AlexNet学习笔记
目录
AlexNet整体结构
CNN
全连接
TensorFlow实现
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。是由五层CNN和3层全连接实现的,用于分类网络。虽然后来大量比AlexNet更快速更准确的卷积神经网络结构相继出现,但是AlexNet作为开创者依旧有着很多值得学习参考的地方,它为后续的CNN甚至是R-CNN等其他网络都定下了基调,所以下面我们将从AlexNet入手,理解卷积神经网络的一般结构。
AlexNet结构图
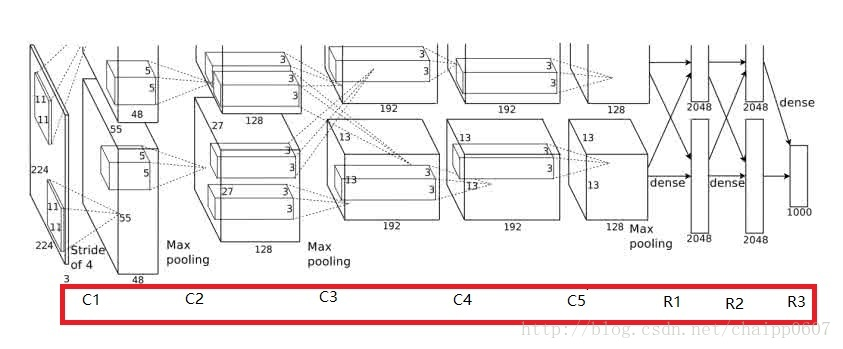
以下是AlexNet的一些参数和结构图:
卷积层:5层
全连接层:3层
深度:8层
参数个数:60M
神经元个数:650k
分类数目:1000类
由于当时的显卡容量问题,AlexNet 的60M个参数无法全部放在一张显卡上操作,所以采用了两张显卡分开操作的形式,其中在C3,R1,R2,R3层上出现交互,所谓的交互就是通道的合并,是一种串接操作。

简化结构图
卷积层
CNN中卷积层的作用----特征的抽象和提取
CNN中的卷积层,在很多网络结构中会用conv来表示,也就是convolution的缩写。卷积层在CNN中扮演着很重要的角色——特征的抽象和提取,这也是CNN区别于传统的ANN或SVM的重要不同,在传统机器学习算法中,我需要人为的指定特征是什么,比如经典的HOG+SVM的行人检测方案,HOG就是一种特征提取方法。所以我们送入SVM分类器中的其实HOG提取出来的特征,而不是图片的本身。而在卷积神经网络中,大部分特征提取的工作在卷积层自动完成了,越深越宽的卷积层一般来说就会有更好的表达能力。
卷积层如何操作
CNN中的卷积层操作与图像处理中的卷积是一样的,都是一个卷积核对图像做自上而下,自左而右的加权和操作,不同指出在于,在传统图像处理中,我们人为指定卷积核,比如Soble,我们可以提取出来图像的水平边缘和垂直边缘特征。而在CNN中,卷积核的尺寸是人为指定的,但是卷积核内的数全部都是需要不断学习得到的。比如一个卷积核的尺寸为3×3×3,分别是宽,高和厚度,那么这一个卷积核中的参数有27个。
在这里需要说明一点:
卷积核的厚度=被卷积的图像的通道数
卷积核的个数=卷积操作后输出的通道数
这两个等式关系在理解卷积层中是非常重要的!!举一个例子,输入图像尺寸5×5×3(宽/高/通道数),卷积核尺寸:3×3×3(宽/高/厚度),步长:1,边界填充:0,卷积核数量:1。用这样的一个卷积核去卷积图像中某一个位置后,是将该位置上宽3,高3,通道3上27个像素值分别乘以卷积核上27个对应位置的参数,得到一个数,依次滑动,得到卷积后的图像,这个图像的通道数为1(与卷积核个数相同),图像的高宽尺寸如下公式:
所以,卷积后的图像尺寸为:3×3×1(宽/高/通道数)
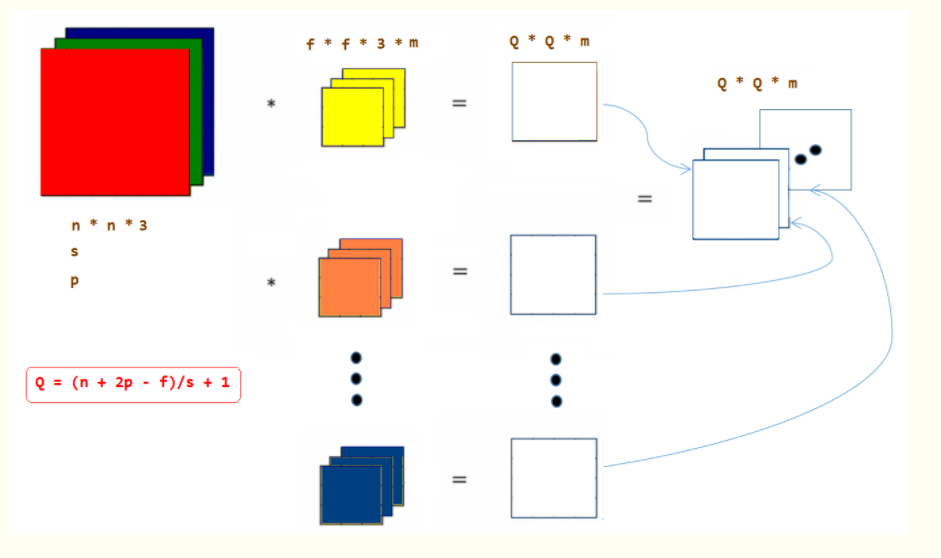
AlexNet中的卷积层
在AlexNet中,卷积层是上图所示的C1…..C5,一共5层。而每次卷积后的结果在上图中可以看到,比如经过卷积层C1后,原始的图像变成了55*55的尺寸,一共有96个通道,分布在2张3G的显卡上,所以上图中一个立方体的尺寸是55×55×4855×55×48,48是通道数目(后面会详细的说明),而在这个立方体里面还有一个5×5×485×5×48的小立方体,这个就是C2卷积层的核尺寸,48是核的厚度(后面会详细说明)。这样我们就能看到它每一层的卷积核尺寸以及每一层卷积之后的尺寸。我们按照上面的说明,推到下每一层的卷积操作:
需要说明的是,虽然AlexNet网络都用上图的结构来表示,但是其实输入图像的尺寸不是224×224×3224×224×3,而应该是227×227×3227×227×3,大家可以用244的尺寸推导下,会发现边界填充的结果是小数,这显然是不对的,在这里就不做推导了。
输入层:227×227×3
C1:96×11×11×3 (卷积核个数/宽/高/厚度)
C2:256×5×5×48(卷积核个数/宽/高/厚度)
C3:384×3×3×256(卷积核个数/宽/高/厚度)
C4:384×3×3×192(卷积核个数/宽/高/厚度)
C5:256×3×3×192(卷积核个数/宽/高/厚度)
针对这五层卷积,说明一下三点:
1.推导下C1后的输出是什么:
用11×11×3的卷积核卷积227×227×3的图像,卷积后的尺寸是55×55×1。这是因为:
卷积核的个数为96,但是48个在一张显卡上,剩余48个在另一张显卡上。所以单张显卡上的通道数为48,2为显卡个数。
最后的输出:55×55×48×2
而剩下的层数与上述推导式相同的,我们可以逐层确定输出是什么。
2.注意推到过程中的池化操作
在C1,C2,C5的卷积操作后,图像做了最大池化(后面会说),这会影响输出图片的尺寸。
3.C3卷积层的特殊性

池化层与激活层
严格上说池化层与卷积层不属于CNN中的单独的层,也不记入CNN的层数内,所以我们一般直说AlexNet一共8层,有5层卷积层与3层全连接层。但是在这里为了逻辑上清晰,就把他们单独拿出来说明下:
池化层
池化操作(Pooling)用于卷积操作之后,其作用在于特征融合和降维,其实也是一种类似卷积的操作,只是池化层的所有参数都是超参数,都是不用学习得到的。 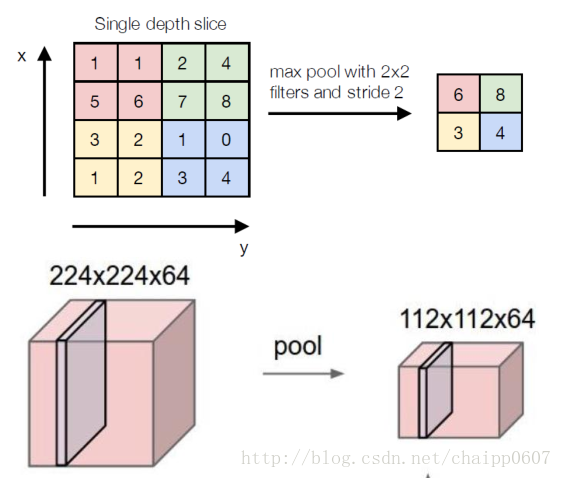
上面这张图解释了最大池化(Max Pooling)的操作过程,核的尺寸为2×2,步长为2,最大池化的过程是将2×2尺寸内的所有像素值取最大值,作为输出通道的像素值。
除了最大池化外,还有平均池化(Average Pooling),也就是将取最大改为取平均。
一个输入为224×224×64的图像,经过最大池化后的尺寸变为112×112×64,可以看到池化操作的降维改变的是图像的宽高,而不改变通道数。
激活层
池化操作用于卷积层内,而激活操作则在卷积层和全连接层都会用到,由于之前我已经写过关于激活函数的博客,在这里只简单说明下,具体内容大家可以在 理解激活函数在神经网络模型构建中的作用这个博客中了解。
深层网络中一般使用ReLU多段线性函数作为激活函数,如下图所示,其作用在于增加非线性。 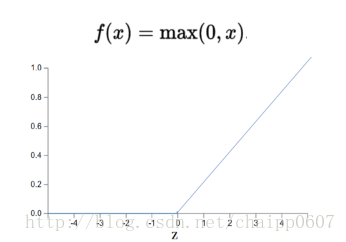
在全连接层中的激活过程就很好理解了,因为全连接层内所有的神经元的输出都是一个数,只要这个数x>0,则x=x;x<0,则x=0。
在卷积层中的激活针对的是每一个像素值,比如某卷积层输出中某个通道中i行j列像素值为x,只要这个数x>0,则x=x;x<0,则x=0。
全连接层
全连接层的作用
CNN中的全连接层与浅层神经网络中的作用是一样的,负责逻辑推断,所有的参数都需要学习得到。有一点区别在于第一层的全连接层用于链接卷积层的输出,它还有一个作用是去除空间信息(通道数),是一种将三维矩阵变成向量的过程(一种全卷积操作),其操作如下: 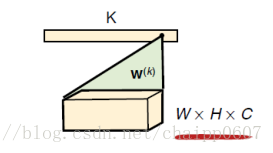
输入图像是W×H×C,那么卷积核的尺寸为W×H×C,这样的话整个输入图像就变成了一个数,一共有k个数(第一层全连接层后的神经元个数),就有K个这样的W×H×C的卷积核。所以全连接层(尤其是第一层)的参数量是非常可怕的,也是由于这个弊端,后来的网络将全连接取消了,这个有机会再说。
AlexNet中的全连接层
再回到AlexNet结构,R1,R2,R3就是全连接层。R2,R3很好理解,在这里主要说明下R1层:
输入图像:13×13×256
卷积核尺寸:13×13×256 个数2048×2
输出尺寸:4096(列向量)
从最开始的结构中可以看到,R1中也有通道的交互: 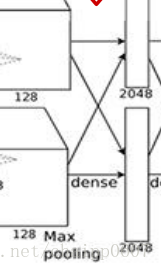
所以串接后的通道数是256,全卷积的卷积核尺寸也就是13×13×256,一个有4096个这样尺寸的卷积核分别对输入图像做4096次的全卷积操作,最后的结果就是一个列向量,一共有4096个数。这些数的排布其实就相当于传统神经网了里面的第一个隐藏层而已,通过R1后,后面的链接方式和ANN就没有区别了。要学习的参数也从卷积核参数变成了全连接中的权系数。
Softmax层
Softmax作用
Softmax层也不属于CNN中单独的层,一般要用CNN做分类的话,我们习惯的方式是将神经元的输出变成概率的形式,Softmax就是做这个的: 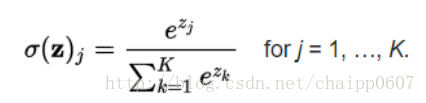
这个很好理解,显然Softmax层所有的输出相加为1。即: 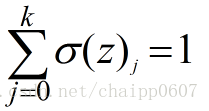
而某一个输出的就是概率,最后我们按照这个概率的大小确定到底属于哪一类。
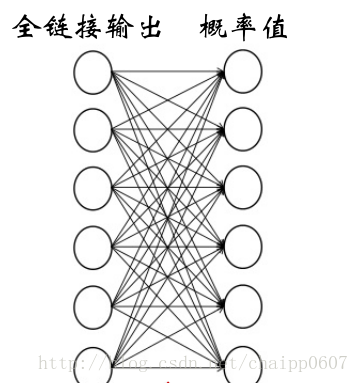
AlexNet中的Softmax
AlexNet最后的分类数目为1000,也就是最后的输出为1000,输入为4096,中间通过R3链接,R3就是最后一层了,全连接的第3层,所有层数的第8层。
AlexNet为啥取得比较好的结果呢?
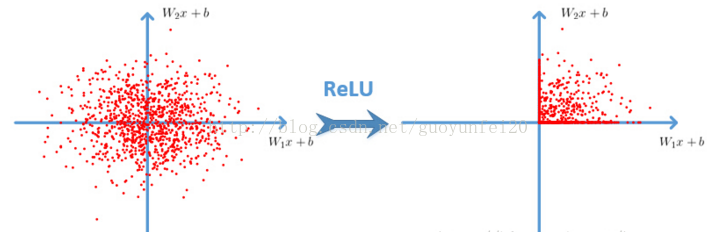
1. 使用了Relu激活函数。
Relu函数:f(x)=max(0,x)
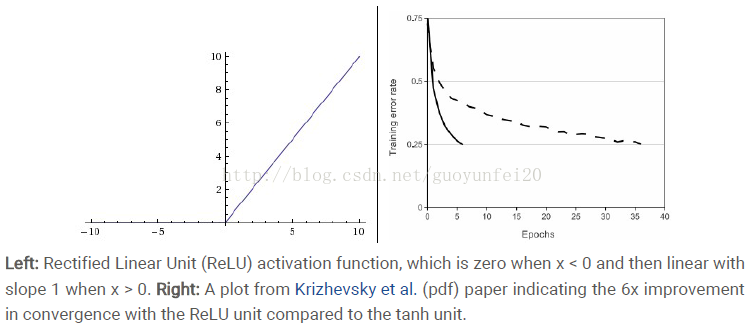
基于ReLU的深度卷积网络比基于tanh和sigmoid的网络训练快数倍,下图是一个基于CIFAR-10的四层卷积网络在tanh和ReLU达到25%的training error的迭代次数:
2. 归一化(Local Response Normalization)
使用ReLU f(x)=max(0,x)后,你会发现激活函数之后的值没有了tanh、sigmoid函数那样有一个值域区间,所以一般在ReLU之后会做一个normalization,LRU就是稳重提出(这里不确定,应该是提出?)一种方法,在神经科学中有个概念叫“Lateral inhibition”,讲的是活跃的神经元对它周边神经元的影响。
ReLU本来是不需要对输入进行标准化,但本文发现进行局部标准化能提高性能。
其中a代表在feature map中第i个卷积核(x,y)坐标经过了ReLU激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
这种归一化操作实现了某种形式的横向抑制,这也是受真实神经元的某种行为启发。
卷积核矩阵的排序是随机任意,并且在训练之前就已经决定好顺序。这种LPN形成了一种横向抑制机制
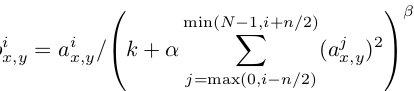
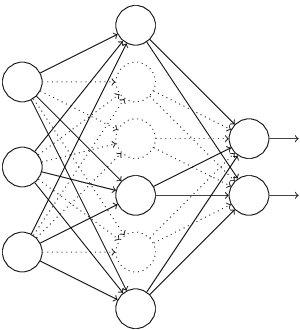
3. Dropout
Dropout也是经常说的一个概念,能够比较有效地防止神经网络的过拟合。 相对于一般如线性模型使用正则的方法来防止模型过拟合,而在神经网络中Dropout通过修改神经网络本身结构来实现。对于某一层神经元,通过定义的概率来随机删除一些神经元,同时保持输入层与输出层神经元的个人不变,然后按照神经网络的学习方法进行参数更新,下一次迭代中,重新随机删除一些神经元,直至训练结束。
4. 数据增强(data augmentation)
在深度学习中,当数据量不够大时候,一般有4解决方法:
>> data augmentation——人工增加训练集的大小——通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据
AlexNet用到的第一种数据增益的方法:是原图片大小为256*256中随机的提取224*224的图片,以及他们水平方向的映像。
第二种数据增益的方法就是在图像中每个像素的R、G、B值上分别加上一个数,用到 方法为PCA。对于图像每个像素,增加以下量 :
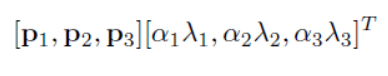
p是主成分,lamda是特征值,alpha是N(0,0.1)高斯分布中采样得到的随机值。此方案名义上得到自然图像的重要特性,也就是说,目标是不随着光照强度和颜色而改变的。此方法降低top-1错误率1%。
>> Regularization——数据量比较小会导致模型过拟合, 使得训练误差很小而测试误差特别大. 通过在Loss Function 后面加上正则项可以抑制过拟合的产生. 缺点是引入了一个需要手动调整的hyper-parameter。
>> Dropout——也是一种正则化手段. 不过跟以上不同的是它通过随机将部分神经元的输出置零来实现
>> Unsupervised Pre-training——用Auto-Encoder或者RBM的卷积形式一层一层地做无监督预训练, 最后加上分类层做有监督的Fine-Tuning
代码实现:简化版本
# -*- coding=UTF-8 -*- import sys import os import random import cv2 import math import time import numpy as np import tensorflow as tf import linecache import string import skimage import imageio # 输入数据 import input_data mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) # 定义网络超参数 learning_rate = 0.001 training_iters = 200000 batch_size = 64 display_step = 20 # 定义网络参数 n_input = 784 # 输入的维度 n_classes = 10 # 标签的维度 dropout = 0.8 # Dropout 的概率 # 占位符输入 x = tf.placeholder(tf.types.float32, [None, n_input]) y = tf.placeholder(tf.types.float32, [None, n_classes]) keep_prob = tf.placeholder(tf.types.float32) # 卷积操作 def conv2d(name, l_input, w, b): return tf.nn.relu(tf.nn.bias_add( tf.nn.conv2d(l_input, w, strides=[1, 1, 1, 1], padding='SAME'),b) , name=name) # 最大下采样操作 def max_pool(name, l_input, k): return tf.nn.max_pool(l_input, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME', name=name) # 归一化操作 def norm(name, l_input, lsize=4): return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name) # 定义整个网络 def alex_net(_X, _weights, _biases, _dropout): _X = tf.reshape(_X, shape=[-1, 28, 28, 1]) # 向量转为矩阵 # 卷积层 conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1']) # 下采样层 pool1 = max_pool('pool1', conv1, k=2) # 归一化层 norm1 = norm('norm1', pool1, lsize=4) # Dropout norm1 = tf.nn.dropout(norm1, _dropout) # 卷积 conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2']) # 下采样 pool2 = max_pool('pool2', conv2, k=2) # 归一化 norm2 = norm('norm2', pool2, lsize=4) # Dropout norm2 = tf.nn.dropout(norm2, _dropout) # 卷积 conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3']) # 下采样 pool3 = max_pool('pool3', conv3, k=2) # 归一化 norm3 = norm('norm3', pool3, lsize=4) # Dropout norm3 = tf.nn.dropout(norm3, _dropout) # 全连接层,先把特征图转为向量 dense1 = tf.reshape(norm3, [-1, _weights['wd1'].get_shape().as_list()[0]]) dense1 = tf.nn.relu(tf.matmul(dense1, _weights['wd1']) + _biases['bd1'], name='fc1') # 全连接层 dense2 = tf.nn.relu(tf.matmul(dense1, _weights['wd2']) + _biases['bd2'], name='fc2') # Relu activation # 网络输出层 out = tf.matmul(dense2, _weights['out']) + _biases['out'] return out # 存储所有的网络参数 weights = { 'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])), 'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])), 'wc3': tf.Variable(tf.random_normal([3, 3, 128, 256])), 'wd1': tf.Variable(tf.random_normal([4*4*256, 1024])), 'wd2': tf.Variable(tf.random_normal([1024, 1024])), 'out': tf.Variable(tf.random_normal([1024, 10])) } biases = { 'bc1': tf.Variable(tf.random_normal([64])), 'bc2': tf.Variable(tf.random_normal([128])), 'bc3': tf.Variable(tf.random_normal([256])), 'bd1': tf.Variable(tf.random_normal([1024])), 'bd2': tf.Variable(tf.random_normal([1024])), 'out': tf.Variable(tf.random_normal([n_classes])) } # 构建模型 pred = alex_net(x, weights, biases, keep_prob) # 定义损失函数和学习步骤 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # 测试网络 correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # 初始化所有的共享变量 init = tf.initialize_all_variables() # 开启一个训练 with tf.Session() as sess: sess.run(init) step = 1 # Keep training until reach max iterations while step * batch_size < training_iters: batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 获取批数据 sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys, keep_prob: dropout}) if step % display_step == 0: # 计算精度 acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.}) # 计算损失值 loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.}) print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc) step += 1 print "Optimization Finished!" # 计算测试精度 print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images[:256], y: mnist.test.labels[:256], keep_prob: 1.})
本文仅用于学习研究,非商业用途,欢迎大家指出错误一起学习,作者:十岁的小男孩
本文参考了以下地址的讲解,万分感谢,如有侵权,请联系我会尽快删除,929994365@qq.com:
https://blog.csdn.net/guoyunfei20/article/details/78122504
https://blog.csdn.net/chaipp0607/article/details/72847422