十岁的小男孩
本文为终端移植的一个小章节。
目录
背景
理论
实践
Quantize
背景
Neural Network模型一般都会占用很大的磁盘空间,比如AlexNet的模型文件就超过了200 MB.模型包含了数百万的参数,绝大部分的空间都用来存储这些模型的参数了。这些参数是浮点数类型的,普通的压缩算法很难压缩它们的空间。
一般模型的内部的计算都采用了浮点数计算,浮点数的计算会消耗比较大的计算资源(空间和cpu/gpu时间),如果在不影响模型准确率的情况下,模型内部可以采用其他简单数值类型进行计算的话,计算速度会提高很多,消耗的计算资源会大大减小,尤其是对于移动设备来说,这点尤其重要。由此引入量化技术。
量化即通过减少表示每个权重所需的比特数来压缩原始网络。
理论
对量化的实现是通过把常见操作转换为等价的八位版本达到的。涉及的操作包括卷积,矩阵乘法,激活函数,池化操作,以及拼接。对模型可以压缩到1/4。
我们发现模型属于同一层的参数值会分布在一个较小的区间内,比如-10, 30之间,我们可以记下这个最小值和最大值,在采用8位数量化(可以有其他选择)的情况下,可以把同一层的所有参数都线性映射(也可以采用非线性映射进一步压缩空间)到区间[-10, 30]之间的255个8位整数中的最接近的一个数,例如如下映射:
Quantized | Float --------- | ----- 0 | -10.0 255 | 30.0 128 | 10.0
这样模型文件的大小就基本压缩到了原来的25%,而且在加载的时候可以恢复到原来的数值,当然恢复的数值跟压缩之前会有差异,但事实证明,模型对这种压缩造成的噪音表现的很健壮。
满足第一个需求就这么简单,模型不需要改变,需要改变的是模型的存储和加载部分;但是要解决第二个问题就不这么简单了,事实证明,模型内部的计算如果都采用8位整形数来计算的话,模型的表现会相差很大,原因是模型的训练过程中,需要计算梯度,然后运用一定的学习算法,不断的更新参数,每次的更新量可能是很小的。所以模型的训练过程需要高精度的浮点型数值的。那么模型的预测过程是否可以使用整形数值代替呢?事实证明是可行的。
TensorFlow中模型的量化过程是这样实现的:
将模型中实现了对应的量化操作的操作符替换成量化操作符,经过转换后,输入输出依旧是float,将input从浮点数转换成8 bit,只不过中间的计算是用过8 bit来计算的。
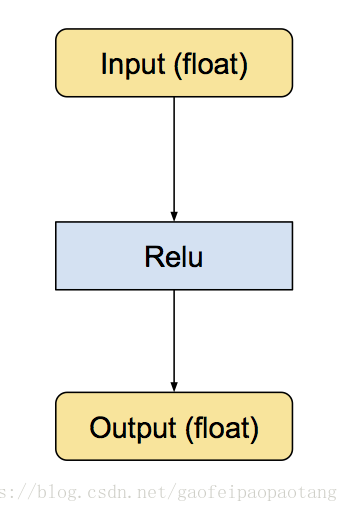
图1 原始的计算图
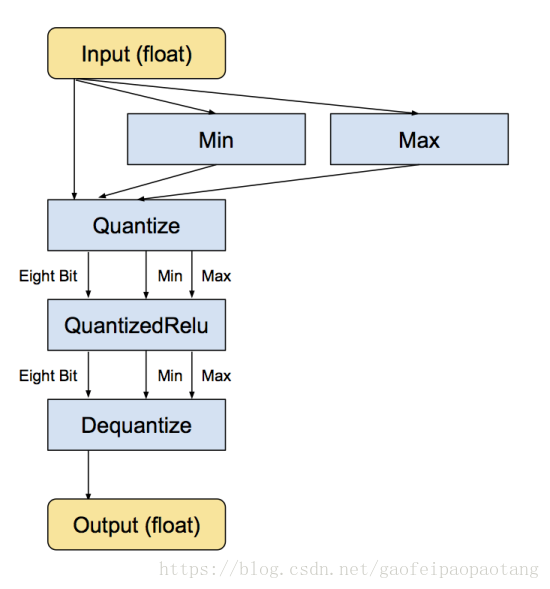
图2 量化后的计算图
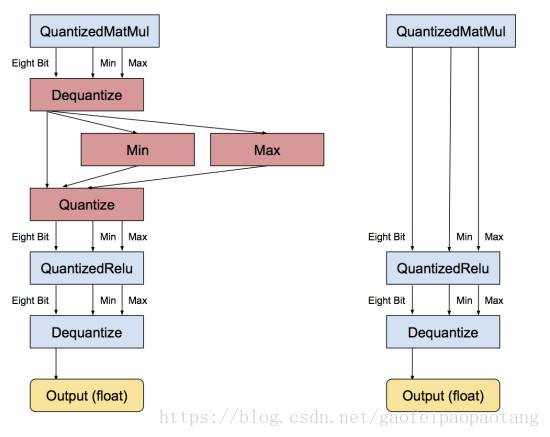
图3 优化量化处理后的计算图,去掉冗余操作
Quantize:
quantize取input中的min和max,分别对应被量化的input中的最小值(0)和最大值(255),把[min, max]这个区间均匀分成255个小区间,把input中的值对应到对应的区间中。
Dequantize:
反量化操作则是把上述操作反向执行。
之所以这么做,tensorflow的论述是:
1. 权重、活化张量的数值通常分布在一个相对较小的范围中(weight:-15 ~ 15,activatios:-500 ~ 1000);
2. 神经网络对噪音的适应性强,将数量化到一个更小的数集中并不会对整体的结果带来很大的影响;
3. 通过量化操作,可以有效提高点乘的计算效率。
实践
使用TensorFlow工具进行量化压缩
在使用tensorflow这个功能时候需要先下载tensorflow的源代码:
git clone https://github.com/tensorflow/tensorflow.git
进入tensorflow根目录,这里使用tools文件下的两个工具进行量化压缩:graph_transforms、quantization。
安装bazel进行tensorflow工具包的编译。
这里需要注意的是,bazel最好使用最新的,这样编译tensorflow就不会报接口未部署的一些错误。
Linux安装bazel:
https://github.com/bazelbuild/bazel/release
找到bazel-x.x.x-installer-linux-x86_64.sh下载到本地并安装。可以按照git的安装方法进行安装。
安装完毕后开始进行编译tensorflow:
bazel build tensorflow/tools/graph_transforms:transform_graph
bazel build tensorflow/tools/quantization:quantize_graph
编译需要占据很多内存以及cpu资源,建议在性能好点的机器上编译。
编译完成后使用:
pb_in=$pb_path pb_out=$pb_path_out graph_trans=tensorflow/bazel-bin/tensorflow/tools/graph_transforms/transform_graph $graph_trans --in_graph=$pb_in --out_graph=$pb_in --inputs='input_data' --outputs='softmax' --transforms=' add_default_attributes fold_constants(ignore_errors=true) fold_batch_norms fold_old_batch_norms quantize_weights quantize_nodes strip_unused_nodes sort_by_execution_order'
对于第二个工具quantize_graph。
bazel-bin/tensorflow/tools/quantization/quantize_graph --input=input.pb --output_node_names="softmax2" --print_nodes --output=out.pb --mode=eightbit --logtostderr
参考文献:
https://blog.csdn.net/xygl2009/article/details/80596392?utm_source=blogxgwz1
https://blog.csdn.net/andeyeluguo/article/details/80898142?utm_source=blogxgwz0
https://blog.csdn.net/shuzfan/article/details/51678499?utm_source=blogxgwz1
https://petewarden.com/2016/05/03/how-to-quantize-neural-networks-with-tensorflow/