一:代理池维护的模块
1. 抓取模块Crawl,负责从代理网站上抓取代理 ---------------抓取模块
2. 获取代理Getter,负责获取抓取模块返回的值,并判断是否超过存储模块的最大容量。---------------获取模块
3.存储模块Redis,负责将抓取的每一条代理存放至有序集合中。---------------存储模块
4.测试模块Tester,负责异步测试每个代理是否可用。---------------测试模块
5.调度模块Schedule,负责测试,获取,和对外api的接口运转。---------------调度模块
6.Flask对外接口,通过视图函数,获取jison值。---------------接口模块
7.utilis工具类,提供了每个网站的页面解析。---------------工具类模块
二:抓取模块
import re from ulits import get_66ip_content,get_xc_content,get_89_content from bs4 import BeautifulSoup class Crawl(object): def get_proxy(self): proxies = list() for value in self.crawl_proxy_66(5): proxies.append(value) for value in self.crawl_get_89proxy(5): proxies.append(value) for value in self.crawl_xc_proxy(5): proxies.append(value) return proxies def crawl_proxy_66(self, total_page): """ :return:代理 """ start_url = "http://www.66ip.cn/{}.html" url_list = [start_url.format(i) for i in range(1,total_page + 1)] for url in url_list: content = get_66ip_content(url) soup = BeautifulSoup(content,"lxml") div = soup.find("div", id="main") table = div.table tr_list = table.find_all("tr") for tr in tr_list[1:]: tr = str(tr) # 把soup.element强行变成str字符串 pattern = re.compile(r"<td>(.*?)</td><td>(.*?)</td>",re.S) result = re.search(pattern,tr) ip = result.group(1) port = result.group(2) yield ":".join([ip,port]) def crawl_xc_proxy(self,total_page): start_url = "https://www.xicidaili.com/wt/{}" url_list = [start_url.format(i) for i in range(1,total_page + 1)] for url in url_list: html = get_xc_content(url) soup = BeautifulSoup(html, "lxml") div = soup.find("div",id="body") table = div.table tr_list = table.find_all("tr") for tr in tr_list[1:]: tr = str(tr) pattern = re.compile("<td>(.*?)</td>", re.S) result = re.findall(pattern, tr) if len(result) > 2: ip = result[0] port = result[1] yield ":".join([ip, port]) def crawl_get_89proxy(self,total_page): start_url = "http://www.89ip.cn/index_{}.html" url_list = [start_url.format(i) for i in range(1,total_page+1)] for url in url_list: html = get_89_content(url) soup = BeautifulSoup(html, "lxml") # 获取class属性的标准写法 div = soup.find(name="div", attrs={"class": "layui-form"}) table = div.table tr_list = table.find_all("tr") for tr in tr_list[1:]: tr = str(tr) pattern = re.compile("<td>(.*?)</td>", re.S) result = re.findall(pattern, tr) if len(result) > 2: ip = (result[0]).replace(" ", "") ip = ip.replace(" ", "") port = (result[1]).replace(" ", "") port = port.replace(" ", "") yield ":".join([ip, port])
三:获取模块
from Redis import ReidsClient from Crawl import Crawl POOL_MAX_COUNT = 10000 class Getter(object): def __init__(self): self.redis = ReidsClient() self.crwal = Crawl() def is_exceed_poolcount(self): """ 判读是否超过代理池的最大容量 :return: True超过,False没有超过 """ ret = self.redis.get_count() > POOL_MAX_COUNT return ret def run(self): print("计数器开始计时") if not self.is_exceed_poolcount(): proxies = self.crwal.get_proxy() for proxy in proxies: self.redis.add(proxy) if __name__ == '__main__': g = Getter() g.run()
四:存储模块
MAX_SOCRE = 100 MIN_SCORE = 0 INITIAL_SCORE = 10 REDIS_HOST = "127.0.0.1" REDIS_PORT = 6379 REDIS_PASSWORD = None REDIS_KEY = "proxies" import redis from random import choice class ReidsClient(object): def __init__(self,host=REDIS_HOST,port=REDIS_PORT, password=REDIS_PASSWORD): self.db = redis.StrictRedis(host=host,port=port,password=password,decode_responses=True) # 这样写存的数据是字符串格式 def add(self, proxy, score=INITIAL_SCORE): """ 添加代理,设置分数最高 :param proxy:代理 :param score:分数 :return:添加结果 """ # 从有序集合REDIS_KEY中获取proxy的权重分,没有添加 if not self.db.zscore(REDIS_KEY,proxy): # 将新的proxy放入redis的REDIS_KEY集合中, return self.db.zadd(REDIS_KEY,score,proxy) # 这里容易报一个错是:AttributionErro:int object have no arrtibution items,原因是redis这个包的版本问题 # 解决包的版本问题:pip install redis==2.10.6 def get_random(self): """ 随机获取代理,获取顺序是最高分的代理 :return:随机代理 """ # 获取分数最高分数 result = self.db.zrangebyscore(REDIS_KEY,MAX_SOCRE,MAX_SOCRE) if len(result): return choice(result) # 随机抽取,保证每个代理都可能被获取到。 else: result = self.db.zrevrange(REDIS_KEY,MIN_SCORE,MAX_SOCRE) # 拿不到最高分的代理,那么就拿次高分的代理 if len(result) > 1: return result[0] else: return "代理池为空" def decrease(self,proxy): """ 代理不能用的话,分数就减1,分数为0,从代理池中删除 :param proxy:代理 :return:修改后的分数 """ score = self.db.zscore(REDIS_KEY,proxy) if score and score > MIN_SCORE: print("代理",proxy,"当前的分数",score,"减1") return self.db.zincrby(REDIS_KEY,proxy,-1) else: print("代理", proxy, "当前的分数", score, "移除") return self.db.zrem(REDIS_KEY,proxy) # 删除无效代理 def exist(self,proxy): """ 判断代理是否存在 :param proxy:代理 :return:True or False """ result = self.db.zscore(REDIS_KEY,proxy) if result != None: return True else: return False def set_max_value(self,proxy): """ 将代理设置为MAX_SCORE值 :param proxy: 代理 :return:设置结束 """ print("代理",proxy,"可用","设置值为",MAX_SOCRE) return self.db.zadd(REDIS_KEY,MAX_SOCRE,proxy) def get_count(self): """ :return: 返回有序集合中的数量 """ return self.db.zcard(REDIS_KEY) def get_all(self): """ :return: 获取所有元素,返回列表 """ return self.db.zrangebyscore(REDIS_KEY,MIN_SCORE,MAX_SOCRE)
五:测试模块
import time VALID_STATUSC_CODES = [200] TEST_URL = "http://www.baidu.com" BATCH_TEST_SIZE = 100 from Redis import ReidsClient import aiohttp import asyncio class Test(object): def __init__(self): self.redis = ReidsClient() async def test_single_proxy(self,proxy): """ 测试单个代理 :param proxy: 代理 :return: None """ coon = aiohttp.TCPConnector(verify_ssl=False) # 区别于requests库;是一个异步非阻塞的库 async with aiohttp.ClientSession(connector=coon) as session: try: if isinstance(proxy,bytes): proxy = proxy.decode("utf-8") real_proxy = "http://" + proxy print("正在测试",proxy) async with session.get(TEST_URL,proxy=real_proxy,timeout=15) as response: if response.status in VALID_STATUSC_CODES: self.redis.set_max_value(proxy) # 能用,给代理设置最高的权重分,存入数据库 print("代理可以用",proxy) else: self.redis.decrease(proxy) # 超时未请求到,给此代理减分 print("响应码不合格",proxy) except (ConnectionError,TimeoutError,AttributeError): self.redis.decrease(proxy) # 发生故障给此代理减分 print("代理请求失败",proxy) def run(self): """ 测试主函数 :return: """ print("测试函数开始运行") try: proxies = self.redis.get_all() # 从数据库中获取全部的代理 loop = asyncio.get_event_loop() for i in range(0,len(proxies),BATCH_TEST_SIZE): test_proxies = proxies[i:i + BATCH_TEST_SIZE] tasks = [self.test_single_proxy(proxy) for proxy in test_proxies] loop.run_until_complete(asyncio.wait(tasks)) time.sleep(5) except Exception as e: print("测试器发生错误",e.args)
六:调度模块
import time TESTER_CYCLE = 20 GETTER_CYCLE = 20 TESTER_ENABLED = True GETTER_ENABLED = True API_ENABLED = True API_HOST="localhost" API_PORT="8888" from multiprocessing import Process from Flask import app from Getter import Getter from Tester import Test class Scheduler(object): def schedule_tester(self,cycle=TESTER_CYCLE): """ 定时测试代理 :param cycle: :return: """ tester = Test() while True: print("测试器开始运行") tester.run() time.sleep(cycle) def scheduler_getter(self,cycle=GETTER_CYCLE): """ 定时获取代理 :param cycle: :return: """ getter = Getter() while True: print("开始抓取代理") getter.run() time.sleep(cycle) def scheduler_api(self): """ 开启api :return: """ app.run(API_HOST,API_PORT) def run(self): print("代理池开始运行") if TESTER_ENABLED: tester_process = Process(target=self.schedule_tester) tester_process.start() if GETTER_ENABLED: getter_process = Process(target=self.scheduler_getter) getter_process.start() if TESTER_ENABLED: api_process = Process(target=self.scheduler_api) api_process.start() if __name__ == '__main__': s = Scheduler() s.run()
七:接口
from flask import Flask,g from Redis import ReidsClient __all__ = ["app"] app = Flask(__name__) def get_coon(): if not hasattr(g,"redis"): g.redis = ReidsClient() return g.redis @app.route("/") def index(): return "<h2>Welcome to Proxy Pool System</h2>" @app.route("/random") def get_proxy(): """ 获得随机代理 :return: 随机代理 """ coon = get_coon() return coon.get_random() @app.route("/count") def get_count(): """ 获取代理池的总量 :return: """ coon = get_coon() return str(coon.get_count()) if __name__ == '__main__': app.run()
八:运行结果截图
程序运行情况

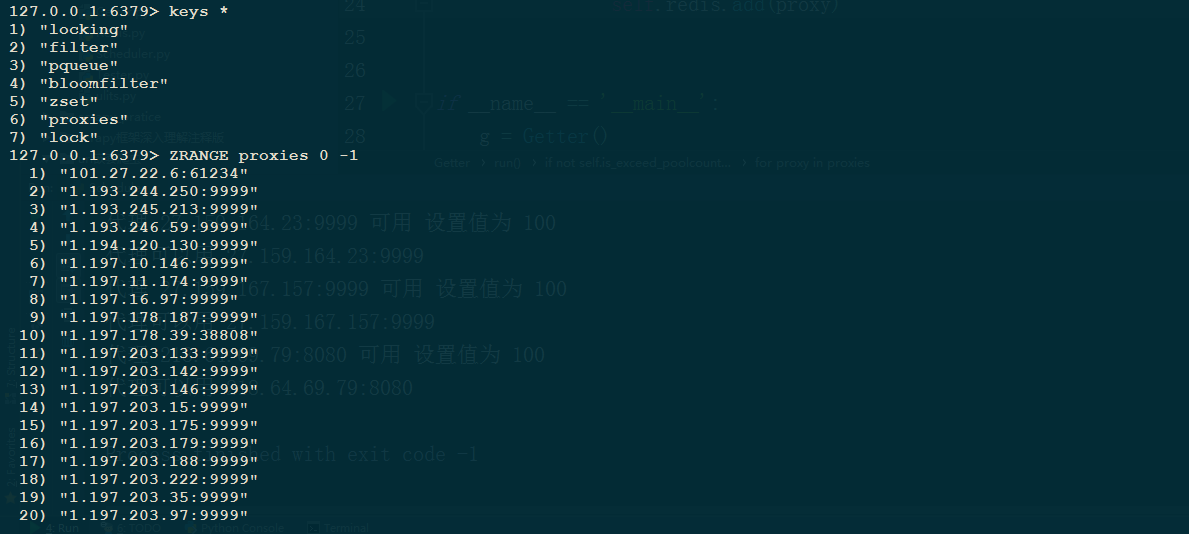
数据库情况
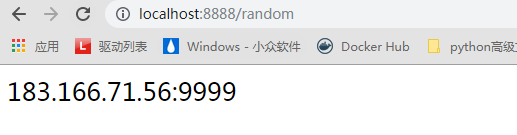
接口访问情况

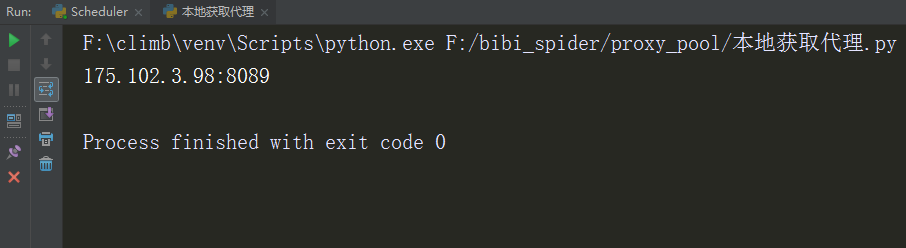
九:本地使用
import requests PROXY_URL = "http://localhost:8888/random" def get_proxy(): try: response = requests.get(PROXY_URL) if response.status_code == 200: return response.content.decode("utf-8") except ConnectionError: return None get_proxy() print(get_proxy())
十:总结
为什么要使用Flask接口呢:
1.使用本地的redis链接,直接调取里面的random方法也可以拿到可用的代理,但是这样就暴露了reids的用户名和密码,对数据不安全。
2.代理池要部署到远端服务器,而远端的reids只允许本地连接,那么我们就不能获取代理。
3.爬虫主机,不是用python语言编写,就无法使用RedisClient这个类了,这样没有扩展性。
4.如果reids数据库有更新,那么我们就得修改爬虫端的程序,比较麻烦。