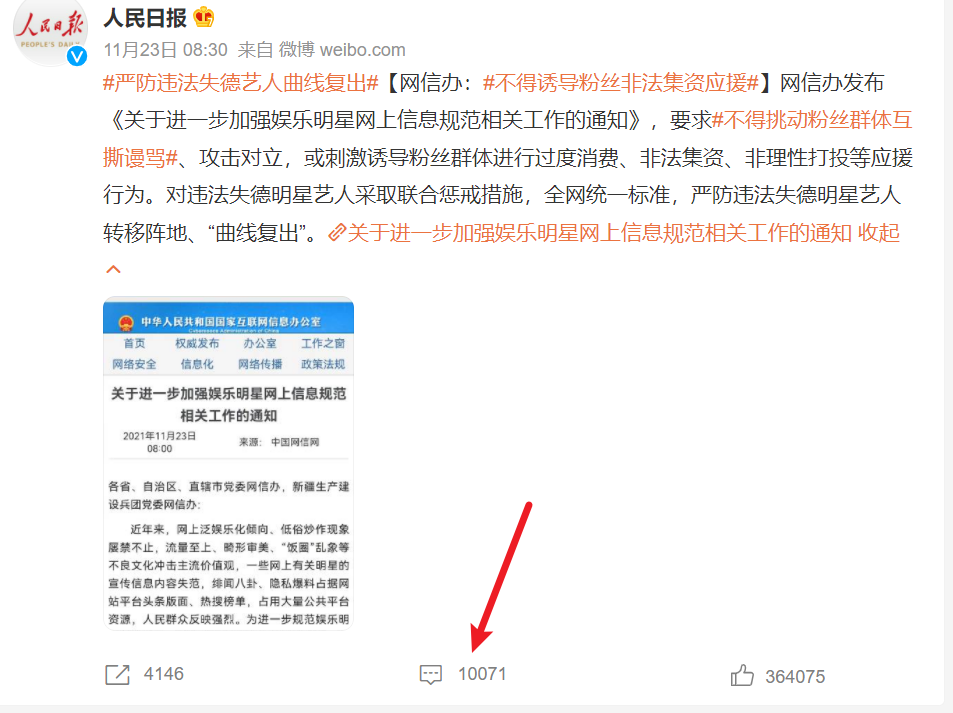
11月23日,人民日报微博客户端发表 - 严禁违法失德艺人曲线复出,总共封禁了88位失德艺人,其中就包括吴某签,郑某爽,还有那个拜靖国神社的东西(这种人活着都是浪费空气,司马的无脑渣渣)。
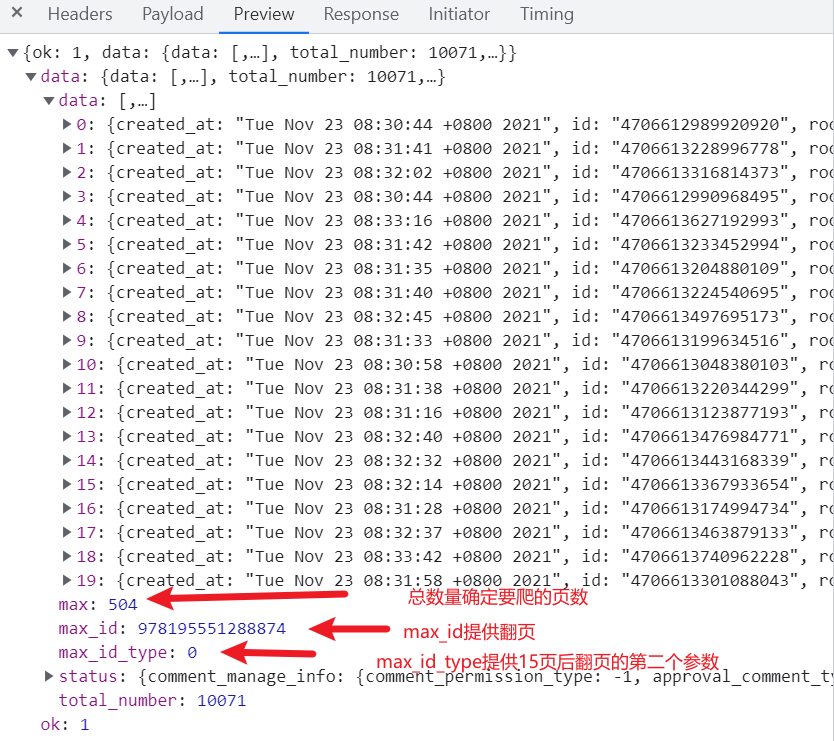
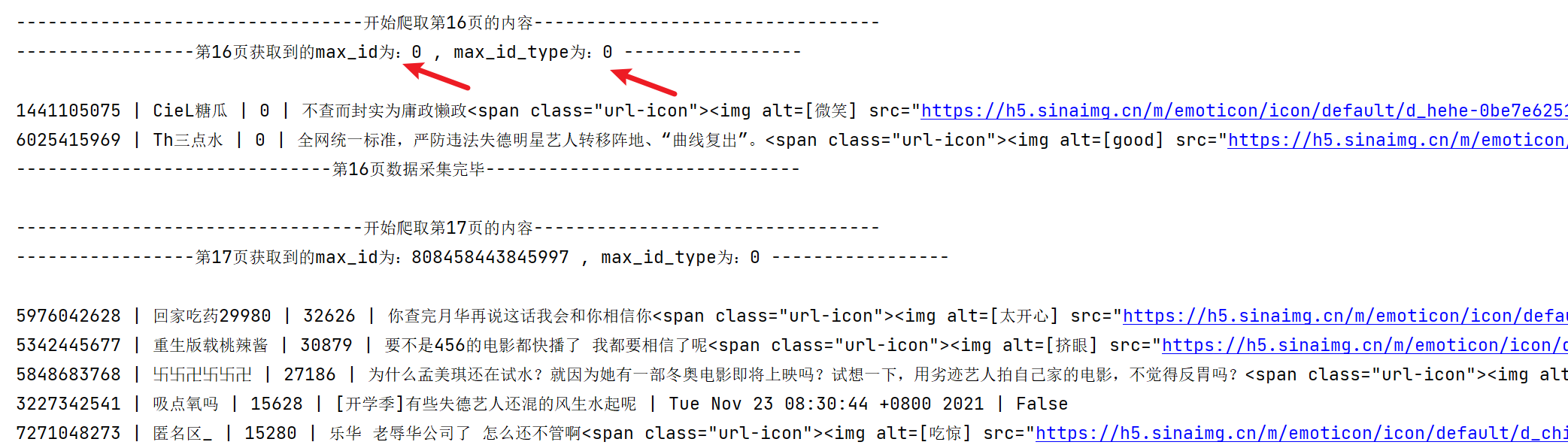
我们来爬一下下方的评论并做个词云可视化。经年爬微博评论,那个PC端是爬到第17爷就会给咱们分发垃圾数据,所以从手机端着手。今天爬跟昨天爬的出生率创40年来最低,人口几近负增长,微博爬虫爬评论规则又不一样,今天爬的规则是每15页会重置max_id和max_id_type为0,两个都是0,不像昨天的15页后会降max_id_type设为1。
开干:
1 """ 2 最近有篇微博火了 3 """ 4 import pprint 5 import random 6 import time 7 import openpyxl 8 import requests 9 import threading 10 11 wb = openpyxl.Workbook() 12 ws = wb.create_sheet(index=0) 13 ws.cell(row=1, column=1, value='评论者Id') # 第一行第一列评论者id 14 ws.cell(row=1, column=2, value='评论者昵称') # 第一行第二列评论者昵称 15 ws.cell(row=1, column=3, value='获赞数') # 第一行第三列评论获赞数 16 ws.cell(row=1, column=4, value='评论内容') # 第一样第四列评论内容 17 ws.cell(row=1, column=5, value='评论时间') # 第一样第五列评论时间 18 ws.cell(row=1, column=6, value='是否认证用户') # 第一样第六列评论者是否认证 19 20 headers = { 21 "Referer": "https://m.weibo.cn/detail/4706612893975061", 22 "Cookie": "SCF=AnKJy3NOK5c-P3XxWYBPzTFGd92WnUEH6LUI_MdzSig02NBwKpa2u00x45GCB3-AOQKJvc_oIAkHIKr7MdST4JE.; SUB=_2A25MbV1zDeRhGedJ61oQ8SjNyTyIHXVvrmM7rDV6PUJbktCOLUfTkW1NVnxxfy_BvTGKBnuuEVnUOYQ8GZaV5mhP; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFCIqm7ZokIkH-v5aWq95ji5NHD95QpS05ReK2ceKz7Ws4Dqcjdi--fiK.7iK.pi--fiKy2iK.Ni--fiKL2i-2p; _T_WM=25534804088; WEIBOCN_FROM=1110005030; MLOGIN=1; XSRF-TOKEN=fb7e62; M_WEIBOCN_PARAMS=oid=4706612893975061&luicode=20000061&lfid=4706612893975061&fid=231522type%3D1%26q%3D%23%E4%B8%A5%E9%98%B2%E8%BF%9D%E6%B3%95%E5%A4%B1%E5%BE%B7%E8%89%BA%E4%BA%BA%E6%9B%B2%E7%BA%BF%E5%A4%8D%E5%87%BA%23&uicode=10000011", 23 "User-Agent": "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Mobile Safari/537.36", 24 "X-XSRF-TOKEN": "9ba0c4", 25 } 26 # url = 'https://m.weibo.cn/comments/hotflow?id=4706612893975061&mid=4706612893975061&max_id={max_id}&max_id_type={max_id_type}' 27 28 page = 1 29 while page < int(504 / 10) + 1: 30 time.sleep(random.uniform(2, 5)) 31 print(f"---------------------------------开始爬取第{page}页的内容---------------------------------") 32 if page == 1: 33 url = 'https://m.weibo.cn/comments/hotflow?id=4706612893975061&mid=4706612893975061&max_id_type=0' 34 else: 35 url = f'https://m.weibo.cn/comments/hotflow?id=4706612893975061&mid=4706612893975061&max_id={max_id}&max_id_type={max_id_type}' 36 # 进入循环,第一次开始爬取第一页,会返回max_id和max_type_id 37 response = requests.get(url=url, headers=headers) # 请求网页 38 # pprint.pprint(response.json()['data']) # 打印一下 39 max_id = response.json()['data']['max_id'] # max_id 40 max_id_type = response.json()['data']['max_id_type'] # max_id_type 41 print(f'-----------------第{page}页获取到的max_id为:{max_id} , max_id_type为:{max_id_type} -----------------\n') 42 # 解析数据 43 results = response.json()['data']['data'] # 获取评论数据 44 # pprint.pprint(results) 45 for item in results: 46 userId = item['user']['id'] # 评论者id 47 userName = item['user']['screen_name'] # 评论者昵称 48 likeCounts = item['like_count'] # 评论获赞数 49 content = item['text'] # 评论内容 50 commentTime = item['created_at'] # 评论时间 51 isVerifiedUser = item['user']['verified'] # 是否认证用户 52 print(userId, userName, likeCounts, content, commentTime, isVerifiedUser, sep=" | ") 53 # 存储数据 54 ws.append([userId, userName, likeCounts, content, commentTime, isVerifiedUser]) # 添加数据 55 print(f'------------------------------第{page}页数据采集完毕------------------------------\n') 56 time.sleep(1) 57 page += 1 # 循环条件 58 # if page == 3: 59 # break 60 wb.save('严禁违法失德艺人曲线复出评论.xlsx') 61 wb.close() # 关闭文档
看下有变化的部分运行截图:
爬虫完毕,做个词云可视化:
1 import re 2 import jieba 3 from stylecloud import gen_stylecloud 4 import pandas as pd 5 6 datafile = pd.read_excel('严禁违法失德艺人曲线复出评论.xlsx') 7 wordsStr = ''.join(datafile['评论内容'].tolist()) # 转成字符串串 8 # print(wordsStr) 9 # wordsStr = re.sub("[0-9A-Za-z\u4e00-\u9fa5]", '', wordsStr) 10 wordsStr = re.sub('[0-9a-zA-Z\< =\":\/;\.\_\->\]\[?,。!“”、\@...\'\?\%…\&]', '', wordsStr) # 替换标点符号和英文词 11 # print(wordsStr) 12 13 words = jieba.cut(wordsStr) # 分词,是个生成器 14 # 再次转换成字符串 15 results = ' '.join(words) 16 stopWords = ['你', '我', '是', '的', '最', '还', '还有', '就是', '咱', '也', '不', '知道', '怎么', 17 '呢', '吧', '过', '把', '请', '管', '一管', '上', '在', '了', '起', '倒', '爬', '电', 18 '呵呵', '很', '她', '他', '太', '有', '说', '这个', '号', '这种','我们', '开始', '天天', 19 '什么', '比如', '时候', '里', '都', '吗', '啊', '给', '一个', '一下', '又', '可', '还是', 20 '没', '能', '不能', '已经', '该', '谁', '啥', '就', '为', '但是', '来', '先', '别', '到',] 21 22 gen_stylecloud( 23 text=results, 24 size=1280, # stylecloud 的大小(长度和宽度) 25 font_path='C:\\Windows\\Fonts\\simhei.ttf', 26 max_font_size=200, # stylecloud 中的最大字号 27 max_words=150, 28 stopwords=True, # 布尔值,用于筛除常见禁用词 29 # invert_mask=pic, 30 custom_stopwords=stopWords, 31 output_name='1.png', 32 )
如图:

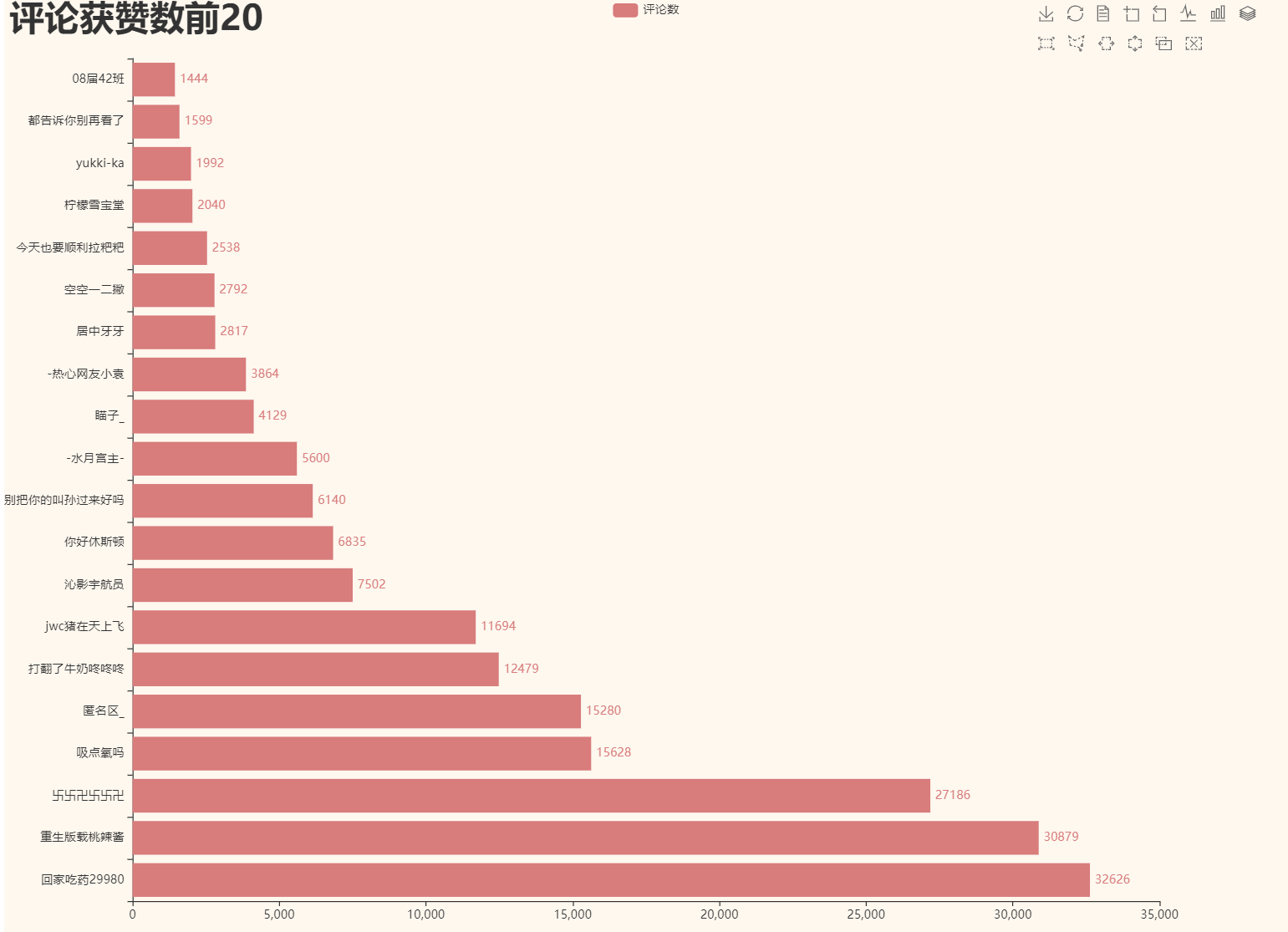
做一下获赞数排行的可视化:
1 import pandas as pd 2 from pyecharts.charts import Bar 3 import pyecharts.options as opts 4 from pyecharts.globals import ThemeType 5 6 # 读文档 7 datafile = pd.read_excel('严禁违法失德艺人曲线复出评论.xlsx') 8 # print(datafile['获赞数']) 9 # 去重 10 df_new = datafile.drop_duplicates(['评论者Id']) # 根据id去重 11 # 提取数据并排序 12 results = df_new.sort_values(by=['获赞数'], ascending=False) #根据获赞数排序 13 14 x_data = results['评论者昵称'].values.tolist()[0:20] # 提取排序后的昵称到列表,取前20个 15 y_data = results['获赞数'].values.tolist()[0:20] # 提取排序后的获赞数到列表,取前20个 16 17 print(x_data, y_data) 18 # 开始绘图 19 bar = ( 20 Bar(init_opts=opts.InitOpts(width='1280px', height='960px', theme=ThemeType.VINTAGE)) 21 .add_xaxis(xaxis_data=x_data) 22 .add_yaxis(series_name='评论数',y_axis=y_data,) 23 .set_global_opts( 24 title_opts=opts.TitleOpts( 25 title='评论获赞数前20', 26 title_textstyle_opts=opts.TextStyleOpts(font_size=35), 27 ), 28 tooltip_opts=opts.TooltipOpts( 29 is_show=True, 30 trigger='axis', 31 axis_pointer_type='cross', 32 ), 33 toolbox_opts=opts.ToolboxOpts(), # 什么参数不传会全部展示 34 ) 35 .set_series_opts(label_opts=opts.LabelOpts(is_show=True, position='right')) 36 .reversal_axis() # 翻转坐标轴,不翻转昵称看不到 37 ).render('1.html')
运行后截图: