运行时生成语句
1、用EXECUTE执行动态命令
EXECUTE命令可以执行存储过程、函数和动态的字符串命令。注意此语句的作用正如前面在介绍批处理时,如果批中的第一条语句是"EXECUTE存储过程",则可以省略关键字"EXECUTE"。
语法:
{ EXEC | EXECUTE }
( { @string_variable | [N]'tsql_string } [+...n] )
[ AS { LOGIN | USER } = 'name' ]
[;]
参数说明:
EXEC:是EXECUTE的简写,两者皆可使用。
@string_variable:局部变量的名称,可以是任意char、varchar、nchar或nvarchar数据类型,其中包括(max)数据类型。可以将T-SQL代码封装在局部变量中被执行。
[N]'tsql_string':常量字符串,可以使任意nvarchar或varchar数据类型。如果包含N,则字符串将解释成nvarchar数据类型。如果不是动态生成的字符串命令,直接将其写成常量字符串也可以直接被执行。
[ AS { LOGIN | USER } = 'name' ]:LOGIN指定执行的上下文(Context)为登录名,所以其执行范围为服务器级;USER指定执行的上下文为用户,所以其执行范围为数据库级。
注意事项:EXECUTE在使用中可能导致SQL注入式攻击,即超越用户本身权限的SQL语句可能会被执行,这样在生成动态命令字符串时,可以对字符串的内容进行检查。通过指定执行上下文,即使用[ AS { LOGIN | USER } = 'name' ]的语法形式,可以限定EXECUTE语句的执行环境,确保安全。
2、用SP_EXECUTESQL执行动态命令
SP_EXECUTESQL是一个系统存储过程,其功能和EXECUTE大致相同,不同的是其支持参数替换功能。而EXECUTE不支持参数替换功能。
功能:
执行可以多次重复使用或动态生成的T-SQL语句或批处理,可以包含嵌入的参数。在批处理、临时变量作用域和数据库上下文上,SP_EXECUTESQL与EXECUTE相同。
语法:
SP_EXECUTESQL [ @stmt= ] stmt [ {,[@params=] N'@parameter_name data_type [[OUT [PUT] [,...n]'} { ,[ @paraml = ] 'value1' [,...n] } ]
参数说明:
[@stmt = ] stmt :包含T-SQL语句或批处理的Unicode字符串,必须是可以隐式转换为ntext的Unicode常量或变量,但不能是表达式。使用字符串常量必须以N作为前缀。例如,Unicode常量N'sp_who'是有效的。但字符串常量'sp_who'则无效。字符串的大小仅受可用数据库服务器内存限制。
[@params = ] N'@parameter_name data_type[,...n]':stmt中嵌入的所有参数定义的字符串。该字符串必须是可隐式转换为ntext的Unicode常量或变量。每个参数定义由参数名称和数据类型组成。在stmt中指定的每个参数必须在@params中定义。如果stmt中的T-SQL语句或批处理不包含参数。则不需要@params。该参数的默认值为NULL。n是表示附加参数定义的占位符。
[@params1 = ] 'value1':参数字符串中定义的第一个参数的值。该值可以使常量或变量。必须为stmt中包含的每个参数提供参数值。如果stmt中的T-SQL语句或批处理没有参数,则不需要这些值。
OUTPUT:指示该参数是输出参数。
N:附加参数的占位符。这些值只能是常量或变量。不能是表达式。
代码示例:
declare @sql_str nvarchar(200) declare @Id int set @Id = 15 set @sql_str = 'select * from person where Id = ' + convert(varchar,@Id) execute sp_executesql @sql_str
3、参数替换
SP_EXCUTESQL和EXECUTE比较起来,其最大的特想在于参数替换,而EXECUTE语句不支持该功能。由于EXECUTE不支持在执行的语句中包含参数,所以即使对于下面这两条功能完全一致的,仅仅输入值不同的语句,SQL Server引擎在执行时也需要重新编译执行。
select * from person where Id = 275 select * from person where Id = 276
反之,如果使用SP_EXECUTESQL来执行,我们可以编写执行代码如下,由于仅仅是参数值的替换,所以引擎只需要编译一次就可以。

declare @intvariable int; declare @sqlstring nvarchar(500);set @stringsql = N'select * from person where Id = @pId' --第一次赋值执行 set @intvariable = 275 EXECUTE sp_executesql @SQLString,@pId = @intvariable; set @intvariable = 275 --第二次赋值执行 EXECUTE sp_executesql @SQLString,@pId = @intvariable;
与EXECUTE比较起来,SP_EXECUTESQL执行动态生成的字符串命令其有点如下:
1、参数替换带来的高效率
就如上述SQL语句,对于只是参数不同的操作,SQLServer只需要编译一次。 而如果用EXECUTE,SQLServer要编译两次。
字符串文本更改的后果,EXECUTE影响SQLServer查询优化器将新的T-SQL字符串与现有的执行计划相匹配的功能,而SP_EXECUTESQL的T-SQL的实际文本在两次执行之间未更改,所以查询优化器能够将第二次执行中的T-SQL语句与第一次执行时生成的执行计划相匹配。因此,SQLServer不必编译第二条语句。
EXECUTE每次执行都要重新生成,而SP_EXECUTESQL只需要生成一次。
字符串的转换,EXECUTE每次执行时都必须将参数值(非字符或Unicode值)转换为字符或Unicode格式。整型参数按其本身格式指定。不需要转换为Unicode。
2、执行计划重用带来的高效率。
使用SP_EXECUTE可以重用SQL Server的执行计划。多次执行T-SQL语句且只更改了提供给T-SQL语句的参数值时,可以使用SP_EXECUTESQL而不要使用存储过程。因为T-SQL语句本身保持不变,仅参数值发生更改,所以SQLServer查询优化器可能会重用第一次执行时生成的执行计划。
4、使用输出参数的SP_EXECUTESQL
在使用SP_EXECUTESQL执行时,可以使用参数。参数的使用有两种类型,一种是输入参数,一种是输出参数。
输入参数是将外部的值带入到字符串命令中,输出参数是将字符串执行结果返回到外部,通常是临时变量中。
1、输出参数的定义
在定义输出参数时,使用OUTPUT关键字或(OUT)定义参数就可以
语法格式:
{ [@params=] N'@parameter_name data_type OUTPUT }
2、获取输出参数的值
常见的获取输出参数的值的方法是在SP_EXECUTE语法中按照下面的形式。
SP_EXECUTESQL 执行的带参数的字符串命令或变量 参数的定义字符串或变量 参数1名称 = 参数1的值 ... OUTPUT
语句之间数据的传递
1、T-SQL语句之间的数据传递
(1)、局部变量传递数据
局部变量好比是一个批处理内部的数据公用存储区,所以批处理内部的语句通过局部变量的名称就可以引用定义的变量数据。
(2)、参数传递数据
参数是在存储过程和执行该存储过程的批处理或脚本之间传递数据的对象。参数可以是输入参数也可以是输出参数。
参数的命名和形式和局部变量是完全一致的,也需要说明参数的类型。两者不同的是局部变量是一个批处理内部传递数据的手段,而参数是跨越两个代码段或对 象传递数据的手段。
错误处理
(1)、SQLServer数据库引擎错误
1、查询系统错误信息
SQLServer在每个数据库的系统视图sys.messages中存储系统自定义(Message_id <= 50000)和用户自定义(Message_id>50000)错误消息。
2、系统错误信息的严重性级别
得到的系统错误消息分为不同程度的严重性级别。严重性级别是通过数字来表示的,数字越小表示严重级别越低。反之则严重性越高。严重性较高的错误指示需要尽 快解决问题。
(2)、用try...catch发现错误
try...catch结构 begin try 要执行的T-SQL代码,一旦错误将传递给catch块进行处理 end try begin catch 检索和处理错误信息的代码 end catch 正常执行的T-SQL语句
try:其中,try块是包含在begin try和end try之间的T-SQL代码段,在该代码段中一旦发生错误将传递给catch块,如果没有错误将直接执行catch块后面的代码。
catch:catch块是包含在begin catch和end catch之间的T-SQL代码段,在该代码段中检索和处理try块中的错误信息。
(3)、捕获错误的系统函数
1、error_number()
返回错误的ID号,对应sys.messages系统视图中的message_id字段。
2、error_line()
返回T-SQL代码中错误出现的语句行数。
3、error_message()
返回将返回给应用程序的消息文本。该文本包括为所有可替换参数提供的值,如长度、对象名或时间。对应sys.messages系统视图中的text字段。
4、error_procedure()
返回出现错误的存储过程或触发器名称。如果在存储过程或触发器中未出现错误,该函数返回NULL。
5、error_severity()
返回错误的严重性级别。对应sys.messages系统视图中的severity字段。
6、error_state()
返回状态
示例:
begin try select 1/0 end try begin catch select error_number() as 'number', error_line() as 'line', error_message() as 'message', error_severity() as 'severity', error_state() as 'state' end catch
输出结果如图所示:
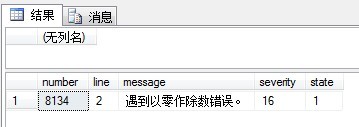
(4)、用@@ERROR捕获上一条语句的错误
T-SQL还提供了一个简单的系统函数@@ERROR来捕获上一条语句的错误。如果上一条语句执行成功。@@ERROR系统函数将返回0;如果上一条语句生成错误,@@ERROR将返回错误号。
每条语句完成时@@ERROR都会更改。
例如:
select 1/0 select * from sys.messages where message_id = @@error and language_id = 2052
结果如图:

(5)、用RAISERROR反馈错误
功能:
将生成的SQLServer引擎错误或警告信息(从sys.messages系统视图获得)反馈到应用程序中。sys.messages系统视图中由SQLServer自身定义的信息,其 message_id列的值小于等于5000。
返回用户使用存储过程sp_addmessage创建的自定义消息(存储在系统视图sys.messages中,其message_id大于50000)。
与print语句的区别:
print语句是T-SQL提供的用于反馈信息的语句,print语句只能反馈字符串或字符串表达式的值。
raiserror语句除了print语句的功能外,还支持类似C语言仲printf函数的字符串替换功能。这样可以先在字符串中定义要替换的数据的类型和位置,在输出时自动将字符串内容进行替换。
语法:
raiserror({ msg_id | msg_str | @local_variable }) { ,severity,state } [ ,argument [ ,...n ] ] ) [ with option [,...n] ]
参数说明:
msg_id:存储在sys.messages系统视图中的错误消息号(message_id)。如果是用户使用as_addmessage系统存储过程自定义的错误消息,其错误号应当大 于50000.如果未指定msg_id,则返回一个错误号为50000的错误消息。
msg_str:用户自定义消息,msg_str是一个字符串,具有可选的嵌入转换规格。每个转换规格都会定义参数列表中的值。如何格式化并将其置于msg_str中转 换规格位置上的字段中,转换规格的格式如下:%[[flag][width][.precision][{h|1}]]type。
@local_variable:包含按照msg_str的方式格式化的字符串的任何有效字符串数据类型的变量。@local_variable的数据类型必须为char或varchar,或者必须 能够隐式转换为这些数据类型。
severity:用户定义的与该消息关联的严重级别。当使用msg_id引发使用sp_addmessage创建的用户定义消息时,paiserror上指定的严重性将覆盖sp_addmessage中指定的严重性。
state:状态号,1至少127之间的任意整数。如果在多个位置引发相同的用户自定义错误,则针对每个位置使用唯一的状态好有助于找到引发错误的代码段。
argument:用于代替msg_str或对应于msg_id的消息中的定义的变量的参数。可以有0个或多个替代参数,但是替代参数的总数不能超过20个。
option:错误的自定义选项。LOG:在SQLServer数据库引擎实例的错误日志和应用程序日志中记录错误;NOWAIT:将消息立即发送给客户端;SETERROR:将 @@ERROR值和ERROR_NUMBER值设置为msg_id或50000,不用考虑严重级别。
