第三章 存储器的层次结构
3.1 存储器分类
-
按存储介质分类
(1)半导体存储器:
TTL,MOS,SSD。
易失
(2)磁表面存储器:
磁头,载磁体
非易失
(3)磁芯存储器:
硬磁材料,环状元件
非易失
(4)光盘存储器:
激光,慈光
非易失 -
按存取方式
(1)存取时间与物理地址无关 (随机存取)
类比于数据结构中的线性表数组(取数组某个元素的时间和物理地址无关,只和index有关)
(a)随机存储器:程序执行过程中可读可写
(b)只读存储器:程序执行过程中只读
(2)存取时间与物理地址有关(串行访问)
类比于数据结构中的链表
(a)顺序存取存储器:磁带
(b)直接存取存储器:磁盘(根据物理地址,直接移动磁头) -
按在计算机中的作用分类
(1)主存
(a)RAM:操作系统被加载到RAM
SRAM:(Static Random Access Memory)静态随机存储器。常用制作二级缓存。
不必刷新电路就能保存数据。但体积大,集成度低
DRAM:(Dynamic Random Access Memory)动态随机存取存储器。常用语制作系统内存
DRAM用电容存储数据,需要定时充电,刷新电路,否则出处的数据丢失。集成度高
(b)ROM:存储机器自检和引导程序,BIOS等程序
MROM:(Mask Read-Only Memory)掩模式只读存储器。MROM的内容在出厂前一次写入,之后不能更改
PROM:(Programmable Read-Only Memory)-可编程只读存储器。只能写入一次数据的只读存储器,写入错误只能更换存储芯片
EPROM:(Erasable Programmable Read Only Memory)可擦除可编程只读寄存器
EEPROM: (Electrically Erasable Programmable Read-Only Memory),电可擦可编程只读存储器。SSD
(2)辅存
磁盘,磁带,光盘
3.2 存储器的存储结构
-
存储结构综述
(1)cpu只能和主存,cache进行数据交互,而不能直接获得辅存的数据
(2)辅存的数据只能调入主存,不能直接进入缓存中。
(3)辅存到主存的映射是由OS操作系统管理的。但是主存和辅存之间的一个映射关系被放到TLB中,TLB在cache中。
(4)虚拟存储中的页表,段表,段页表被放到了主存中。cpu通过页表访问辅存时,发现缺页中断,就会先暂停程序的执行,先把数据调到内存 -
主存
(1)主存的基本结构
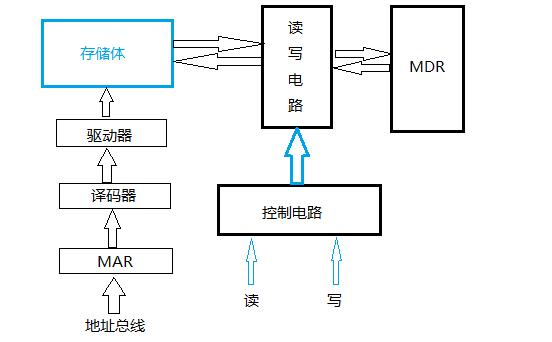
(2)主存和CPU的联系
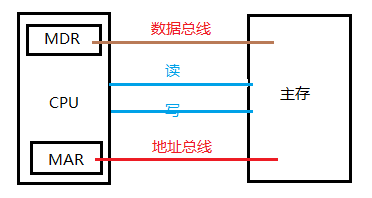
-
主存中存储单元地址的分配
(1)寻址的个数有2个因素:
(a)地址线的个数:这是内存中总的可寻址字节数
(b)一个地址所占用的字节数:表明了一个内存单元,占用多少个字节
(2)(frac{内存可寻址的总字节数}{多少字节形成一个内存单元} = 可寻址数)
(3)eg:地址线24根,按字节寻址,可寻址(2^24 = 16M)个
若字长为16位,按字寻址,可寻址8M个
若字长为32位,按字寻址,可寻址4M个 -
主存的指标
(1)存储容量:存放二进制代码的总位数
(2)存取速度:
存取时间:存储器的访问时间(读出时间,写入时间)
存取周期:连续两次独立的读写存储器操作之间,最小的时间间隔。用于读电路,写电路,地址电路清空一次
(3)存储器带宽 (位/秒) -
半导体存储片的基本结构
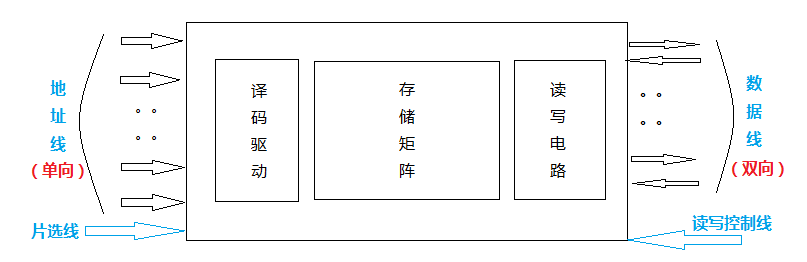
(1)地址线单向,数据线双向。
(2)半导体芯片的容量由地址线和数据线一起决定。
地址线和数据线的根数表示了内存实际的大小,而cpu理论上的最大寻址范围,由MAR和MDR的大小决定,为(2^{MAR}*MDR)地址线 数据线 芯片容量 10根 4根 (2^{10} * 4)bit 14根 1根 (2^{14} * 1)bit
(3)片选线的作用
eg:用16K*1位的存储芯片组成64K*8位的存储器
(a)因为半导体芯片是用存储矩阵设计的,存储矩阵的一行可以看成一层楼,这层楼有多个小房间。
因此,先把8个16*1K的存储器放在一行,构成一层楼。再安排4层这样的楼层,构成64K*8的大楼
(b)因为,一个地址线的地址过来后,先通过片选线(地址为的最高几位),选择楼层,
然后用剩下的地址线低位地址,选择是楼层的那个房间
(c)eg:当上例子中,地址线过来的数据是65535,转换成二进制是1111 1111。
上面楼层有4层,所以地址线的前两位进行片选,也就是11,因此选择最高层。
- 半导体存储芯片的译码方式:
(1)线选法:每个小存储单元占用一行,构成多行的线性结构
每个小存储单元占用一行,构成多行的线性结构
eg:16*1 bit的存储矩阵,占16行,因为要选择16行,所以要有4位片选线,链接所有的16个存储单元。
这种设计导致电路设计异常复杂。
(2)重合法 : 组合多个存储单元为一行:
通过组合多个存储单元为一行,来减少行数,达到减少片选线位数的目的,简化电路设计。但此时的存储矩阵,每行有多列存储单元,因此,用X地址译码器(确定行),用Y地址译码器(确定列),来选到具体的某个存储单元。
eg:256 * 1bit重合片选法:把8个bit存储单元作为一行,设计32行即可。
因为有32行,因此X地址译码器有5位,因为有8列,因此Y地址译码器有3位
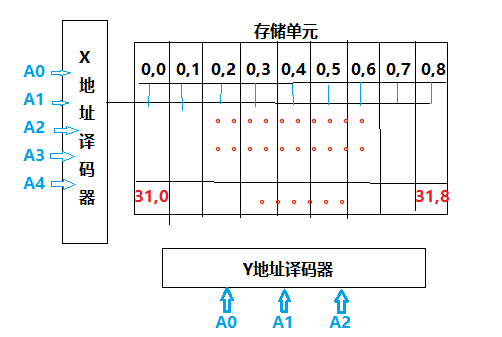
3.3 半导体随机存储器
-
SRAM
(1)SRAM:静态随机存储器,不用刷新电路,使用双稳态管存储数据,不掉电情况下数据存在。
(2)SRAM基本电路 -
DRAM
(1)DRAM:动态随机存储器,定时刷新电路,使用电容存储数据,不掉电情况下也需要定时对电容充电。
(2)DRAM的存储矩阵是二维的,有行有列。所以要对行和列进行片选。行列片选的片选片进行复用,即同一个针脚,先选择行,后选择列。
(3)动态RAM刷新 (刷新与行地址有关:默认数据能保持2ms)
(a)集中刷新(存取周期0.5(mu s))
集中刷新是一次刷新存储矩阵中所有的存储单元。即,在数据能保持的这2ms内,分为能读写的周期时间,和不能读写的电路刷新时间。这个刷新时间,也称为"死区“。电路刷新,一次刷新存储矩阵的1行,这个刷新一行的时间等于一个存取周期
eg:当存储矩阵为128*128,存取周期为0.5(mu s)时,刷新时间=128 * 0.5 = 64(mu s),即死区时间占64(mu s),其死区时间率为(frac{64}{2000} = 3.2%)
(b)分散刷新(存取周期为1(mu s))
分散刷新是,在每次读写数据后,立刻刷新改行存储矩阵。即一个存取周期=读写时间+电路刷新时间。而读写时间等于电路刷新时间,所以,1个存取周期等于2个读写时间,为2*0.5=1(mu s)。
分散刷新不存在死区,但是使得一次存取时间变成原来的2倍
(c)异步刷新
异步刷新不在一次刷新所有行,也不再每次读写后立刻刷新,而是保证在2ms内,每一行得到刷新即可。所以其死区时间为0.5(mu s)。如果将刷新安排在指令译码阶段,则不会有死区时间(指令译码阶段,不产生cpu去内存的io)
eg:对于128*128的存储矩阵,把2ms平均到每行为2/128=15.6(mu s),即每隔15.6(mu s)顺着存储矩阵的行编号,向下个编号刷新。
3.4 主存与CPU的连接
-
存储容量的扩展
(1)位扩展
用2片1K*4位存储芯片组成1K*8位存储器
位扩展没有增加房间号,只是房间里面多住人了。即地址线不变,增加数据线,其他没变化
(2)字扩展(增加存储字的数量)
用1K*8位存储芯片组成2K*8位的存储器:原来的1K字即10根地址线,变成现在的2K即11根地址线,多出来的1根地址线用来进行片选。
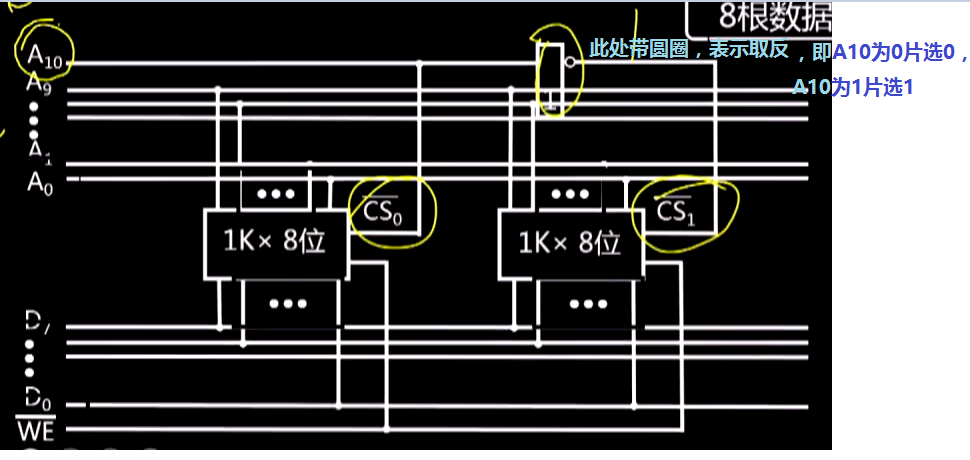
(3)字位扩展
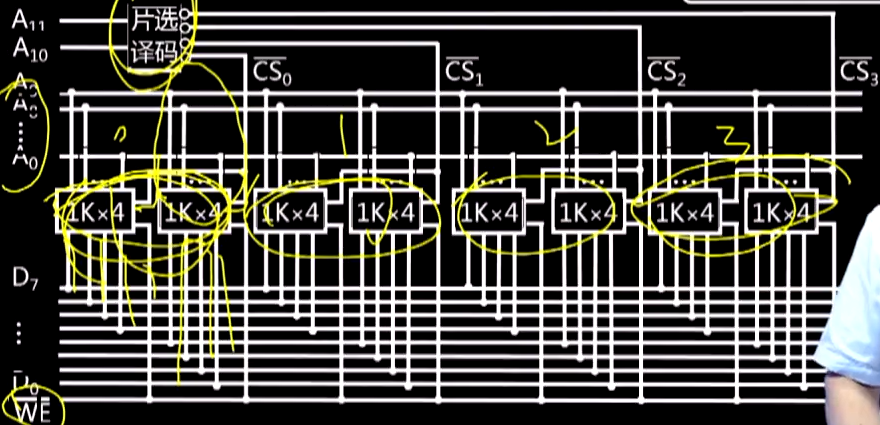
用8片1K*4位的存储芯片组成4K*8位的存储器。即地址线先扩展4位成(D_0到D_7),然后地址线由原来的10根扩展成12根,新增的2根进行限片选,一次选择2个芯片。此时的片选线变成片选译码器
-
存储器与CPU的连接
(1)地址线的连接:先连接芯片固有的
(2)数据线的连接:先连接芯片固有的
(3)读写控制线的连接:每个芯片都要连接,包括增加的
(4)片选线的连接:用增加的地址线进行片选线
(5)芯片选择:选择芯片数量组少的解决方案
eg:设CPU有16根地址线,8根数据线。现有以下几种存储芯片:1K*4位RAM,4K*8位RAM,8K*8位RAM,
2K*8位ROM,4K*8位ROM,8K*8位ROM,和74138译码器。请画出CPU和存储器的连接图。要求:
主存地质分配如下:6000H67FFH为系统程序区。6800H6BFFH为用户程序区。
(1) 写出地址对应的二进制码
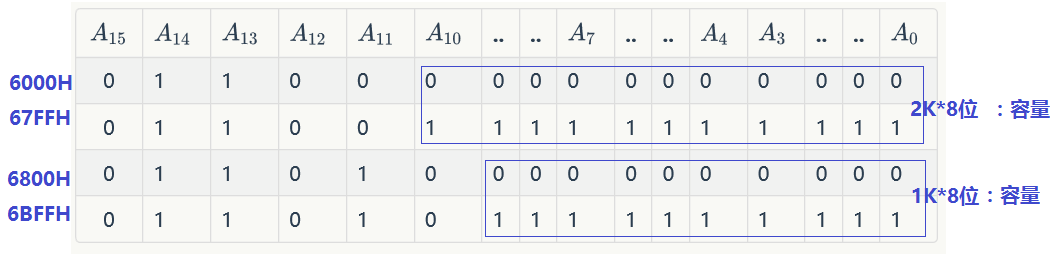
所谓系统存储区,指的是单片机中存储系统程序的那部分芯片,通常被烧制在ROM里,而用户程序是单片机中跑的程序,运行在RAM中。如上图所示,应该选择1片2K*8位ROM,和2片1K*4位RAM。
(2)分配地址线:
(A_{0}~A_{10})地址线连接ROM,
(A_{0}~A_{9})地址线连接RAM
(3)确定片选片信号
如上图,只有1片ROM,而且2片RAM是位扩展,不会引起片选,所以只要区分RAM和ROM即可。如图发现,(A_{12},A_{11},A_{10})即可区分ROM和RAM.因此这3位地址线成为片选线。
3.5 双口RAM和多模块存储器 -- 提高访存速度的手段
-
单体多字系统
(1)把原来的单字长寄存器改变为多字长的寄存器,使得内存一次可以读出多个字。从而增加访存速度
(2)这种设计实际上不存在,因为多字长在跳转指令时会产生顺序读取的数据无效,降低效率 -
双口RAM
(1)双口RAM是含有两套相互独立的读写控制电路而得名。同时进行2次独立的读写操作,所以会增加存储器
(2)当两套读写电路同时操作同一块内存地址时,会产生写冲突。因此,增加一个busy标志(低电平) -
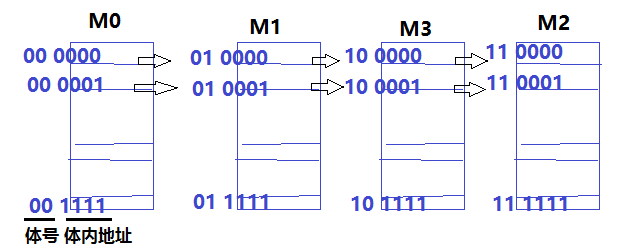
多体并行 - 高位交叉,顺序编址
(1)多体并行是编址方式的一种转变。存储矩阵有多个行,每个行成为一个体。
(2)高位交叉编址的意思是:用地址的高位表示是哪个体。所以4体高位交叉编址就变成了高位分别为00,01,10,11$,低位作为体内地址。因此形成顺序编址。
-
多体并行 - 低位交叉编址,各体轮流编址
(1)低位为体号,高位为体内地址。正好使得连续地址分布在不同的体
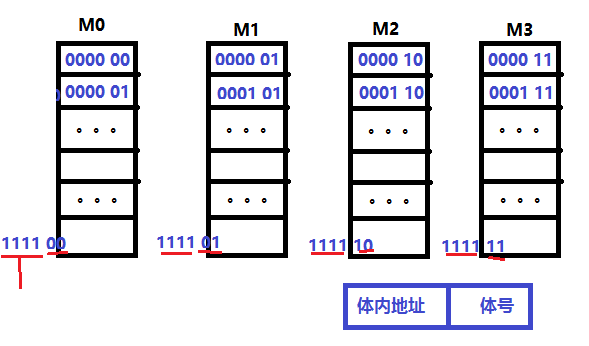
(2)低位交叉编制,使得读取连续地址的数据时,采用流水线方式:
流水线为2步,分为通知体传输和体传输时间。
通知体的时间为cpu发出信号到体的时间,即总线传输时间。体传输时间为体读取数据的时间。
为了使流水线可以对齐,要求1个存取周期内,正好通知到所有体,所以存取周期为体数的整数倍。
eg:设4体交叉存储器,存取周期为T,总线传输周期为( au),则为实现流水线存取方式,应满足(T = 4 au)。因为每个体的存取周期为n( au),最后一个体用一个( au)的时间在T内,所以总的传输时间为T+(n-1)( au)

-
高性能存储芯片
(1)SDRAM(同步DRAM):系统时钟控制下进行读出和写入,CPU无需等待
(2)RDRAM:由Rambus开发,解决存储器带宽问题
(3)带cache的DRAM:在DRAM的芯片中集成了一个由SRAM组成的cache
3.6 高速缓冲存储器Cache
-
cache工作原理
(1)主存单位称为块,cache称为行,实质是一个东西
(2)CPU读主存时,把地址同时送给cache和主存,cache通过地址查看此字是否在cache中,若在则立即传送给cpu。
若不在,则用主存读周期把此字从主存中读出送到cpu,与此同时,把含有此字的整个数据块从主存读出送到cache的行中 -
Cache层次结构
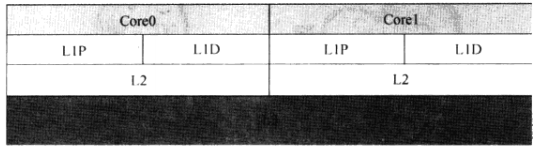
(1)cache是分层次的:L1 cache,L2 cache,L3 cache。
(2)寄存器取值时,先从L1取,去不到则向下层的L2 cache取,L2再取不到,去内存取。
(3)每个核心享有独自的L1 cache和L2 cache,所有核心共享L3 cache。 L1,L2cache是片内cache
(4)L1 cache分为L1P和L1D,分开存储指令和数据。使指令和数据可以同时读取
-
cache与内存的映射关系(读方式)
(1)全关联:full associative cache
将内存也看成line的方式存储,全关联是指,内存的任意一个line可以映射到cache中的任意一个line。
全相连映射的主存地址分为2部分:主存块号|字块内地址;cache标记位为主存地址除了字块内地址的全部高位。
这就需要一个表,记录主存块号到cache行号的映射
这种方式,在查找内存是否在cache中时,要查找所有的tag。 而且查表的比较器很难实现
(2)直接映射:Direct Associated Cache
将内存按照cache大小划分为n个Page,内存中Page的line0对应cache的line0。因此直接映射下,cache标志位标志的是内存的page号。
另一种理解方式:主存中的几个特定行,映射到cache的一个特定行。多对一的关系。这种关系满足公式 i = j mod c
其中,i:cache行的行号。j:主存块的块号。c:cache的行数。标志位=j/c向下取整
直接映射相当于多体高位交叉顺序编址。体相当于整个cache,主存包含多个体。采用顺序编址,使得主存地质分成三部分: 体号(第几个cache)|cache块号|块内地质。所以cache把主存中的最高几位(cache体号)作为标记位
当恰好访问的几个主存地质,映射到了相同的cache行,就会产生抖动
(3)组相联:Set Associated Cache
i. 组相联映射把cache划分为过个way,每个way的结构一样。内存按照way的大小划分Page,page间采用直接映射方式,page内采用全相联映射方式 。
即:page号到组号的映射关系是多对一且固定的。
u为cache的way个数,v为way中的行数 。 v路组相联:把几行作为一个way
这种方式,把主存地址分为3部分:主存自块标记|组内地址(不用有way号,因为是映射出来的)|字内地址。分别对应cache的标记位,way内的行号
ii. c64+DSP的配置中,L1P使用1个way,L1D使用2个way,L2不区分程序和数据,使用4个cache way
eg:假设主存的容量为512K*16位,cache容量为4096*16位,块长为4个16位字,访存地址为字地址。
(1)直接映射下,设计主存地址格式:
解:直接映射是主存的每块映射到cache的固定块。所以,主存地址应包含cache块号的标记。
因为按字编址,每个字为16位,所以主存地址容量为(2^{19}),cache容量为(2^{12})。所以主存地址为19位,cache地址为12位。因为每块4个字,所以快内地质占2位。cache块号占10位,主存地址的剩余7位为标记位
tag为(7) | cache块号(10) | cache快内地址(2)
(2)全相连方式下,主存地址的设计
解:全相联方式下,主存任意一块可以映射到cache任意一块,所以主存地址脂粉味2部分,tag和快内地址。
快内地址占2位,tag占17位
(3)二路组相联模式下,主存地址的设计
二路组相联模式下,每一个分组有2行,快内地址占1位,所以有(2^{12}/2/2=2^{9})个分组,所以组号占9位。剩下tag位占19-9-2=8位
二. cache的写方式
-
写通(Write through)
cpu在更新cache的内容时,会立刻更新对应的内存的值
写直通要同时写主存和cache,造成速度降低 -
写回(Write Back),line增加dirty
i. 在cache line的内容需要被置换时,先将修改过的值写会内存,再置换成新的line值
ii. 如何知道line被修改过呢,需要在line中增加一个dirty标志位,dirty为1,表示内存的内容被修改过,置换时需要写回内存
iii.LiP缓存程序,程序不会被修改,所以L1P没有dirty标志,而L1D缓存数据会被更改,所以有dirty标志位

三. cache一致性
-
多核cpu下的cache一致性问题
多核处理器中运行着不同的线程,当1个核心中的1个线程使修改一个内存地址的数据时,由于cache的写回策略,导致该核心中cache line的数据还没写回到对应内存。当另一个核心的进程也需要操作这个内存地址的数据时,从内存地址中读取的数据就是旧值。 -
cache一致性协议的2个硬件操作
(1)Write Invalidation:置无效
当一个核心的cache line更新了数据时,如果发现其他核心的cache line也存在对应内存地址数据的拷贝,则把其他核心的cache line的valid标志位置为无效
(2)Write Update:数据更新
当一个核心的cache line更新了数据时,如果发现其他核心的cache line也存在对应内存地址数据的拷贝,则更新其他核心的cache数据
Write Update设计复杂,会产生大量的数据更新操作,通常使用Write Invalidation -
cache一致性协议(Write Invalidation的实现:MESI)
(1)MESI协议包含4种状态
M:modify,该cache line数据有效,被更新过,和内存中不一致,数据只存在本cache中
E:Exlusive,该cache line数据有效,且和内存中一致,数据只存在本cache中
S:shared,该cache line数据有效,数据和内存中一致,数据存在多个核心的cache line中
I:invalid,此cache line数据无效
(2)cache snoop(窥探)
MESI协议中,每个core的cache控制器不仅可以知道自己cache的读写情况,同时也窥探其它core的cache的读写操作。每个cache line的数据状态在本core和其它core的读写状态之间进行变换。
(3)MESI的读写行为
i. Local Read:本core读本cache
ii. Local Write:本core写本cache
iii. Remote Read:其它core读其它cache
V. Remote Write:其它core写其它cache
(4)目录式的一致性协议
i. MESI协议需要snoop窥探,电路实现简单,但是cache line的沟通成本很高
ii. 有一种集中管理的目录式协议,将cache共享信息集中在一起,只有共享的cache line才会交互数据,减少沟通成本
3.7 虚拟存储器
一. 页式虚拟存储
-
概念
(1)程序员在比实际主存大得多的逻辑地址空间中编写程序
(2)程序执行时,把当前需要的程序段和数据块掉入主存,其他暂不使用的放在磁盘上
(3)执行指令时,通过硬件将逻辑地址转化为物理地址。虚拟地址高位为虚页号,低位为页内偏移地址
(4)当程序发生数据访问或程序访问失效(缺页时),由操作系统把信息从磁盘调入主存中 -
分页
(1)基本思想:
内存被分成固定长度且长度较小的存储块(页框,实页,物理页)
每个进程也被划分为固定长度的程序块(页,虚页,逻辑页)
通过页表,实现逻辑地址想物理地址的转化
(2)逻辑地址
程序中指令所使用的地址(进程所在地址空间)
(3)物理地址
存放指令或数据的实际内存地址 -
“主存-磁盘”层次
(1)与“cache-主存”层次相比,页大小远比cache的行大小要大(windows中的页位4k)
(2)采用全相联映射方式:磁盘中的任意一个页能用射到内存中的任意一个页
因为缺页导致中断时,操作系统从磁盘拿数据通常要耗费几百万个时钟周期。增大页大小,可以减少缺页中断
(3)为什么让软件处理“缺页”
因为访问磁盘需要好粉几百万个时钟周期,硬件即使能立刻把地址打给磁盘,磁盘也不能立即响应
(4)为什么地址转换用硬件实现
硬件实现地址转换可以加快指令的执行速度
(5)为什么页写会策略采用write back
避免频繁的慢速磁盘访问 -
页表结构
页表的首地址放在基址寄存器。采用基址寻址方式
每个页表项前面有一个虚页号:从0开始递增的序号。页表项又分为几个结构:
(1)装入位:该页是否在内存中
(2)修改位:该也在内存中是否被修改
(3)替换控制位:用于clock算法
(4)其他
(5)实页号(8进制) -
TLB
(1)一次磁盘引用需要访问几次主存?2次,一次查页表,一次查物理地址。于是,把经常查的页表放到cache中。这种在cache页表项组成的页表称为TLB(Translation Lookside Buffer)
(2)TLB的页表结构:tag + 主存中的页表项
当采用全相连映射时,tag为页表项前面的虚页号。需要把tag和虚页号一一比较
当采用组相联映射时,tag被分为tag+index,虚页号的高位为tag,虚页号的低位为index,做组内索引(属于组内第几行)
二. 段式虚拟存储
- 段式存储是根据程序逻辑,给程序分段。使得每段大小不同。这种虚拟地址划分方法适合程序设计
- 段式存储的虚拟地址由段号和段内偏移地址组成。段式虚拟存储器到物理地址的映射通过段表实现
- 段式虚拟存储会造成空页
三. 段页式虚拟存储
- 段页式虚拟存储,先把程序按照逻辑分成段,再把每段分成固定大小的页。
- 程序对主存的调入调出是按照页面进行的;但他有可以根据段实现共享和保护
- 缺点是段页式虚拟地址转换成物理地址需要查询2个表:段表和页表。段表找到相应页表的位置,页表找到想也页的位置
- 段页式细腻地址的结构可以为以下形式:
程序地址: 用户号(进程pid) | 段号 | 页号 | 页内偏移地址
eg:
(1)某计算机的cache块工16块,采用二路组相联映射方式,每个主存块大小为32字节,按照字节编制。则主存129号单元的主存块硬装如刀cache的组号是:(C)A、0 B、2 C、4 D、6
解:二路组相联,所以每组2块,共有16/2=8组,所以组号占3位。
每块32字节,所以块内地址占5位。
129转化为二进制:1000 0001:前3位为组号,100:=4
(2)假设用若干个2K*4位的芯片组成一个8K*8位的存储器,则地址0B1FH所在芯片的最小地址为:
解:用2片组成一行,共4行,所以片选地址占2位。片内地址有2k=(2^{11}),所以占11位
0B1FH:000|0 1|011 0001 1111 这三段为前缀,片选地址,片内地址。
该片芯片的最小地址是片内地址全0:000|0 1|000 0000 0000 = 0800H
(3)某计算机的主存地址空间大小为256MB,按字节编址,指令cache和数据cache分离,均有8个cache行,每行大小为64B,数据cache采用直接映射方式,现有两个程序A,B对数组int a[256][256]进行遍历,程序A按行遍历,程序B按列遍历。假定int类型数据用32位补码表示,数组a按行优先方式存储,其地址为320(十进制)。
问:(1) 若不考虑cache一致性维护和替换算法所需的控制位,则数据cache的总容量占多少?
(2) 数组元素a0和a[1][1]各自所在主存块对应的cache行号分别为多少(cache从0行开始)?
(3)程序A和B的数据访问命中率各自为多少?哪个程序的执行时间更短?
解:(1) 因为cache的总容量是cache每行的数据存储大小+tag位+数据是否有效位+其他一致性控制位。
主存地址空间256MB,占28位。直接映射方式,8行,行号占3位。每行64B,所以块内地址占6位,因此,tag占28-3-6=19位
每行有一个数据有效位。因此,cache共(19+1+64*8)*8 = 532字节
(2) 因为int类型占32位,所以一个int占4B。a0 = 320 + 31*4 = 444 a1 = 320 + 4*(256+1) = 1348。
块内地址占6位,直接映射下行号占3位,因此444 = 110 | 111100,所以行号为6
1348 = 10 | 101 | 000100,所以行号为5
(3) 因为1行cache占64B,每个int数占4B,所以一行有16个数。第一个数会因cache缺失而不命中,然后调入cache。,使得后面的15个int访问全部命中。所以命中率为(frac{15}{16}) 对于程序B,每次调入16个数,小于数组每行的128个元素,因此每次都不会命中,命中率为0