 使用以上方式产生迭代子 keyCounter=(-1) val newIter=u.map(x=>{ keyCounter+=1 //println("keyIndex:"+keyIndex) (keyIndexArray(keyCounter),x)}).toIterator newIter */ }
也就是说,在zipPartitions里,各个RDD的迭代子iter1以下面这种形式使用,并且只能使用一次:
while(iter1.hasNext){ ..... }
7)运行spark作业的时候有时候会出现“Task deserialization Time”过长的问题,如下所示:
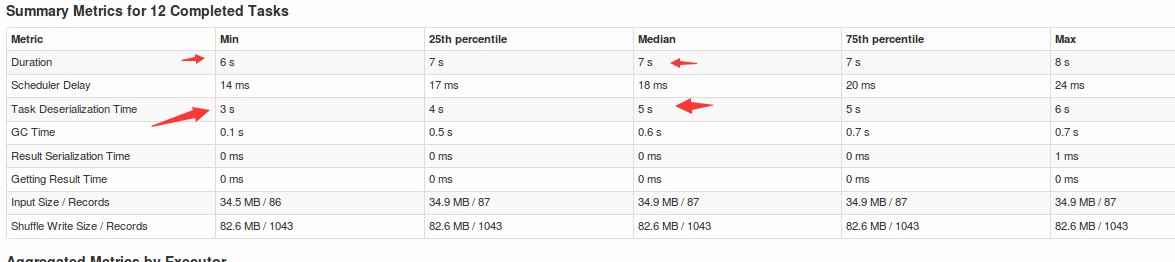
也就是“任务反序列化时间”过长,原因是调用rdd的转换操作时,使用了“外部变量”(driver中的一个数组),解决方法是使用“广播变量”将此“外部变量”进行广播。
8)同步、异步、阻塞、非阻赛:参考