awk 【单独的编程语言解释器】
1、awk介绍
全称:Aho Weinberger Kernaighan 三个人的首字母缩写;
1、awk介绍
全称:Aho Weinberger Kernaighan 三个人的首字母缩写;
1970年第一次出现在Unix机器上,后来在开源领域使用它;
所以,我们在Linux中使用,改名为GNU awk;所以,在Linux上实际上叫做gawk;
所以,我们在Linux中使用,改名为GNU awk;所以,在Linux上实际上叫做gawk;
grep 行过滤器
-o -i -v -E grep egrep fgrep【写什么就匹配什么】
sed 行编辑器
-n p 1、地址定界 3,5,/pat/【e】 2、命令 p a i w c s/pat/str/g|1|2..|&
${var/pat/str} ${var//pat/str}
【默认情况下,三个工具都不去编辑源文件】
-o -i -v -E grep egrep fgrep【写什么就匹配什么】
sed 行编辑器
-n p 1、地址定界 3,5,/pat/【e】 2、命令 p a i w c s/pat/str/g|1|2..|&
${var/pat/str} ${var//pat/str}
${test}、${#test}、${test:offset:length}、${test#*word}、${test##*word}、${test%word}、${test%%*word}、${test/pattern/string}、${test//pattern/string}、${test:-word}
awk 报告生成器
通过模式匹配以及自己本身的语言格式,来获取、并输出客户所需要的内容;【默认情况下,三个工具都不去编辑源文件】
示例:获取系统上面用户id大于等于1小于等于500的用户的用户名和用户ID
# awk最后实现这个功能的时候只需要一句话就可以!
for i in $(cut -d: -f3 /etc/passwd);do if [ $i -ge 1 -a $i -le 500 ];then echo grep $i | cut -d: -f1,3 fi done
awk -F: '{if($3>=1&&$3<=500){print $3}}' /etc/passwd
格式化输出的意义:
awk -F: -v OFS=":" 'BEGIN{printf " username uid
========================
"}{if($3>=1&&$3<=500){printf "用户名:%-10s UID:%-10d
",$1,$3}}END{printf "---------------------------
end
"}' /etc/passwd
2、awk工作原理
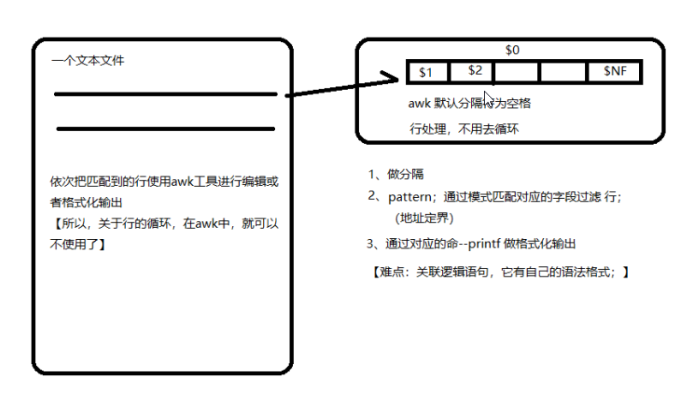
3、awk的用法
awk [option] ... 'program' FILE ...
1、program 必须使用 !单引号!
2、多条program语句使用大括号包含起来,可以并列,可以嵌套 awk '{print}' /etc/passwd
4、awk的常见option
-F 指定分隔符
手动指定变量参数
2、在awk中调用调用变量 不用加 $ 符号
-F 指定分隔符
awk -F[/:] '{print $1,$3}' a.txt
其中 [ ] 内表示多个字符中的任意一个
-v 因为awk是一种语言编译器,能自己定义变量,同时也有内置变量(与环境变量类似)手动指定变量参数
awk -v a="a/b" '{print a}' a.txt
给a赋值,打印a这个变量
1、a是自定义变量 -v FS=":"2、在awk中调用调用变量 不用加 $ 符号
awk '{a="a/b";print a}' a.txt
扩展:了解 cut 与 awk 的区别;
5、awk的语法格式 -- program
1、print
默认输出(在屏幕上)
在awk中没有保存命令,我们可以关联别的命令来保存awk的结果;
【仅仅只有顺序关系】
3、变量(内置变量、自定义变量)
内置变量 -- 环境变量(bash)(env、set -C +C)
awk语言所默认支持的变量
FS 定义输入分隔符的变量
OFS 定义输出分隔符的变量
NF 定义行分隔以后的参数个数 ($NF 分隔以后最后的一列变量)
*变量引用的时候,不用加$,$0,$1...$n
在后面'program'中去调用自定义变量时,直接使用即可
或者将 “变量=值”语句直接写在'program'亦可;
1、print
默认输出(在屏幕上)
在awk中没有保存命令,我们可以关联别的命令来保存awk的结果;
awk '{a="a/b";print a}' a.txt | tee a.bak
2、printf -- 实现格式化输出
printf "%s是%d班学的最好的学生",变量1,变量2
格式符 %s 字符串 %d %i 数值 %e %E 科学计算数值 %c ACSii码值 %f 浮点数 %u 无符号整数 %% 逃逸符 只显示 % 自己 修饰符 默认为右对齐 - 代表左对齐 %5.4f 5 所占位数 4 所取小数位
awk '/^UUID/{printf "被挂载文件:%-50s 挂载点:%-10s 文件系统格式:%-10s
",$1,$2,$3}' /etc/fstab
注意:这里提到了地址定界
sed /PAT1/,/PAT2/3、变量(内置变量、自定义变量)
内置变量 -- 环境变量(bash)(env、set -C +C)
awk语言所默认支持的变量
FS 定义输入分隔符的变量
OFS 定义输出分隔符的变量
NF 定义行分隔以后的参数个数 ($NF 分隔以后最后的一列变量)
*变量引用的时候,不用加$,$0,$1...$n
awk -v FS=":" '//bash$/{print $1,$NF}' /etc/passwd
NR 定义文件的行数,定义多个文件的文件的,行号叠加
FNR 文件只计算自己的行号 awk '{print NR}' /etc/fstab /etc/passwd
awk '{print FNR}' /etc/fstab /etc/passwd
FILENAME 存储文件的名字
awk '{print FILENAME}' /etc/passwd //把文件名打印N次,N文件的行数
awk 'BEGIN{print FILENAME}' /etc/passwd //BEGIN{语句} 只在行循环开始时,执行一次;
ARGC 整个命令的 段数 【注意:不包含 'program' 本身】
ARGV 数组,用来调取命令中,指定的段 ARGV[2] 【注意:数组中也不包含 'program' 】 awk 'BEGIN{print ARGC}' /etc/passwd /etc/fstab /etc/shadow
awk 'BEGIN{print ARGV[3]}' /etc/passwd /etc/fstab /etc/shadow
RS 指定换行符 可以指定新的换行符,不影响本身的换行
ORS 输出的时候指定的换行符,将默认换行符替换为指定字符 awk -v RS=" " '{print}' /etc/passwd
awk -v ORS=" " '{print}' /etc/passwd //可以用来取消换行
自定义变量
-v 变量=值在后面'program'中去调用自定义变量时,直接使用即可
或者将 “变量=值”语句直接写在'program'亦可;
awk -v a="a/b" '{print a}' a.txt
awk '{a="a/b";print a}' a.txt
4、模式匹配(地址定界)
1、空值,没有定义,默认就将文件中所有的行,放入awk进行循环
2、对固定的 1,3 行进行操作
2、对固定的 1,3 行进行操作
sed -n '1,3p' /etc/passwd
awk '1,3{print}' /etc/passwd //awk默认不支持使用 1-3 1,3 等等,这样数值的直接写法;
awk 'NR>=1&&NR<=3{print}' /etc/passwd //通过NR变量来指定
3、/pat1/
sed -n /pat1/p /etc/passwd
awk '/r..ter/{print}' /etc/passwd
4、/pat1/,/pat2/ 第一次匹配pat1到第一次匹配pat2,之间的行
练习:判断/^r..ter/,/^user.*>/之间的行的用户,是bash的用户,并显示用户的用户名,和UID ========================================
?shell:
for i in `awk '/^r..ter/,/^user.*>/{print $NF}' /etc/passwd`;do
if [[ $i == "/bin/bash" ]];then
echo ``
fi
done
while line;do
if [[ "/bin/bash" == `awk -F: '{print $NF}' $line` ]];then
awk -F '{print $1,$3}' $line
fi
done << `sed -n '/^r..ter/,/^user.*>/p' /etc/passwd`
========================================
awk -F: '/^r..ter/,/^user.*>/{if($NF==/bin/bash);print $1,$3}' /etc/passwd
5、模式匹配可以直接使用判断语句
awk -F: '$NF=="/bin/bash"{print $1,$3}' /etc/passwd
6、BIGEIN|END语句
BIGEIN定义在默认循环进行操作前所要执行的语句; awk -F: 'BEGIN{printf "shell程序为bash的用户为:
"}$NF=="/bin/bash"{print $1,$3}' /etc/passwd
awk -F: 'BEGIN{printf "shell程序为bash的用户为:
"}$NF=="/bin/bash"{print $1,$3}END{printf "end
"}' /etc/passwd
一般在格式化输出的时候,打印表头和表未;
5、操作符
运算操作符:
+ - * / %(取余、取模) ^ //(取整)
比较运算符:
== != > < >= <=
~ !~
awk -F: '$NF~"/bin/bash"{print $1,$3}' /etc/passwd
awk -F: '$NF!~"/bin/bash"{print $1,$3}' /etc/passwd
逻辑操作符:
&&
||
!
赋值操作符:
= += -= /= *= %= ^= //=
条件表达式:
条件语句?条件成立语句:条件不成立的语句
awk '/^title/{FN<=2? print: printf "参数过
"}' /boot/grub/grub.conf //有点问题
6、常见action
print printf 以及 它任何命令的操作都是 action;
1、expressions 常见表达式
2、control statement 控制语句 例如: if while等
逻辑关系语句判断来进行结合
3、组合语句 compound statements
/pat1/{{ }{ ; }}
4、input statements 输入语句
5、output statements 输出语句
1、expressions 常见表达式
2、control statement 控制语句 例如: if while等
逻辑关系语句判断来进行结合
3、组合语句 compound statements
/pat1/{{ }{ ; }}
4、input statements 输入语句
5、output statements 输出语句
*7、常见语言(if while do for break continue delete switch)
1、if语句
语法格式:if(条件表达式) {执行语句}
if(条件表达式) {执行语句} else {执行语句}
语法格式:while(条件表达式) {循环体}
练习:过滤grub.conf文件中kernel这一行,然后对每一个参数的字符个数进行统计,并显示出来;
在awk中,for也可以使用和 shell 中一样的格式:
回顾:
1、if语句
语法格式:if(条件表达式) {执行语句}
if(条件表达式) {执行语句} else {执行语句}
awk '/^title/{FN<=2? print: printf "参数过
"}' /boot/grub/grub.conf //有点问题
2、while语句
只有对行参数进行遍历的时候才会使用循环;语法格式:while(条件表达式) {循环体}
练习:过滤grub.conf文件中kernel这一行,然后对每一个参数的字符个数进行统计,并显示出来;
初始值
while 条件判断;do
循环体
初始控制语句
done
awk '/^[[:space:]]*kernel>/{i=1;while(i<=NF){printf $i" ";print length($i);i++}}' grub.conf
3、for语句
语法格式:for(初始值;条件判断;初始值控制语句){循环体} awk '/^[[:space:]]*kernel>/{for(i=1; i<=NF; i++){printf $i" "; print length($i)}}' grub.conf
循环建议使用for语句
在awk中,for也可以使用和 shell 中一样的格式:
回顾:
for i in 列表;do
循环体
done
for(i in 列表){循环体}
echo "xia liang z shi k hen n shuai da fa le " | awk '{for(i in {1..NF}) { ls=() if(length(ls[i])<=3){print $i}}}'
shell
=====================================
ls=(xia liang z shi k hen n shuai da fa le)
for i in `seq 0..${$ls[*]}`;do
if [[ ${#${ls[$i]}} <= 3 ]];then
print ls[$i]
fi
done
=====================================
4、do-while 循环
语法:do {循环体} while (循环条件)
注意和while的却别:while语句只有在满足条件的时候,才会进入循环,而do while会先执行循环体(一次),在进行条件判断;
语法:do {循环体} while (循环条件)
注意和while的却别:while语句只有在满足条件的时候,才会进入循环,而do while会先执行循环体(一次),在进行条件判断;
5、循环跳出语句
break [n] 跳出n次循环;
continue 跳出本次循环;
next 跳出默认的当前循环;
break [n] 跳出n次循环;
continue 跳出本次循环;
next 跳出默认的当前循环;
awk '{if(NR%2==1) {next} else {print}}' /etc/passwd
6、switch 类似于case
语法格式:
switch(expression){case VALUE1 or /REGXP/: statement; case VALUE2 or /REGEXP2/:statement; … ,default: statement}
switch(表达式){case 模式匹配值:执行语句;case 模式匹配值:执行语句,...,default:执行语句} 文件
shell:
case 变量 in
pat1)
执行语句
;;
*)
执行语句
;;
esac
*8、数组*
在awk中,数组和shell中的数组特性相同:
注意:awk中数组不用定义,只要使用了,就有值为空的默认数组;这在做数据统计的时候非常常见!!!!!
注意:awk中数组不用定义,只要使用了,就有值为空的默认数组;这在做数据统计的时候非常常见!!!!!
行遍历 --> 实际上就是整个文件的遍历
列遍历 --> 取对象固定某列的中的,相同数据的统计
列遍历 --> 取对象固定某列的中的,相同数据的统计
注意:数组通过for语句,再给其他变量进行赋值的时候,赋值的是index索引信息;
练习:统计一下某个文件中指定行中单词出现的次数;
练习:统计一下某个文件中指定行中单词出现的次数;
awk -v RS=" " {print} a.txt | awk '{ls[$1]++}END{for(i in ls){print i,ls[i]}}'
练习:统计一下一个文件中每个单词(以空格隔开的字符串)出现的次数;
awk '{for(i=1;i<=NF;i++){count[$i]++}}END{for(i in count) {print i,count[i]}}' /etc/fstab
awk '{for(i=1;i<=NF;i++){ls[$i]++}}END{for(j in ls){print j,ls[j]}}' /var/log/httpd/access_log | sort -t" " -k2 -nr
9、函数
1、内置函数
函数的调用:funcation(参数)
length() 统计字符串长度
数学运算上使用的行数 sin() cos() ...
sub(x,x,x) 替换第一个匹配到的值
函数的调用:funcation(参数)
length() 统计字符串长度
数学运算上使用的行数 sin() cos() ...
sub(x,x,x) 替换第一个匹配到的值
awk '{print sub(o,O,$1)}' /etc/fstab //将o 替换为 O 文件中的 第一列(第一个匹配值)
gsub(x,x,x) 替换该行所匹配到的所有值
awk '{print gsub(o,O,$1)}' /etc/fstab //将 o 替换为 O 文件中的 第一列(全部匹配值)
split(x,x,x) 指定分隔符去切割文件
netstat -tan | awk '/^tcp>/{split($5,ip,":");print ip[1]}'
netstat -tan | awk '/^tcp>/{split($5,ip,":");count[ip[1]]++}END{for (i in count) {print i,count[i]}}'
2、自定义函数