主成分分析PCA(Principal Component Analysis)是非监督的机器学习方法,广泛应用于数据降维。在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上增加了数据采集的工作量,更重要的是在多数情况下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性,同时对分析带来不便。如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。盲目减少指标会损失很多信息,容易产生错误的结论。因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。主成分分析与因子分析就属于这类降维的方法。
一.主成分分析思想
PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的信息量最大(方差最大),以此使用较少的数据维度,同时保留住较多的原数据点的特性。PCA降维的目的,就是为了在尽量保证“信息量不丢失”的情况下,对原始特征进行降维,也就是尽可能将原始特征往具有最大投影信息量的维度上进行投影。将原特征投影到这些维度上,使降维后信息量损失最小。
二,主成分分析求解步骤
求解步骤如下:
- 去除平均值
- 计算协方差矩阵
- 计算协方差矩阵的特征值和特征向量
- 将特征值排序
- 保留前N个最大的特征值对应的特征向量
- 将原始特征转换到上面得到的N个特征向量构建的新空间中,实现特征压缩。
假设有M个样本{X1,X2,...,XM},每个样本有N维特征 Xi=(xi1,xi2,...,xiN)T,每一个特征xjxj都有各自的特征值。
第一步:对所有特征进行中心化:去均值。
求每一个特征的平均值,然后对于所有的样本,每一个特征都减去自身的均值。经过去均值处理之后,原始特征的值就变成了新的值,在这个新值基础上,进行下面的操作。
第二步:求协方差矩阵C(以二维特征为例)
计算公式:
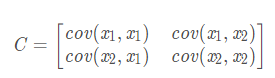
上述矩阵中,对角线上分别是特征x1和x2的方差,非对角线上是协方差。协方差大于0表示x1和x2 若有一个增,另一个也增;小于0表示一个增,一个减;协方差为0时,两者独立。协方差绝对值越大,两者对彼此的影响越大,反之越小。其中,cov(x1,x1)的求解公式如下,其他类似。
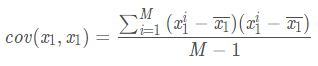
根据上面的协方差计算公式我们就得到了这M个样本在这N维特征下的协方差矩阵C。之所以除以M-1而不是除以M,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计”。
第三步:求协方差矩阵C的特征值和相对应的特征向量。
利用矩阵的知识,求协方差矩阵 C 的特征值 λ 和相对应的特征向量 u(每一个特征值对应一个特征向量):Cu=λu
特征值λ会有N个,每一个λi对应一个特征向量 ui,将特征值λ按照从大到小的顺序排序,选择最大的前k个,并将其相对应的k个特征向量拿出来,我们会得到一组{(λ1,u1),(λ2,u2),...,(λk,uk)}。
第四步:将原始特征投影到选取的特征向量上,得到降维后的新K维特征
这个选取最大的前k个特征值和相对应的特征向量,并进行投影的过程,就是降维的过程。对于每一个样本$ Xi$,原来的特征是$(xi_1,xi_2,…,xi_n)^T$,投影之后的新特征是 (yi1,yi2,...,yik)T,新特征的计算公式如下:

三,PCA优缺点
优点:
1、以方差衡量信息的无监督学习,不受样本标签限制。
2、由于协方差矩阵对称,因此k个特征向量之间两两正交,也就是各主成分之间正交,正交就肯定线性不相关,可消除原始数据成分间的相互影响
3. 可减少指标选择的工作量
4.用少数指标代替多数指标,利用PCA降维是最常用的算法
5. 计算方法简单,易于在计算机上实现。
缺点:
1、主成分解释其含义往往具有一定的模糊性,不如原始样本完整
2、贡献率小的主成分往往可能含有对样本差异的重要信息,也就是可能对于区分样本的类别(标签)更有用
3、特征值矩阵的正交向量空间是否唯一有待讨论
4、无监督学习
四,Python代码实现
1.参数说明:
n_components:
意义:PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n
类型:int 或者 string,缺省时默认为None,所有成分被保留。
赋值为int,比如n_components=1,将把原始数据降到一个维度。
赋值为string,比如n_components='mle',将自动选取特征个数n,使得满足所要求的方差百分比。
copy:
类型:bool,True或者False,缺省时默认为True。
意义:表示是否在运行算法时,将原始训练数据复制一份。若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;若为False,则运行PCA算法后,原始训练数据的值会改,因为是在原始数据上进行降维计算。
whiten:
类型:bool,缺省时默认为False
意义:白化,使得每个特征具有相同的方差。关于“白化”,可参考:Ufldl教程
2.PCA对象的属性
components_ :返回具有最大方差的成分。
explained_variance_ratio_:返回所保留的n个成分各自的方差百分比。
n_components_:返回所保留的成分个数n。
mean_:
noise_variance_:
3.PCA对象的方法
fit(X,y=None)
fit()可以说是scikit-learn中通用的方法,每个需要训练的算法都会有fit()方法,它其实就是算法中的“训练”这一步骤。因为PCA是无监督学习算法,此处y自然等于None。
fit(X),表示用数据X来训练PCA模型。
函数返回值:调用fit方法的对象本身。比如pca.fit(X),表示用X对pca这个对象进行训练。
fit_transform(X):用X来训练PCA模型,同时返回降维后的数据,newX=pca.fit_transform(X),newX就是降维后的数据。
inverse_transform():将降维后的数据转换成原始数据,X=pca.inverse_transform(newX)
transform(X):将数据X转换成降维后的数据。当模型训练好后,对于新输入的数据,都可以用transform方法来降维。
4. 案例
import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.decomposition import PCA iris = load_iris() y = iris.target X = iris.data #作为数组,X是几维? X.shape#(150, 4) #作为数据表或特征矩阵,X是几维? import pandas as pd pd.DataFrame(X).head() #调用PCA pca = PCA(n_components=2) #实例化 pca = pca.fit(X) #拟合模型 X_dr = pca.transform(X) #获取新矩阵 X_dr #也可以fit_transform一步到位 #X_dr = PCA(2).fit_transform(X) #要将三种鸢尾花的数据分布显示在二维平面坐标系中,对应的两个坐标(两个特征向量)应该是三种鸢尾花降维后的x1和x2,怎样才能取出三种鸢尾花下不同的x1和x2呢? X_dr[y == 0, 0] #这里是布尔索引,看出来了么? #要展示三中分类的分布,需要对三种鸢尾花分别绘图 #可以写成三行代码,也可以写成for循环 """ plt.figure() plt.scatter(X_dr[y==0, 0], X_dr[y==0, 1], c="red", label=iris.target_names[0]) plt.scatter(X_dr[y==1, 0], X_dr[y==1, 1], c="black", label=iris.target_names[1]) plt.scatter(X_dr[y==2, 0], X_dr[y==2, 1], c="orange", label=iris.target_names[2]) plt.legend() plt.title('PCA of IRIS dataset') plt.show() """ colors = ['red', 'black', 'orange'] iris.target_names plt.figure() for i in [0, 1, 2]: plt.scatter(X_dr[y == i, 0] ,X_dr[y == i, 1] ,alpha=.7#指画出的图像的透明度 ,c=colors[i] ,label=iris.target_names[i] ) plt.legend()#图例 plt.title('PCA of IRIS dataset') plt.show()
生成图如下:

#属性explained_variance_,查看降维后每个新特征向量上所带的信息量大小(可解释性方差的大小) pca.explained_variance_#查看方差是否从大到小排列,第一个最大,依次减小 array([4.22824171, 0.24267075]) #属性explained_variance_ratio,查看降维后每个新特征向量所占的信息量占原始数据总信息量的百分比 #又叫做可解释方差贡献率 pca.explained_variance_ratio_#array([0.92461872, 0.05306648]) #大部分信息都被有效地集中在了第一个特征上 pca.explained_variance_ratio_.sum()#0.977685206318795 import numpy as np pca_line = PCA().fit(X) # pca_line.explained_variance_ratio_#array([0.92461872, 0.05306648, 0.01710261, 0.00521218]) plt.plot([1,2,3,4],np.cumsum(pca_line.explained_variance_ratio_)) plt.xticks([1,2,3,4]) #这是为了限制坐标轴显示为整数 plt.xlabel("number of components after dimension reduction") plt.ylabel("cumulative explained variance ratio") plt.show()
碎石图如下:
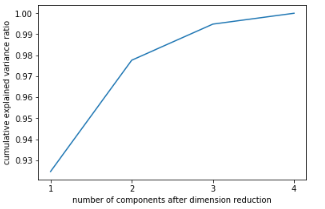
pca_mle = PCA(n_components="mle")#mle缺点计算量大 pca_mle = pca_mle.fit(X) X_mle = pca_mle.transform(X) X_mle#3列的数组 #可以发现,mle为我们自动选择了3个特征 pca_mle.explained_variance_ratio_.sum()#0.9947878161267247 #得到了比设定2个特征时更高的信息含量,对于鸢尾花这个很小的数据集来说,3个特征对应这么高的信息含量,并不 # 需要去纠结于只保留2个特征,毕竟三个特征也可以可视化 pca_f = PCA(n_components=0.97,svd_solver="full")#svd_solver="full"不能省略 pca_f = pca_f.fit(X) X_f = pca_f.transform(X) X_f pca_f.explained_variance_ratio_#array([0.92461872, 0.05306648]) #X.shape()#(m,n) PCA(2).fit(X).components_.shape#(2, 4) PCA(2).fit(X).components_#V(k,n) # array([[ 0.36138659, -0.08452251, 0.85667061, 0.3582892 ], # [ 0.65658877, 0.73016143, -0.17337266, -0.07548102]])
以上是第九周的学习内容,留作之后参考。